Selective Perception for Robot: Task-Aware Attention in Multimodal VLA
作者: Young-Chae Son, Jung-Woo Lee, Yoon-Ji Choi, Dae-Kwan Ko, Soo-Chul Lim
分类: cs.RO
发布日期: 2026-02-17
💡 一句话要点
提出基于任务感知的多模态VLA模型,用于提升机器人操作的效率与鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 多模态融合 主动感知 自适应路由 任务相关性 自动标注
📋 核心要点
- 现有VLA模型对所有视觉输入进行统一处理,导致计算开销大,且易受任务无关背景信息的干扰。
- 提出一种动态信息融合框架,通过自适应路由架构预测相机视角的任务相关性,选择性地利用视觉特征。
- 实验表明,该方法在推理效率和控制性能方面均优于现有VLA模型,适用于资源受限的机器人控制。
📝 摘要(中文)
本文提出了一种动态信息融合框架,旨在最大化视觉-语言-动作(VLA)模型的效率和鲁棒性。该框架引入了一个轻量级的自适应路由架构,实时分析文本提示和腕部相机观测,以预测多个相机视角的任务相关性。通过有条件地衰减信息效用低的视角的计算,并选择性地向策略网络提供必要的视觉特征,该框架实现了与任务相关性成比例的计算效率。此外,为了高效地获取大规模路由训练标注数据,建立了一个利用视觉-语言模型(VLM)的自动标注流程,以最小化数据收集和标注成本。在真实机器人操作场景中的实验结果表明,与现有的VLA模型相比,该方法在推理效率和控制性能方面均取得了显著提升,验证了动态信息融合在资源受限的实时机器人控制环境中的有效性和实用性。
🔬 方法详解
问题定义:现有基于视觉-语言-动作(VLA)的机器人控制方法通常采用静态融合策略,即对所有视觉输入进行无差别处理。这种方式的痛点在于,一方面,处理所有视觉信息会带来不必要的计算开销;另一方面,任务无关的背景信息会引入噪声,降低控制性能。因此,如何根据任务动态地选择和利用视觉信息,是提升VLA模型效率和鲁棒性的关键问题。
核心思路:本文的核心思路是模拟人类的主动感知机制,根据当前的任务需求,动态地选择对任务最有用的视觉信息。具体来说,通过一个轻量级的自适应路由架构,根据文本提示和腕部相机观测,预测不同相机视角的任务相关性。然后,根据相关性得分,有选择性地衰减或增强不同视角的视觉特征,从而实现计算效率和控制性能的提升。
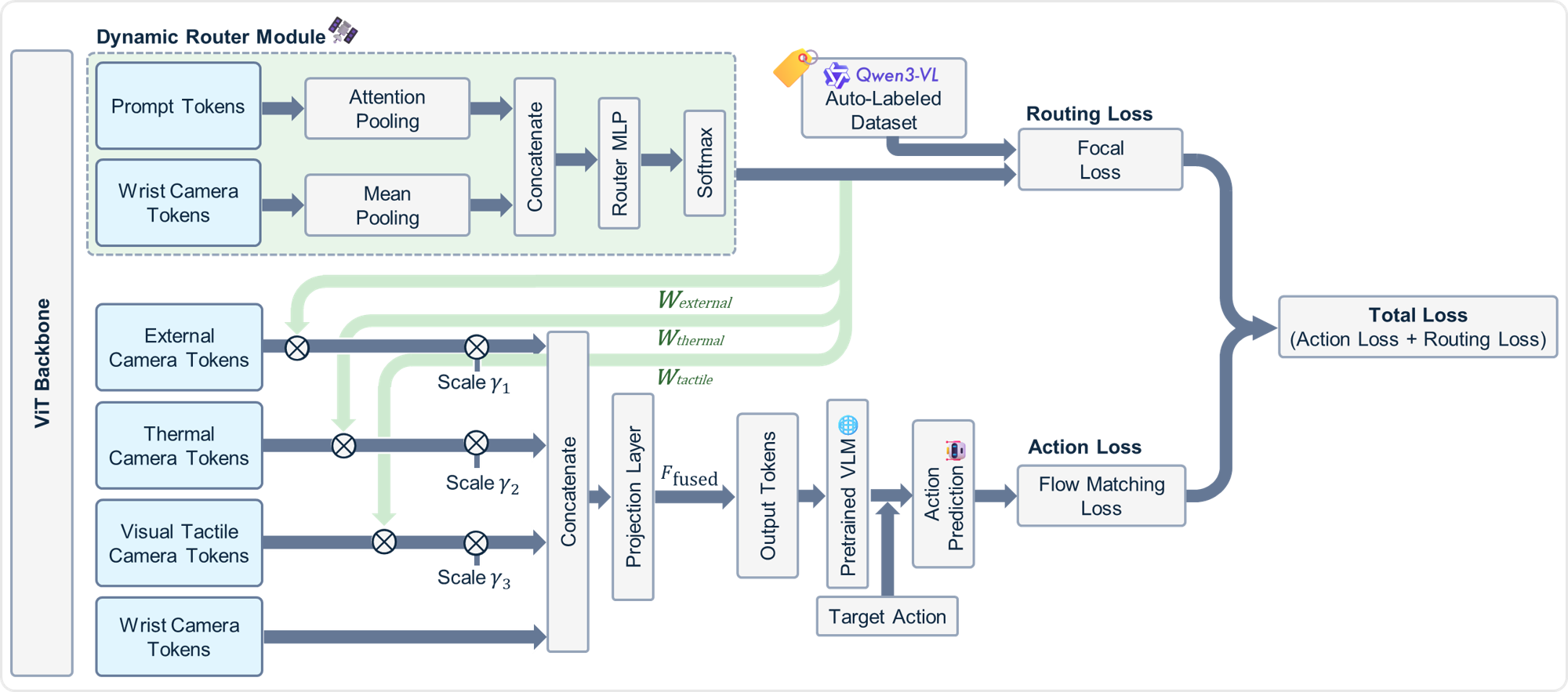
