WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL
作者: Zhennan Jiang, Shangqing Zhou, Yutong Jiang, Zefang Huang, Mingjie Wei, Yuhui Chen, Tianxing Zhou, Zhen Guo, Hao Lin, Quanlu Zhang, Yu Wang, Haoran Li, Chao Yu, Dongbin Zhao
分类: cs.RO, cs.AI
发布日期: 2026-02-15
备注: 21pages, 8 figures
💡 一句话要点
WoVR:利用世界模型作为可靠模拟器,通过强化学习后训练VLA策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 强化学习 视觉-语言-动作模型 机器人操作 策略优化 模拟器 幻觉控制
📋 核心要点
- 现有VLA模型依赖模仿学习,但强化学习因需大量真实交互而难以部署于物理机器人。
- WoVR通过显式调节RL与不完美世界模型的交互,控制幻觉,提升rollout稳定性。
- 实验表明,WoVR在LIBERO和真实机器人操作中显著提升了策略成功率,验证了其有效性。
📝 摘要(中文)
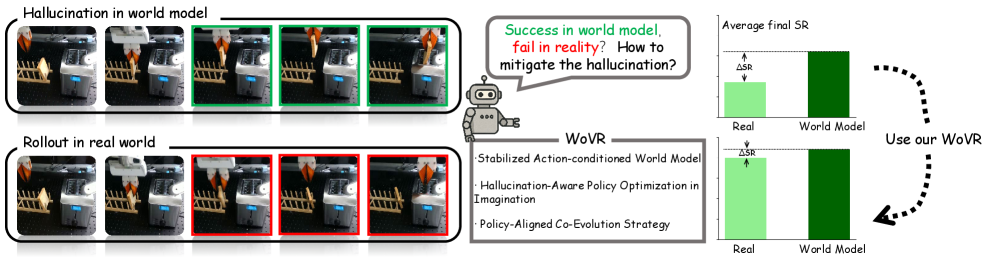
强化学习有望为视觉-语言-动作(VLA)模型解锁超越模仿学习的能力,但其对大量真实世界交互的需求阻碍了在物理机器人上的直接部署。现有工作尝试使用学习到的世界模型作为策略优化的模拟器,但闭环想象rollout不可避免地会受到幻觉和长时程误差累积的影响。这些误差不仅降低了视觉保真度,还会破坏优化信号,鼓励策略利用模型的不准确性而不是真正的任务进展。我们提出了WoVR,一个可靠的基于世界模型的强化学习框架,用于后训练VLA策略。WoVR没有假设一个忠实的世界模型,而是显式地调节RL如何与不完美的想象动力学交互。它通过可控的动作条件视频世界模型提高了rollout的稳定性,通过关键帧初始化rollout重塑了想象交互以减少有效误差深度,并通过世界模型-策略协同进化保持了策略-模拟器对齐。在LIBERO基准和真实机器人操作上的大量实验表明,WoVR能够实现稳定的长时程想象rollout和有效的策略优化,将平均LIBERO成功率从39.95%提高到69.2%(+29.3个百分点),真实机器人成功率从61.7%提高到91.7%(+30.0个百分点)。这些结果表明,当幻觉被显式控制时,学习到的世界模型可以作为强化学习的实用模拟器。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型在真实机器人上部署强化学习策略的难题。现有方法依赖于学习到的世界模型作为模拟器,但由于世界模型存在幻觉和长时程误差累积,导致策略优化效果不佳,甚至会利用模型的不准确性。
