Efficient Knowledge Transfer for Jump-Starting Control Policy Learning of Multirotors through Physics-Aware Neural Architectures
作者: Welf Rehberg, Mihir Kulkarni, Philipp Weiss, Kostas Alexis
分类: cs.RO
发布日期: 2026-02-17
备注: 8 pages. Accepted to IEEE Robotics and Automation Letters
💡 一句话要点
提出基于物理感知的神经架构,加速多旋翼飞行器控制策略的跨平台迁移学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 多旋翼飞行器 强化学习 知识迁移 控制策略 物理感知
📋 核心要点
- 多旋翼飞行器控制策略训练耗时,跨平台迁移学习是提升效率的关键,但现有方法难以有效利用不同构型飞行器的知识。
- 论文提出一种物理感知的神经控制架构,结合强化学习控制器和监督控制分配网络,实现策略复用和跨平台迁移。
- 实验表明,该方法在多种四旋翼和六旋翼设计中,相比从头训练,平均节省高达73.5%的环境交互次数。
📝 摘要(中文)
本研究致力于通过跨平台知识迁移,高效训练机器人控制策略,尤其关注利用从相似系统训练中获得的知识来加速策略训练。论文提出了一种基于库的初始化方案,能够实现多旋翼飞行器配置间的有效知识迁移。该方案利用一种物理感知的神经控制架构,结合了基于强化学习的控制器和监督控制分配网络,从而能够复用先前训练的策略。为此,论文采用了一种基于策略评估的相似性度量方法,从库中识别适合初始化的策略。实验证明,该度量方法与达到目标性能所需的环境交互次数的减少相关,因此适合用于初始化。大量的仿真和真实实验证实,该控制架构实现了最先进的控制性能,并且初始化方案平均节省了高达73.5%的环境交互(与从头开始训练策略相比),为强化学习中有效的跨平台迁移铺平了道路。
🔬 方法详解
问题定义:现有方法在多旋翼飞行器控制策略学习中,尤其是跨不同构型(例如,四旋翼到六旋翼)的知识迁移时,存在效率低下的问题。从头开始训练每个新构型的飞行器控制策略需要大量的环境交互,耗费大量时间和计算资源。现有方法难以有效利用已有的控制策略知识,导致重复学习。
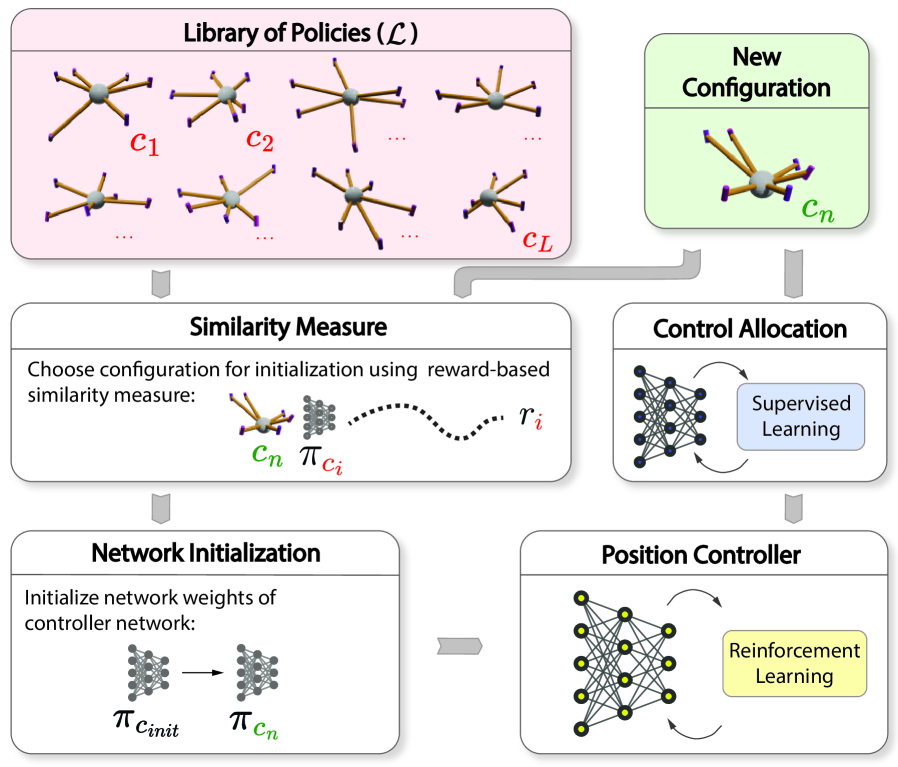
核心思路:论文的核心思路是利用物理感知的神经架构,将控制策略学习分解为两个模块:一个基于强化学习的控制器和一个监督控制分配网络。通过这种解耦,可以更容易地复用和迁移已训练的控制器,并根据新的飞行器构型调整控制分配网络。此外,论文提出了一种基于策略评估的相似性度量方法,用于从策略库中选择合适的策略进行初始化,从而进一步加速学习过程。
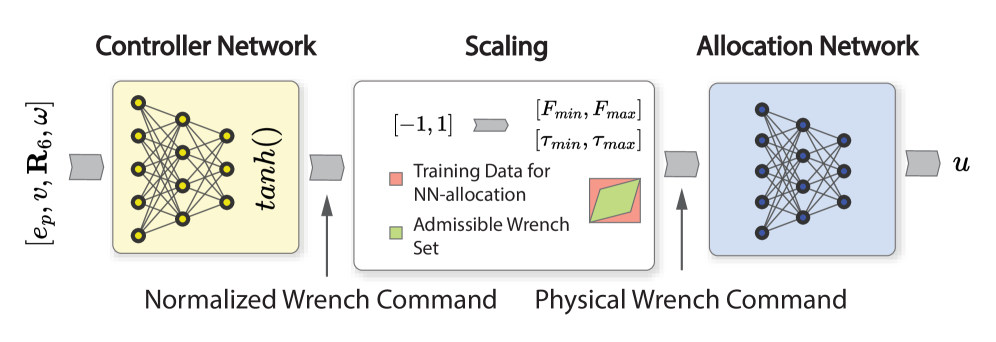
技术框架:整体框架包含以下几个主要模块:1) 策略库:存储了预先训练好的各种多旋翼飞行器控制策略。2) 相似性度量:使用基于策略评估的相似性度量方法,评估策略库中策略与目标飞行器构型的相似度。3) 物理感知的神经控制架构:包含一个强化学习控制器和一个监督控制分配网络。强化学习控制器负责生成期望的力矩,控制分配网络负责将期望力矩转换为各个电机的转速。4) 初始化方案:根据相似性度量结果,选择合适的策略初始化强化学习控制器,并训练控制分配网络。
关键创新:论文的关键创新在于:1) 物理感知的神经架构:通过将控制策略解耦为强化学习控制器和监督控制分配网络,实现了更好的可迁移性。2) 基于策略评估的相似性度量:提出了一种有效的相似性度量方法,用于从策略库中选择合适的策略进行初始化,加速学习过程。3) 跨平台迁移学习:成功实现了在不同构型的多旋翼飞行器之间进行知识迁移,显著提高了控制策略学习的效率。
