RoboAug: One Annotation to Hundreds of Scenes via Region-Contrastive Data Augmentation for Robotic Manipulation
作者: Xinhua Wang, Kun Wu, Zhen Zhao, Hu Cao, Yinuo Zhao, Zhiyuan Xu, Meng Li, Shichao Fan, Di Wu, Yixue Zhang, Ning Liu, Zhengping Che, Jian Tang
分类: cs.RO
发布日期: 2026-02-15
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
RoboAug:通过区域对比数据增强,仅需单张标注图像即可泛化至复杂机器人操作场景
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 数据增强 生成模型 区域对比学习 泛化能力 单样本学习 机器人学习
📋 核心要点
- 现有机器人学习方法依赖大规模数据预训练或完美的物体检测,成本高昂且假设不成立。
- RoboAug利用单张标注图像和预训练生成模型进行语义数据增强,并引入区域对比损失。
- 真实机器人实验表明,RoboAug在未见场景中显著提升了任务成功率,优于现有方法。
📝 摘要(中文)
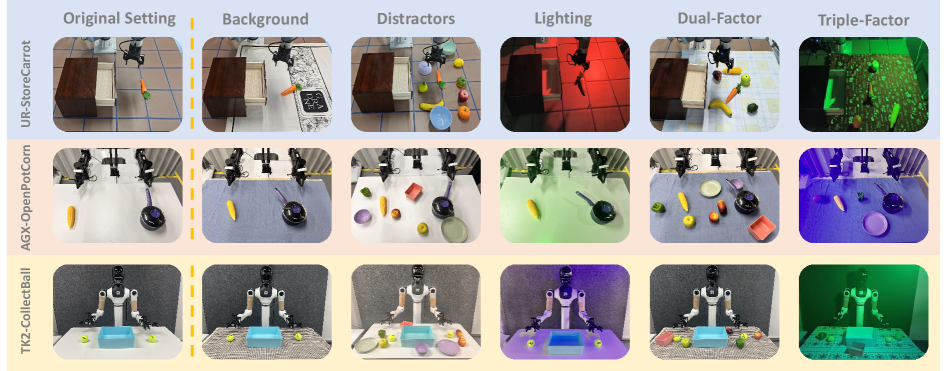
为了增强机器人学习的泛化能力,使其在各种未见过的场景中有效运行,本文提出了一种新的生成式数据增强框架RoboAug。该框架显著降低了对大规模预训练和完美视觉识别假设的依赖,仅需训练期间单张图像的边界框标注。RoboAug利用预训练的生成模型进行精确的语义数据增强,并集成了一个即插即用的区域对比损失,以帮助模型关注任务相关的区域,从而提高泛化能力和任务成功率。在UR-5e、AgileX和Tien Kung 2.0三个机器人上进行了超过3.5万次rollout的真实世界实验。实验结果表明,RoboAug显著优于最先进的数据增强基线。在包含背景、干扰物和光照条件等多种组合的未见场景中评估泛化能力时,我们的方法相对于没有增强的基线取得了显著的提升。UR-5e上的成功率从0.09提高到0.47,AgileX上的成功率从0.16提高到0.60,Tien Kung 2.0上的成功率从0.19提高到0.67。这些结果突出了RoboAug在真实世界操作任务中的卓越泛化能力和有效性。
🔬 方法详解
问题定义:现有机器人操作学习方法泛化性差,难以适应真实世界复杂多变的场景。主要痛点在于依赖大量标注数据进行预训练,或者需要完美的物体检测作为前提,这在实际应用中难以满足。因此,如何在少量标注数据下提升机器人操作的泛化能力是一个关键问题。
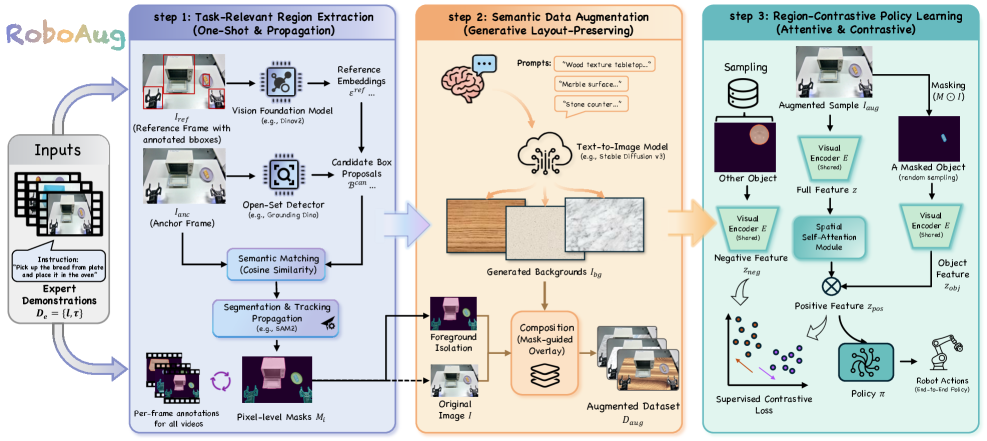
核心思路:RoboAug的核心思路是利用预训练的生成模型,基于单张标注图像生成大量具有语义一致性的增强数据。通过区域对比学习,引导模型关注任务相关的区域,从而提高模型对不同场景的适应能力,降低对大规模预训练和完美物体检测的依赖。
技术框架:RoboAug框架主要包含以下几个模块:1) 单张图像标注:仅需提供一张包含目标物体的图像,并标注其边界框。2) 语义数据增强:利用预训练的生成模型(如GAN或扩散模型),根据标注的边界框生成大量具有语义一致性的增强图像,模拟不同的背景、光照和干扰物。3) 区域对比学习:引入一个即插即用的区域对比损失,鼓励模型学习区分任务相关的区域和背景区域,从而提高模型对目标物体的关注度。4) 机器人操作策略学习:使用增强后的数据训练机器人操作策略,使其能够更好地泛化到未见场景。
关键创新:RoboAug的关键创新在于:1) 极低的标注成本:仅需单张图像标注即可生成大量增强数据。2) 区域对比学习:通过对比学习,引导模型关注任务相关的区域,提高模型的鲁棒性。3) 生成式数据增强:利用预训练的生成模型,生成具有语义一致性的增强数据,避免了传统数据增强方法的局限性。
关键设计:在语义数据增强方面,可以选择不同的预训练生成模型,如StyleGAN或扩散模型,并根据具体任务进行微调。区域对比损失的设计需要仔细考虑正负样本的选择,可以采用InfoNCE损失或类似的对比学习损失。此外,还需要调整生成模型的生成质量和多样性,以平衡数据增强的效果和模型的训练难度。
🖼️ 关键图片
📊 实验亮点
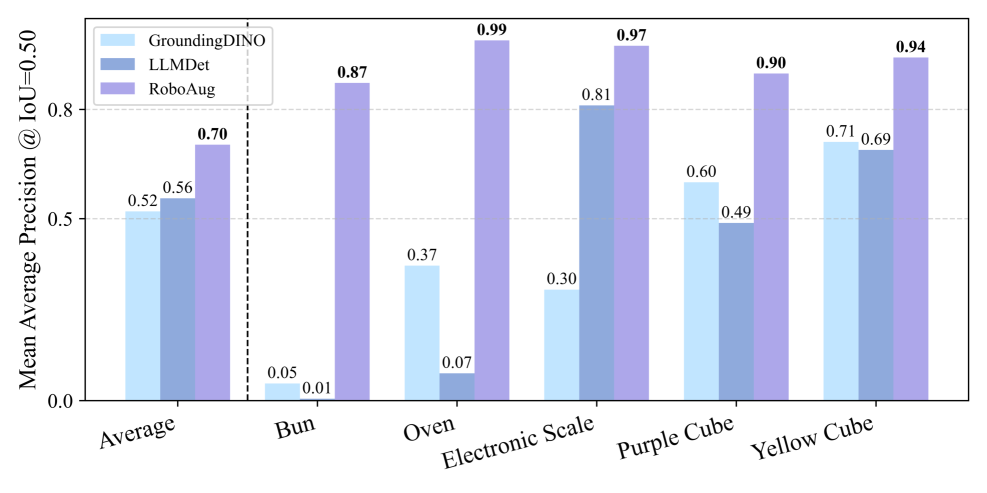
