ActionCodec: What Makes for Good Action Tokenizers
作者: Zibin Dong, Yicheng Liu, Shiduo Zhang, Baijun Ye, Yifu Yuan, Fei Ni, Jingjing Gong, Xipeng Qiu, Hang Zhao, Yinchuan Li, Jianye Hao
分类: cs.RO, cs.AI
发布日期: 2026-02-17
💡 一句话要点
ActionCodec:面向VLA优化的动作Tokenizer设计,提升训练效率与性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 动作Tokenization VLA优化 机器人控制 多模态学习
📋 核心要点
- 现有VLA模型中的动作Tokenizer设计主要关注重构保真度,忽略了其对VLA优化过程的直接影响,导致性能瓶颈。
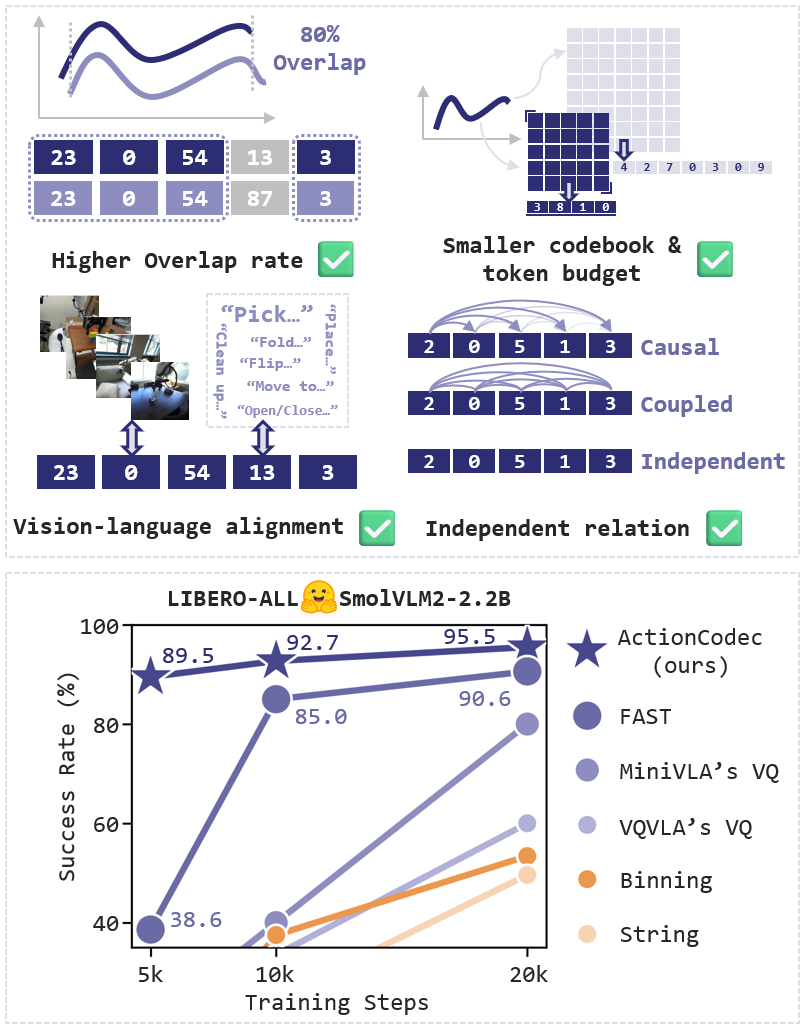
- 论文从VLA优化角度出发,提出了最大化时间token重叠、最小化词汇冗余等设计原则,指导动作Tokenizer的设计。
- 提出的ActionCodec在LIBERO数据集上显著提升了VLA模型的性能,无需机器人预训练即可达到SOTA水平,验证了设计原则的有效性。
📝 摘要(中文)
本文针对视觉-语言-动作(VLA)模型中动作Tokenizer的设计问题,指出现有方法主要关注重构保真度,忽略了其对VLA优化的直接影响。论文从VLA优化的角度出发,建立了动作Tokenizer的设计原则,包括最大化时间token重叠、最小化词汇冗余、增强多模态互信息和token独立性。基于这些原则,论文提出了ActionCodec,一种高性能的动作Tokenizer,显著提高了VLA模型的训练效率和性能。在LIBERO数据集上,使用ActionCodec微调的SmolVLM2-2.2B在没有任何机器人预训练的情况下,成功率达到了95.5%。通过进一步的架构增强,成功率达到了97.4%,代表了VLA模型在没有机器人预训练情况下的新SOTA。论文提出的设计原则和开源模型将为社区开发更有效的动作Tokenizer提供清晰的路线图。
🔬 方法详解
问题定义:现有VLA模型依赖于动作tokenization,但现有动作tokenizers的设计主要集中在动作重建的保真度上,而忽略了tokenization方案对VLA模型训练和优化过程的直接影响。因此,如何设计一个好的动作tokenizer,使其能够更好地服务于VLA模型的训练和推理,是一个亟待解决的问题。现有方法的痛点在于缺乏从VLA优化角度出发的设计原则。
核心思路:论文的核心思路是从信息论的角度出发,分析动作tokenization对VLA模型训练的影响,并据此提出一系列设计原则。这些原则旨在提高token的信息密度、降低冗余、增强多模态信息融合,最终提升VLA模型的性能。通过优化tokenization过程,使得模型能够更有效地学习和利用动作信息。
