Feasibility-aware Imitation Learning from Observation with Multimodal Feedback
作者: Kei Takahashi, Hikaru Sasaki, Takamitsu Matsubara
分类: cs.RO
发布日期: 2026-02-17
💡 一句话要点
提出FABCO,通过多模态反馈实现可行性感知的观察模仿学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模仿学习 机器人控制 行为克隆 多模态反馈 可行性评估
📋 核心要点
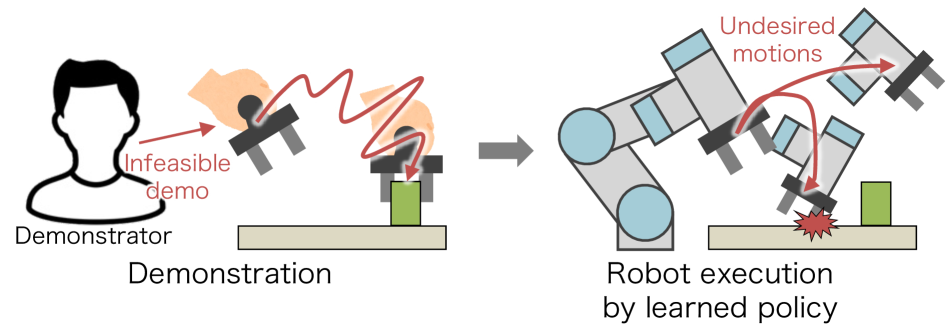
- 现有模仿学习方法难以处理示教者与机器人物理差异导致的示教动作不可行问题,且缺乏机器人动作信息。
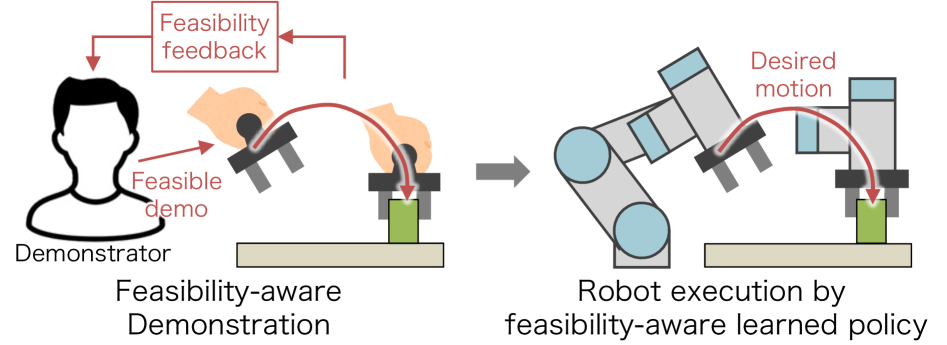
- FABCO通过机器人动力学模型评估示教动作的可行性,并利用多模态反馈指导示教者进行可行性示教。
- 实验结果表明,FABCO显著提升了模仿学习的性能,相比无反馈方法提升超过3.2倍。
📝 摘要(中文)
本文提出了一种可行性感知的观察模仿学习框架(FABCO),旨在解决示教者与机器人之间物理特性差异导致的模仿学习难题。该框架结合了基于观察的行为克隆和可行性评估。可行性评估利用从机器人执行数据中学习到的机器人动力学模型,评估示教动作在机器人动力学下的可复现性。评估的可行性被用于多模态反馈和可行性感知策略学习,以改进示教动作并学习鲁棒策略。多模态反馈通过视觉和触觉向示教者提供可行性信息,促进可行性示教动作的产生。可行性感知策略学习降低了机器人难以执行的示教动作的影响,从而学习机器人能够稳定执行的策略。在两个任务上对15名参与者进行的实验表明,与没有可行性反馈的情况相比,FABCO将模仿学习性能提高了3.2倍以上。
🔬 方法详解
问题定义:论文旨在解决观察模仿学习中,由于示教者和机器人之间的物理特性差异,导致示教数据不包含机器人动作,且示教动作对于机器人而言可能不可行的问题。现有方法难以有效地学习到机器人可执行的策略,导致模仿学习效果不佳。
核心思路:论文的核心思路是引入可行性评估机制,利用机器人动力学模型来评估示教动作的可行性,并利用评估结果进行多模态反馈和可行性感知的策略学习。通过多模态反馈,引导示教者提供更符合机器人动力学特性的示教动作;通过可行性感知的策略学习,降低不可行示教动作的影响,从而学习到机器人能够稳定执行的策略。
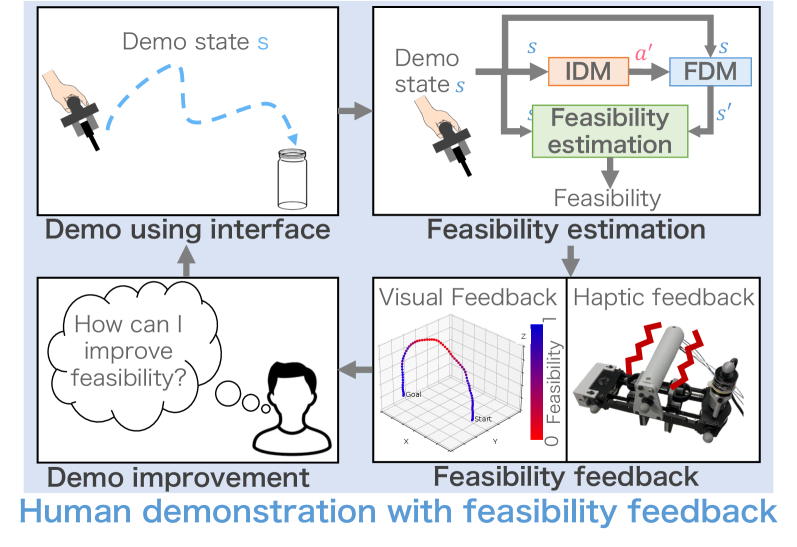
技术框架:FABCO框架主要包含三个模块:1) 基于观察的行为克隆:利用机器人动力学模型补全机器人动作信息;2) 可行性评估:使用从机器人执行数据中学习到的机器人动力学模型评估示教动作的可行性;3) 多模态反馈和可行性感知策略学习:根据可行性评估结果,通过视觉和触觉向示教者提供反馈,并调整策略学习过程,降低不可行示教动作的影响。
关键创新:论文的关键创新在于将可行性评估融入到观察模仿学习框架中,并利用多模态反馈指导示教者进行可行性示教。这种方法能够有效地解决示教者和机器人之间的物理特性差异带来的问题,提高模仿学习的性能。
关键设计:可行性评估模块使用从机器人执行数据中学习到的机器人动力学模型。多模态反馈通过视觉和触觉两种方式向示教者提供可行性信息,例如,通过颜色编码表示动作的可行性程度,并通过力反馈模拟机器人执行动作时的阻力。可行性感知策略学习通过调整损失函数,降低不可行示教动作的权重,从而学习到更鲁棒的策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FABCO在两个任务上均取得了显著的性能提升。与没有可行性反馈的情况相比,FABCO将模仿学习性能提高了3.2倍以上,证明了该方法在解决示教者与机器人物理差异问题上的有效性。
