One Agent to Guide Them All: Empowering MLLMs for Vision-and-Language Navigation via Explicit World Representation
作者: Zerui Li, Hongpei Zheng, Fangguo Zhao, Aidan Chan, Jian Zhou, Sihao Lin, Shijie Li, Qi Wu
分类: cs.RO
发布日期: 2026-02-17
💡 一句话要点
提出基于显式世界表征的MLLM导航框架,提升视觉-语言导航任务性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言导航 多模态大语言模型 度量世界表征 反事实推理 零样本学习 具身智能
📋 核心要点
- 现有VLN Agent紧耦合设计限制了基于MLLM的导航系统性能,难以有效分离空间状态估计和语义规划。
- 论文提出解耦框架,引入交互式度量世界表征,并结合反事实推理,提升MLLM在VLN任务中的决策能力。
- 实验表明,该方法在模拟和真实环境中均取得了显著的性能提升,并在零样本sim-to-real迁移中表现出良好的通用性。
📝 摘要(中文)
本文提出了一种解耦设计的视觉-语言导航(VLN)Agent,旨在提升基于多模态大语言模型(MLLM)的导航系统性能。与现有紧耦合设计不同,该方法将底层空间状态估计与高层语义规划分离。引入交互式度量世界表征,维护丰富且一致的信息,供MLLM交互和推理决策。此外,引入反事实推理进一步激发MLLM的能力,同时度量世界表征确保生成动作的物理有效性。在模拟和真实环境中进行了实验,该方法在R2R-CE和RxR-CE基准测试中分别实现了48.8%和42.2%的成功率(SR),达到了新的零样本SOTA。通过在轮式TurtleBot 4和定制无人机等不同实体上的零样本sim-to-real迁移,验证了度量表征的通用性。真实世界的部署验证了解耦框架作为具身视觉-语言导航的鲁棒、领域不变的接口。
🔬 方法详解
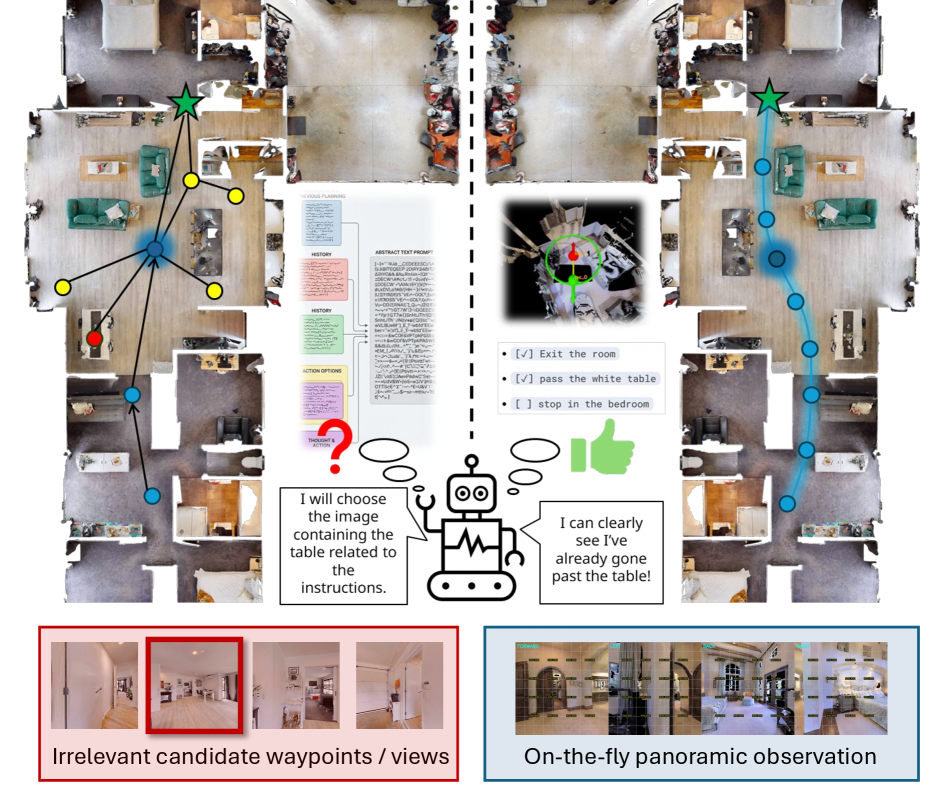
问题定义:现有的基于多模态大语言模型(MLLM)的视觉-语言导航(VLN)Agent通常采用紧耦合设计,即将视觉感知、语义理解和动作规划等模块紧密集成在一起。这种设计使得系统难以有效分离底层空间状态估计和高层语义规划,限制了系统的泛化能力和性能。此外,现有方法通常依赖于预定义的、过于简化的文本地图,无法提供足够丰富和一致的环境信息,阻碍了MLLM进行有效的推理和决策。
核心思路:本文的核心思路是将VLN任务解耦为两个独立的模块:底层空间状态估计和高层语义规划。通过引入一个交互式的度量世界表征,系统可以维护一个丰富且一致的环境信息模型,供MLLM进行交互和推理。同时,利用反事实推理来进一步激发MLLM的决策能力,并确保生成的动作在物理上是有效的。这种解耦设计使得系统可以更好地利用MLLM的语义理解能力,并提高导航的准确性和鲁棒性。
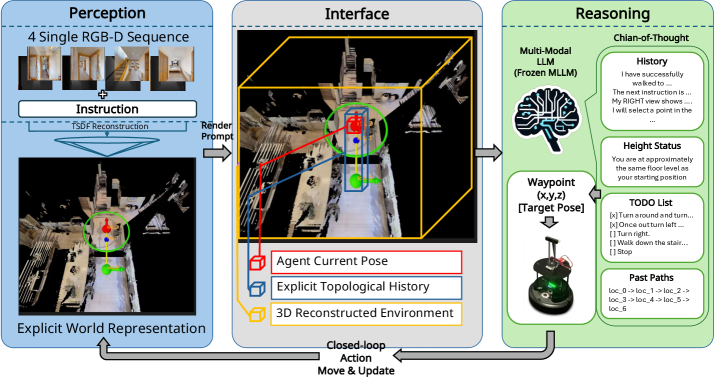
技术框架:该方法的技术框架主要包括以下几个模块:1) 视觉感知模块:负责从环境中提取视觉特征,例如图像或点云数据。2) 度量世界表征模块:负责维护一个环境的度量地图,并允许MLLM通过交互来更新和查询该地图。3) 语义规划模块:利用MLLM根据指令和环境信息生成导航路径。4) 动作执行模块:将导航路径转化为具体的动作指令,控制Agent在环境中移动。整个流程是,Agent首先通过视觉感知模块获取环境信息,然后利用度量世界表征模块构建环境地图,接着MLLM根据指令和环境地图进行语义规划,最后动作执行模块将规划结果转化为具体的动作指令。
关键创新:该方法最重要的技术创新点在于引入了交互式的度量世界表征。与传统的文本地图相比,度量世界表征可以提供更丰富和一致的环境信息,并且允许MLLM通过交互来更新和查询该地图。此外,该方法还引入了反事实推理,以进一步激发MLLM的决策能力。与现有方法的本质区别在于,该方法将VLN任务解耦为两个独立的模块,并利用度量世界表征作为桥梁,使得系统可以更好地利用MLLM的语义理解能力。
关键设计:在度量世界表征模块中,可以使用SLAM(Simultaneous Localization and Mapping)等技术来构建环境地图。在语义规划模块中,可以使用Prompt Engineering等技术来引导MLLM生成合理的导航路径。在反事实推理中,可以通过模拟不同的动作序列,并评估其对环境的影响,来选择最优的动作。损失函数的设计可以包括导航成功率、路径长度等指标,以优化系统的性能。