RoboAug在三个真实机器人平台(UR-5e、AgileX和Tien Kung 2.0)上进行了实验,结果表明其显著优于现有数据增强方法。在未见场景中,UR-5e上的成功率从0.09提高到0.47,AgileX上的成功率从0.16提高到0.60,Tien Kung 2.0上的成功率从0.19提高到0.67。这些结果充分证明了RoboAug在真实世界机器人操作任务中的有效性和泛化能力。
🎯 应用场景
RoboAug可广泛应用于各种机器人操作任务,例如工业自动化、家庭服务机器人、医疗机器人等。该方法降低了对大量标注数据的依赖,使得机器人能够更快地适应新的环境和任务,具有重要的实际应用价值和商业前景。未来,可以进一步研究如何将RoboAug与其他数据增强技术相结合,以进一步提高机器人的泛化能力。
📄 摘要(原文)
Enhancing the generalization capability of robotic learning to enable robots to operate effectively in diverse, unseen scenes is a fundamental and challenging problem. Existing approaches often depend on pretraining with large-scale data collection, which is labor-intensive and time-consuming, or on semantic data augmentation techniques that necessitate an impractical assumption of flawless upstream object detection in real-world scenarios. In this work, we propose RoboAug, a novel generative data augmentation framework that significantly minimizes the reliance on large-scale pretraining and the perfect visual recognition assumption by requiring only the bounding box annotation of a single image during training. Leveraging this minimal information, RoboAug employs pre-trained generative models for precise semantic data augmentation and integrates a plug-and-play region-contrastive loss to help models focus on task-relevant regions, thereby improving generalization and boosting task success rates. We conduct extensive real-world experiments on three robots, namely UR-5e, AgileX, and Tien Kung 2.0, spanning over 35k rollouts. Empirical results demonstrate that RoboAug significantly outperforms state-of-the-art data augmentation baselines. Specifically, when evaluating generalization capabilities in unseen scenes featuring diverse combinations of backgrounds, distractors, and lighting conditions, our method achieves substantial gains over the baseline without augmentation. The success rates increase from 0.09 to 0.47 on UR-5e, from 0.16 to 0.60 on AgileX, and from 0.19 to 0.67 on Tien Kung 2.0. These results highlight the superior generalization and effectiveness of RoboAug in real-world manipulation tasks. Our project is available at https://x-roboaug.github.io/.