🎯 应用场景
该研究成果可应用于各种需要机器人模仿人类动作的场景,例如工业自动化、医疗康复、家庭服务等。通过FABCO框架,可以使机器人更容易地学习人类的技能,并更好地适应不同的任务环境,从而提高机器人的智能化水平和应用范围。
📄 摘要(原文)
Imitation learning frameworks that learn robot control policies from demonstrators' motions via hand-mounted demonstration interfaces have attracted increasing attention. However, due to differences in physical characteristics between demonstrators and robots, this approach faces two limitations: i) the demonstration data do not include robot actions, and ii) the demonstrated motions may be infeasible for robots. These limitations make policy learning difficult. To address them, we propose Feasibility-Aware Behavior Cloning from Observation (FABCO). FABCO integrates behavior cloning from observation, which complements robot actions using robot dynamics models, with feasibility estimation. In feasibility estimation, the demonstrated motions are evaluated using a robot-dynamics model, learned from the robot's execution data, to assess reproducibility under the robot's dynamics. The estimated feasibility is used for multimodal feedback and feasibility-aware policy learning to improve the demonstrator's motions and learn robust policies. Multimodal feedback provides feasibility through the demonstrator's visual and haptic senses to promote feasible demonstrated motions. Feasibility-aware policy learning reduces the influence of demonstrated motions that are infeasible for robots, enabling the learning of policies that robots can execute stably. We conducted experiments with 15 participants on two tasks and confirmed that FABCO improves imitation learning performance by more than 3.2 times compared to the case without feasibility feedback.