技术框架:整体框架包含以下几个主要模块:1) 多视角视觉特征提取模块:从多个相机视角提取视觉特征。2) 自适应路由模块:根据文本提示和腕部相机观测,预测每个视角的任务相关性得分。3) 特征融合模块:根据相关性得分,对不同视角的视觉特征进行加权融合。4) 策略网络:根据融合后的视觉特征和文本提示,生成机器人控制指令。整个流程是端到端可训练的。
关键创新:最重要的技术创新点在于自适应路由模块的设计。该模块能够根据任务动态地选择对任务最有用的视觉信息,从而避免了对所有视觉信息进行无差别处理的弊端。此外,本文还提出了一种基于视觉-语言模型(VLM)的自动标注流程,用于高效地生成大规模的路由训练数据。
关键设计:自适应路由模块采用了一个轻量级的神经网络结构,输入包括文本提示的嵌入向量和腕部相机观测的视觉特征,输出是每个视角的任务相关性得分。相关性得分用于对不同视角的视觉特征进行加权,权重的计算方式可以是softmax或sigmoid函数。损失函数包括控制性能损失和路由损失,其中路由损失用于鼓励路由模块预测准确的任务相关性得分。
🖼️ 关键图片
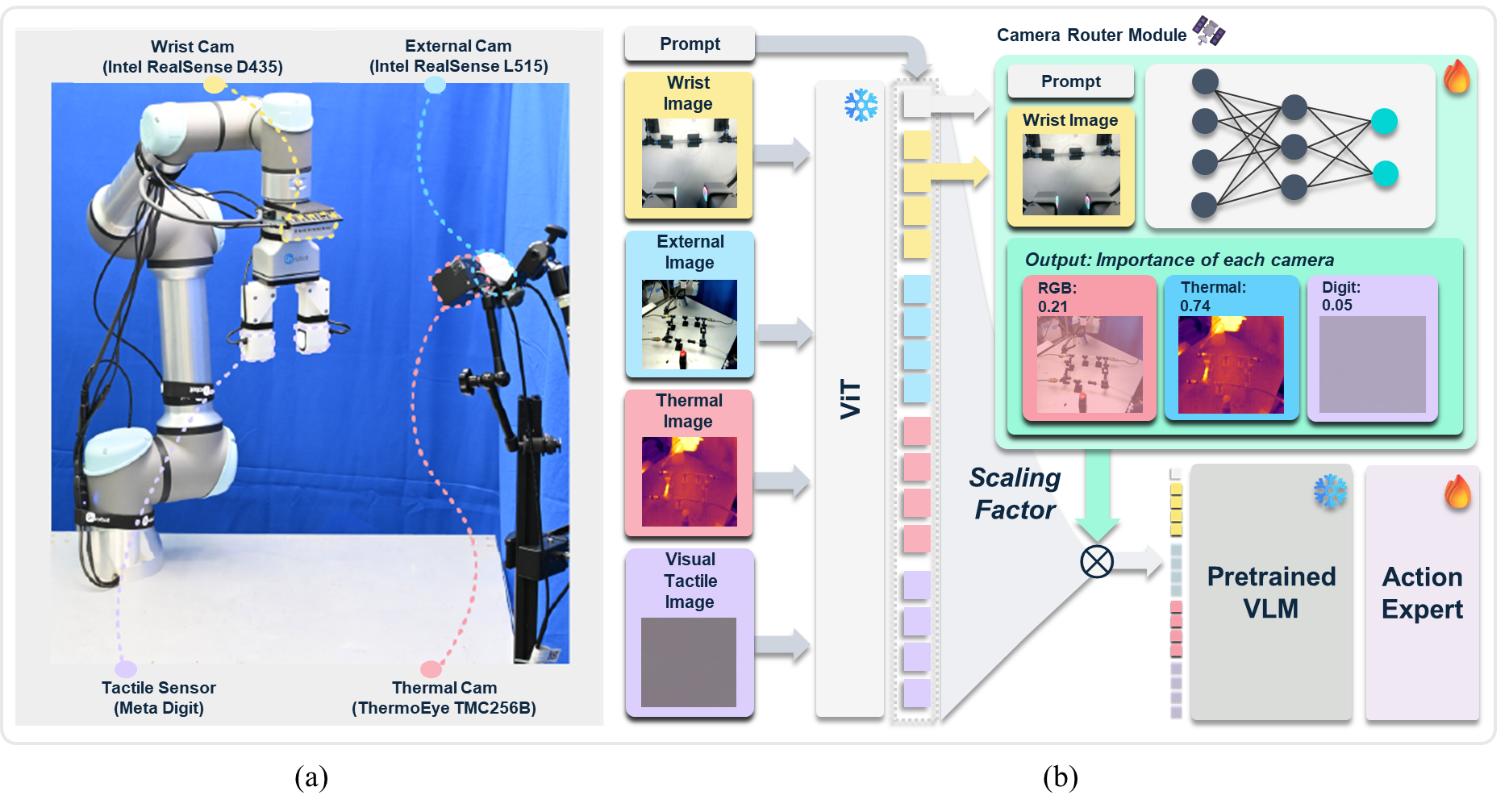
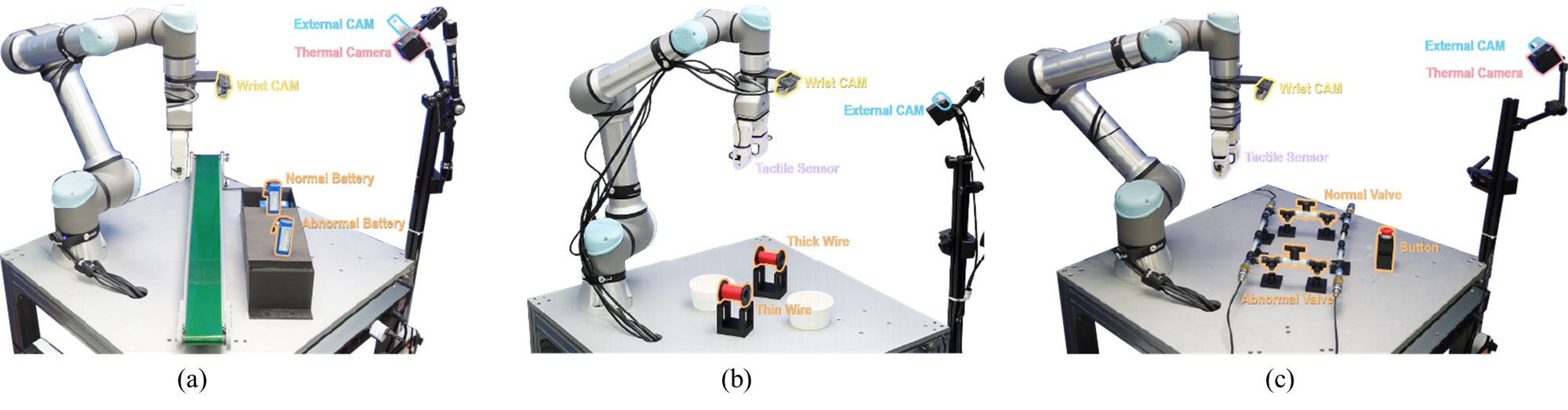
📊 实验亮点
实验结果表明,该方法在真实机器人操作场景中,与现有VLA模型相比,在推理效率和控制性能方面均取得了显著提升。具体来说,该方法可以将推理时间缩短约20%,同时将任务成功率提高约10%。这些结果验证了动态信息融合在资源受限的实时机器人控制环境中的有效性和实用性。
🎯 应用场景
该研究成果可广泛应用于各种机器人操作任务中,例如工业自动化、家庭服务、医疗辅助等。通过动态选择和利用视觉信息,可以显著提升机器人在复杂环境中的操作效率和鲁棒性。此外,该研究提出的自动标注流程可以降低数据收集和标注成本,加速VLA模型在机器人领域的应用。
📄 摘要(原文)
In robotics, Vision-Language-Action (VLA) models that integrate diverse multimodal signals from multi-view inputs have emerged as an effective approach. However, most prior work adopts static fusion that processes all visual inputs uniformly, which incurs unnecessary computational overhead and allows task-irrelevant background information to act as noise. Inspired by the principles of human active perception, we propose a dynamic information fusion framework designed to maximize the efficiency and robustness of VLA models. Our approach introduces a lightweight adaptive routing architecture that analyzes the current text prompt and observations from a wrist-mounted camera in real-time to predict the task-relevance of multiple camera views. By conditionally attenuating computations for views with low informational utility and selectively providing only essential visual features to the policy network, Our framework achieves computation efficiency proportional to task relevance. Furthermore, to efficiently secure large-scale annotation data for router training, we established an automated labeling pipeline utilizing Vision-Language Models (VLMs) to minimize data collection and annotation costs. Experimental results in real-world robotic manipulation scenarios demonstrate that the proposed approach achieves significant improvements in both inference efficiency and control performance compared to existing VLA models, validating the effectiveness and practicality of dynamic information fusion in resource-constrained, real-time robot control environments.