技术框架:ActionCodec的技术框架主要包含以下几个方面:首先,通过最大化时间token重叠来提高token的信息密度,使得模型能够更好地捕捉动作的时间相关性。其次,通过最小化词汇冗余来减少token的冗余信息,提高模型的学习效率。第三,通过增强多模态互信息来促进视觉和语言信息与动作token的融合,使得模型能够更好地理解动作的上下文信息。最后,通过token独立性来减少token之间的依赖关系,提高模型的泛化能力。
关键创新:论文最重要的技术创新点在于提出了从VLA优化角度出发的动作Tokenizer设计原则。这些原则不同于以往只关注重构保真度的设计思路,而是更加关注tokenization对VLA模型训练和推理的实际影响。通过这些原则的指导,可以设计出更加高效和有效的动作Tokenizer,从而提升VLA模型的性能。与现有方法的本质区别在于,ActionCodec的设计目标是优化VLA模型的整体性能,而不仅仅是动作的重建效果。
关键设计:ActionCodec的关键设计包括:1) 使用滑动窗口的方式进行tokenization,以实现最大化时间token重叠;2) 使用信息熵等指标来评估和优化词汇冗余;3) 设计特定的损失函数来增强多模态互信息;4) 采用正则化等方法来促进token独立性。具体的参数设置和网络结构细节在论文中进行了详细描述,例如滑动窗口的大小、信息熵的阈值、损失函数的权重等。
🖼️ 关键图片

📊 实验亮点
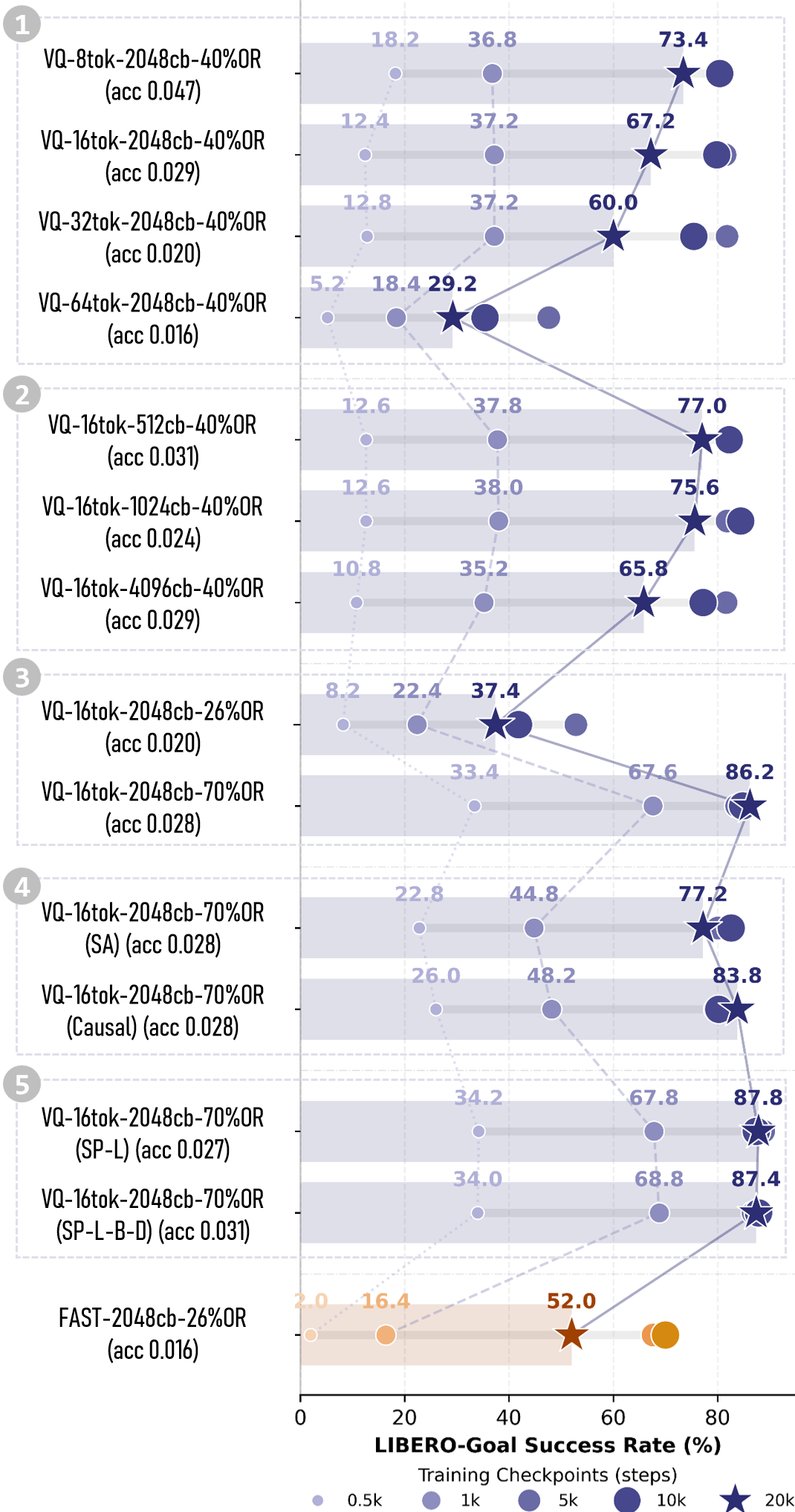
ActionCodec在LIBERO数据集上取得了显著的性能提升。使用ActionCodec微调的SmolVLM2-2.2B在没有任何机器人预训练的情况下,成功率达到了95.5%。通过进一步的架构增强,成功率达到了97.4%,代表了VLA模型在没有机器人预训练情况下的新SOTA。这表明ActionCodec能够有效地提升VLA模型的性能,并降低对机器人预训练的依赖。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、游戏AI等领域。通过优化动作tokenization,可以提升VLA模型在这些领域的性能和效率,例如使机器人能够更好地理解人类指令并执行复杂任务,或者使自动驾驶系统能够更准确地预测和响应交通状况。未来,该研究还可以扩展到其他模态的tokenization,例如语音和文本。
📄 摘要(原文)
Vision-Language-Action (VLA) models leveraging the native autoregressive paradigm of Vision-Language Models (VLMs) have demonstrated superior instruction-following and training efficiency. Central to this paradigm is action tokenization, yet its design has primarily focused on reconstruction fidelity, failing to address its direct impact on VLA optimization. Consequently, the fundamental question of \textit{what makes for good action tokenizers} remains unanswered. In this paper, we bridge this gap by establishing design principles specifically from the perspective of VLA optimization. We identify a set of best practices based on information-theoretic insights, including maximized temporal token overlap, minimized vocabulary redundancy, enhanced multimodal mutual information, and token independence. Guided by these principles, we introduce \textbf{ActionCodec}, a high-performance action tokenizer that significantly enhances both training efficiency and VLA performance across diverse simulation and real-world benchmarks. Notably, on LIBERO, a SmolVLM2-2.2B fine-tuned with ActionCodec achieves a 95.5\% success rate without any robotics pre-training. With advanced architectural enhancements, this reaches 97.4\%, representing a new SOTA for VLA models without robotics pre-training. We believe our established design principles, alongside the released model, will provide a clear roadmap for the community to develop more effective action tokenizers.