MeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
作者: Qiang Zhang, Jiahao Ma, Peiran Liu, Shuai Shi, Zeran Su, Zifan Wang, Jingkai Sun, Wei Cui, Jialin Yu, Gang Han, Wen Zhao, Pihai Sun, Kangning Yin, Jiaxu Wang, Jiahang Cao, Lingfeng Zhang, Hao Cheng, Xiaoshuai Hao, Yiding Ji, Junwei Liang, Jian Tang, Renjing Xu, Yijie Guo
分类: cs.RO, cs.AI
发布日期: 2026-02-17
备注: 17 pages, 6 figures
💡 一句话要点
MeshMimic:通过3D场景重建实现几何感知的类人运动学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 类人运动学习 3D场景重建 具身智能 运动重定向 强化学习
📋 核心要点
- 现有类人运动学习方法依赖昂贵的MoCap数据,且缺乏环境几何信息,导致运动与场景解耦,产生物理不一致。
- MeshMimic通过3D场景重建桥接运动与环境,从视频中学习耦合的运动-地形交互,实现几何感知的运动学习。
- 实验表明,MeshMimic在复杂地形上实现了稳健、高度动态的性能,验证了低成本单目传感器训练复杂交互的可行性。
📝 摘要(中文)
近年来,类人运动控制取得了显著突破,深度强化学习(RL)已成为实现复杂、类人行为的主要推动力。然而,类人机器人的高维度和复杂动力学使得手动运动设计不切实际,导致严重依赖昂贵的运动捕捉(MoCap)数据。这些数据集不仅获取成本高昂,而且常常缺乏周围物理环境的必要几何背景。因此,现有的运动合成框架通常存在运动与场景解耦的问题,导致在地形感知任务中出现接触滑动或网格穿透等物理不一致性。本文提出了MeshMimic,这是一个创新的框架,它将3D场景重建和具身智能相结合,使类人机器人能够直接从视频中学习耦合的“运动-地形”交互。通过利用最先进的3D视觉模型,我们的框架精确地分割和重建人类轨迹以及地形和物体的底层3D几何结构。我们引入了一种基于运动学一致性的优化算法,从嘈杂的视觉重建中提取高质量的运动数据,以及一种接触不变的重定向方法,将人与环境的交互特征转移到类人代理。实验结果表明,MeshMimic在各种具有挑战性的地形上实现了稳健、高度动态的性能。我们的方法证明,仅利用消费级单目传感器构建的低成本流程可以促进复杂物理交互的训练,为类人机器人在非结构化环境中自主进化提供了一条可扩展的路径。
🔬 方法详解
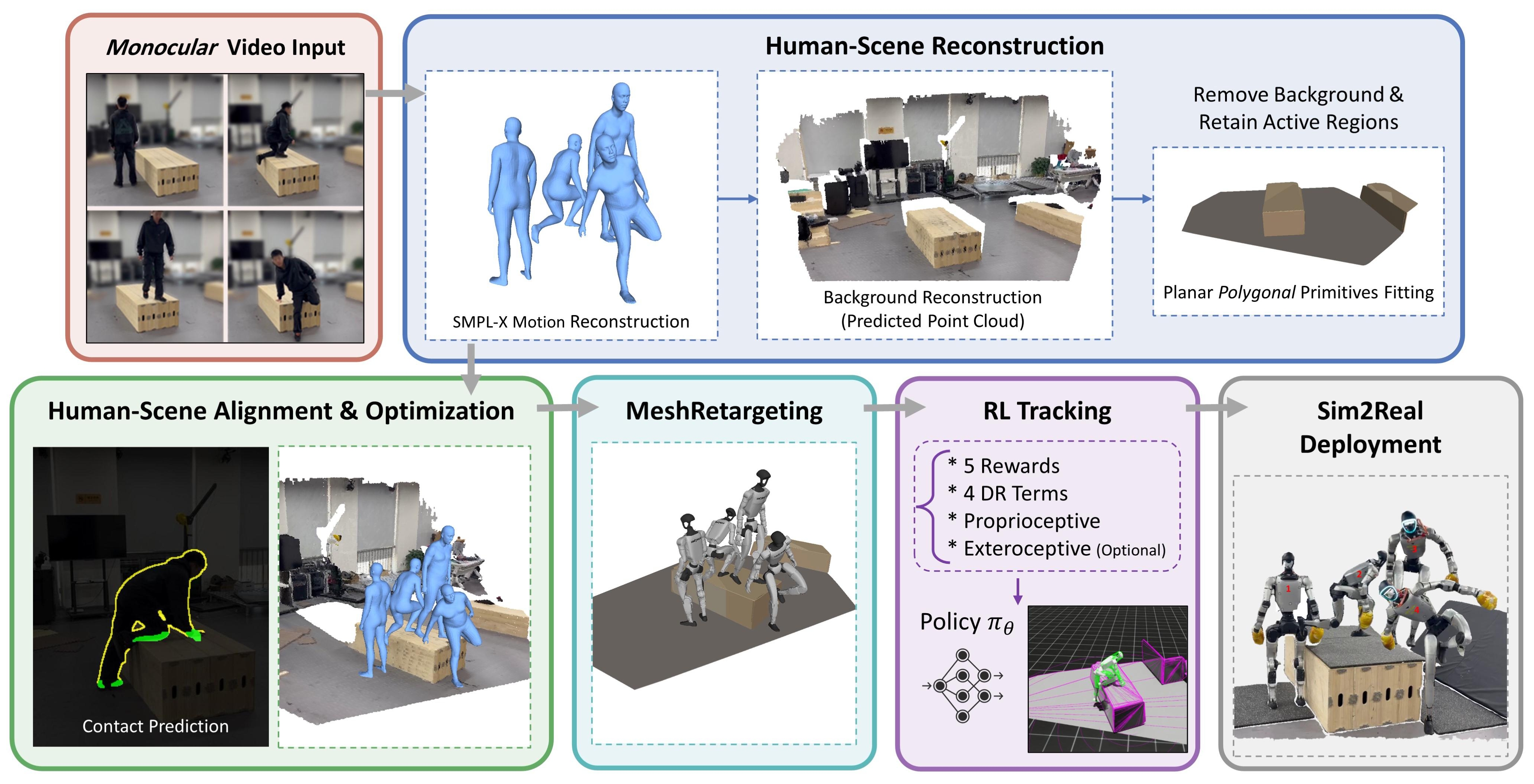
问题定义:现有类人运动学习方法主要依赖于运动捕捉(MoCap)数据,这些数据获取成本高昂且通常缺乏周围环境的几何信息。这导致运动合成框架在处理地形感知任务时,运动与场景之间存在解耦,从而产生物理不一致性,例如接触滑动或网格穿透等问题。因此,如何低成本地获取包含环境几何信息的运动数据,并实现运动与环境的有效耦合,是亟待解决的问题。