🖼️ 关键图片

📊 实验亮点
该方法在R2R-CE和RxR-CE基准测试中分别实现了48.8%和42.2%的成功率(SR),达到了新的零样本SOTA。相较于之前的最佳方法,在R2R-CE上提升了显著的性能。此外,该方法还在轮式TurtleBot 4和定制无人机等不同实体上进行了零样本sim-to-real迁移实验,验证了其在真实环境中的有效性和通用性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。例如,可以利用该方法开发出更智能的家庭服务机器人,帮助老年人或残疾人在家中自由移动。此外,该方法还可以应用于自动驾驶汽车,提高其在复杂环境中的导航能力。在虚拟现实领域,该方法可以用于创建更逼真的虚拟环境,并允许用户在虚拟环境中自由探索。
📄 摘要(原文)
A navigable agent needs to understand both high-level semantic instructions and precise spatial perceptions. Building navigation agents centered on Multimodal Large Language Models (MLLMs) demonstrates a promising solution due to their powerful generalization ability. However, the current tightly coupled design dramatically limits system performance. In this work, we propose a decoupled design that separates low-level spatial state estimation from high-level semantic planning. Unlike previous methods that rely on predefined, oversimplified textual maps, we introduce an interactive metric world representation that maintains rich and consistent information, allowing MLLMs to interact with and reason on it for decision-making. Furthermore, counterfactual reasoning is introduced to further elicit MLLMs' capacity, while the metric world representation ensures the physical validity of the produced actions. We conduct comprehensive experiments in both simulated and real-world environments. Our method establishes a new zero-shot state-of-the-art, achieving 48.8\% Success Rate (SR) in R2R-CE and 42.2\% in RxR-CE benchmarks. Furthermore, to validate the versatility of our metric representation, we demonstrate zero-shot sim-to-real transfer across diverse embodiments, including a wheeled TurtleBot 4 and a custom-built aerial drone. These real-world deployments verify that our decoupled framework serves as a robust, domain-invariant interface for embodied Vision-and-Language navigation.