关键设计:1) 强化学习控制器:使用近端策略优化(PPO)算法进行训练,奖励函数的设计考虑了位置跟踪误差、速度跟踪误差和姿态跟踪误差。2) 监督控制分配网络:使用多层感知机(MLP)进行建模,损失函数为期望力矩与实际力矩之间的均方误差。3) 相似性度量:通过评估策略在目标飞行器构型上的性能(例如,跟踪误差),来衡量策略的相似度。选择相似度最高的策略作为初始策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多种四旋翼和六旋翼设计中,相比从头训练,平均节省高达73.5%的环境交互次数。在真实实验中,该方法也表现出良好的性能,验证了其在实际应用中的可行性。该方法在控制性能方面也达到了最先进水平。
🎯 应用场景
该研究成果可广泛应用于多旋翼飞行器的快速部署和控制策略优化。例如,在开发新型无人机时,可以利用已有的控制策略知识进行快速迁移学习,缩短开发周期。此外,该方法还可以应用于集群无人机控制、自主导航和复杂环境下的飞行控制等领域,具有重要的实际应用价值。
📄 摘要(原文)
Efficiently training control policies for robots is a major challenge that can greatly benefit from utilizing knowledge gained from training similar systems through cross-embodiment knowledge transfer. In this work, we focus on accelerating policy training using a library-based initialization scheme that enables effective knowledge transfer across multirotor configurations. By leveraging a physics-aware neural control architecture that combines a reinforcement learning-based controller and a supervised control allocation network, we enable the reuse of previously trained policies. To this end, we utilize a policy evaluation-based similarity measure that identifies suitable policies for initialization from a library. We demonstrate that this measure correlates with the reduction in environment interactions needed to reach target performance and is therefore suited for initialization. Extensive simulation and real-world experiments confirm that our control architecture achieves state-of-the-art control performance, and that our initialization scheme saves on average up to $73.5\%$ of environment interactions (compared to training a policy from scratch) across diverse quadrotor and hexarotor designs, paving the way for efficient cross-embodiment transfer in reinforcement learning.