核心思路:MeshMimic的核心思路是通过3D场景重建技术,从视频中提取人类运动轨迹以及周围环境的3D几何信息。然后,利用这些信息训练类人机器人,使其能够学习与环境交互的运动策略。这种方法避免了对昂贵MoCap数据的依赖,并能够直接从视觉数据中学习运动与环境的耦合关系。
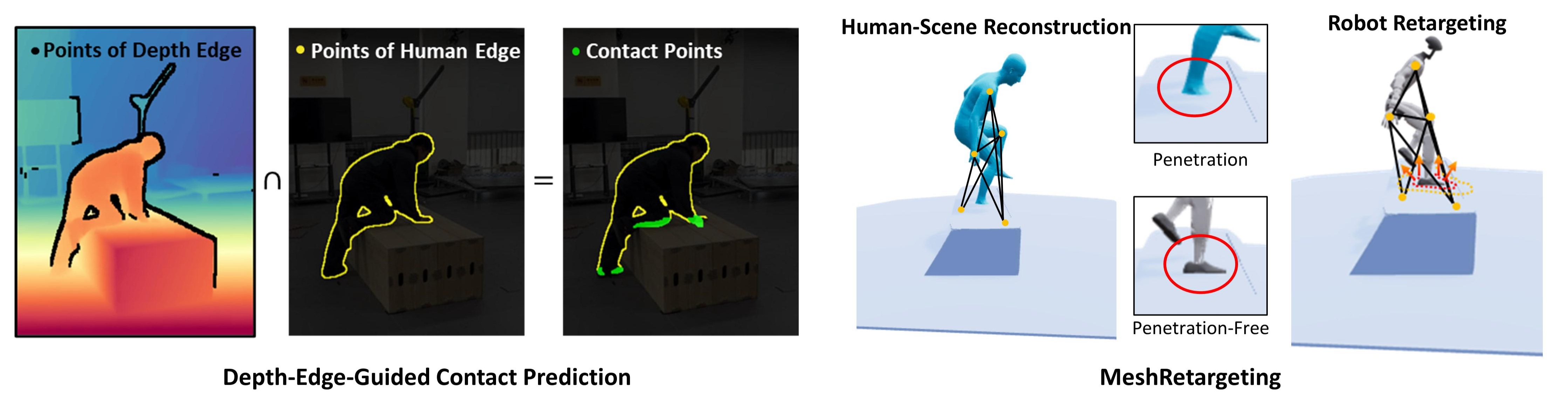
技术框架:MeshMimic框架主要包含以下几个阶段:1) 3D场景重建:利用先进的3D视觉模型,从视频中分割和重建人类轨迹以及地形和物体的3D几何结构。2) 运动数据提取:引入基于运动学一致性的优化算法,从嘈杂的视觉重建中提取高质量的运动数据。3) 运动重定向:采用接触不变的重定向方法,将人与环境的交互特征转移到类人代理。4) 强化学习训练:使用提取的运动数据和重定向的交互特征,训练类人机器人在复杂地形上的运动策略。
关键创新:MeshMimic的关键创新在于将3D场景重建与具身智能相结合,实现了从视频中直接学习耦合的“运动-地形”交互。与传统的依赖MoCap数据的方法相比,MeshMimic能够利用低成本的单目传感器获取包含环境几何信息的运动数据,并避免了运动与场景的解耦问题。此外,该框架还提出了一种基于运动学一致性的优化算法和接触不变的重定向方法,进一步提高了运动数据的质量和运动策略的泛化能力。
关键设计:在3D场景重建阶段,使用了先进的3D视觉模型,例如Mask R-CNN等,用于分割和重建人类轨迹以及地形和物体的3D几何结构。在运动数据提取阶段,设计了一种基于运动学一致性的优化算法,该算法通过最小化运动学约束误差来提高运动数据的质量。在运动重定向阶段,采用了一种接触不变的重定向方法,该方法通过保持接触点的相对位置关系来保证运动策略的泛化能力。在强化学习训练阶段,使用了常见的强化学习算法,例如PPO等,并设计了合适的奖励函数来引导类人机器人学习与环境交互的运动策略。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MeshMimic在各种具有挑战性的地形上实现了稳健、高度动态的性能。与传统的依赖MoCap数据的方法相比,MeshMimic能够利用低成本的单目传感器训练类人机器人在复杂地形上行走,并且能够有效地避免接触滑动和网格穿透等问题。具体性能数据和对比基线在论文中进行了详细展示,证明了MeshMimic的优越性。
🎯 应用场景
MeshMimic技术可应用于机器人导航、虚拟现实、游戏开发等领域。例如,可以训练机器人在复杂地形中行走、攀爬,提升机器人的自主性和适应性。在虚拟现实和游戏开发中,可以生成更真实、自然的虚拟角色运动,增强用户体验。此外,该技术还有助于开发更智能的假肢,帮助残疾人恢复运动能力。
📄 摘要(原文)
Humanoid motion control has witnessed significant breakthroughs in recent years, with deep reinforcement learning (RL) emerging as a primary catalyst for achieving complex, human-like behaviors. However, the high dimensionality and intricate dynamics of humanoid robots make manual motion design impractical, leading to a heavy reliance on expensive motion capture (MoCap) data. These datasets are not only costly to acquire but also frequently lack the necessary geometric context of the surrounding physical environment. Consequently, existing motion synthesis frameworks often suffer from a decoupling of motion and scene, resulting in physical inconsistencies such as contact slippage or mesh penetration during terrain-aware tasks. In this work, we present MeshMimic, an innovative framework that bridges 3D scene reconstruction and embodied intelligence to enable humanoid robots to learn coupled "motion-terrain" interactions directly from video. By leveraging state-of-the-art 3D vision models, our framework precisely segments and reconstructs both human trajectories and the underlying 3D geometry of terrains and objects. We introduce an optimization algorithm based on kinematic consistency to extract high-quality motion data from noisy visual reconstructions, alongside a contact-invariant retargeting method that transfers human-environment interaction features to the humanoid agent. Experimental results demonstrate that MeshMimic achieves robust, highly dynamic performance across diverse and challenging terrains. Our approach proves that a low-cost pipeline utilizing only consumer-grade monocular sensors can facilitate the training of complex physical interactions, offering a scalable path toward the autonomous evolution of humanoid robots in unstructured environments.