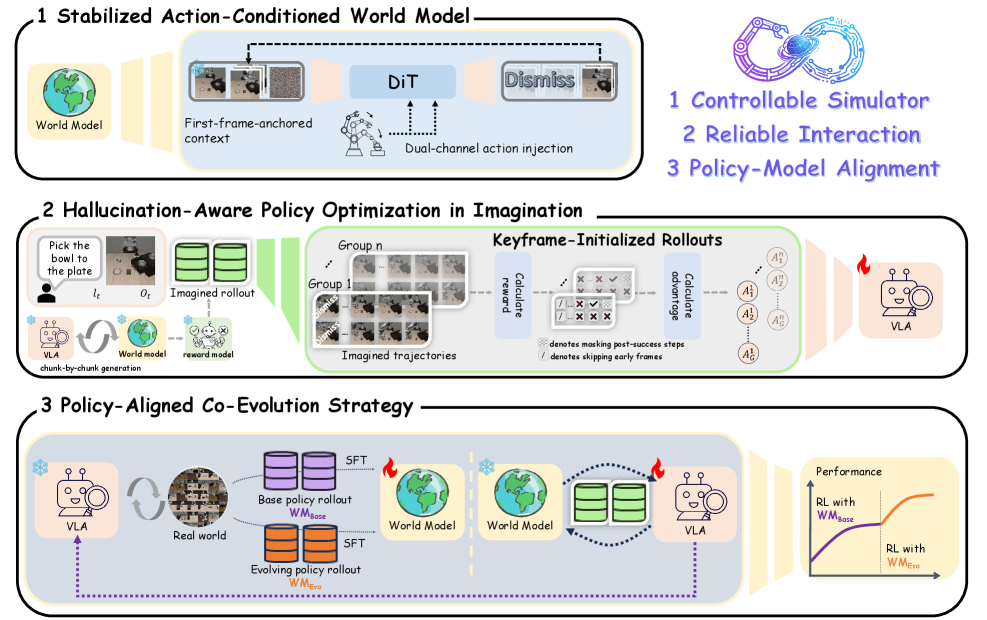
核心思路:WoVR的核心思路是不假设世界模型是完美的,而是通过显式地控制强化学习与不完美世界模型的交互,来提高策略优化的稳定性和有效性。具体来说,WoVR通过控制动作条件视频世界模型来提高rollout的稳定性,通过关键帧初始化rollout来减少有效误差深度,并通过世界模型-策略协同进化来保持策略-模拟器对齐。
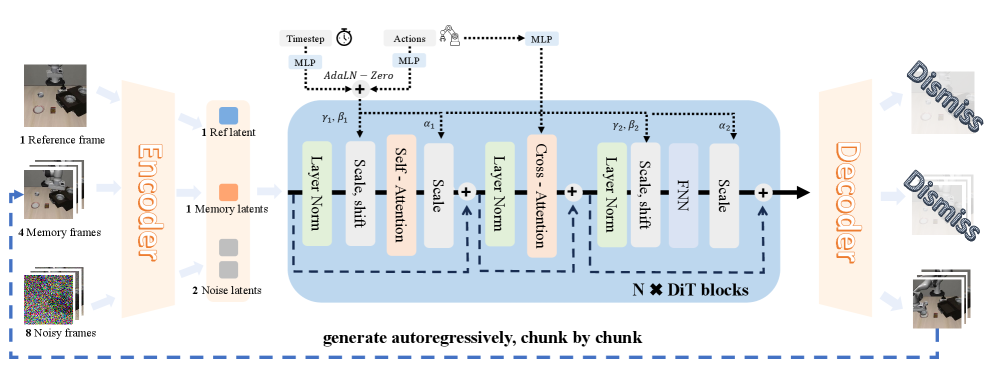
技术框架:WoVR框架包含三个主要组成部分:1) 可控的动作条件视频世界模型,用于生成稳定的想象rollout;2) 关键帧初始化rollout,用于减少误差累积;3) 世界模型-策略协同进化,用于保持策略与模拟器的一致性。整体流程是:首先,使用可控的动作条件视频世界模型生成想象环境;然后,使用关键帧初始化rollout在该环境中进行策略学习;最后,通过世界模型-策略协同进化不断优化世界模型和策略。
关键创新:WoVR的关键创新在于其显式地考虑了世界模型的不完美性,并通过一系列技术手段来缓解世界模型误差对策略优化的影响。与现有方法相比,WoVR不是试图构建一个完美的、完全真实的模拟器,而是专注于如何让强化学习算法在不完美的模拟器中也能有效地学习。
关键设计:WoVR的关键设计包括:1) 使用可控的动作条件视频世界模型,通过控制动作的幅度来限制世界模型的幻觉;2) 使用关键帧初始化rollout,定期将rollout重置到真实状态,以减少误差累积;3) 使用世界模型-策略协同进化,通过对抗训练的方式,让策略能够适应世界模型的误差,同时让世界模型能够更好地模拟真实环境。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
WoVR在LIBERO基准测试中,将平均成功率从39.95%提升至69.2%(+29.3个百分点)。在真实机器人实验中,成功率从61.7%提升至91.7%(+30.0个百分点)。这些结果表明,WoVR能够显著提高VLA策略在模拟环境和真实环境中的性能,验证了其有效性。
🎯 应用场景
WoVR框架具有广泛的应用前景,可用于训练各种机器人操作任务的VLA策略,例如物体抓取、放置、组装等。该研究的实际价值在于降低了强化学习在机器人领域的应用门槛,使得无需大量真实世界交互即可训练出高性能的机器人策略。未来,WoVR有望应用于更复杂的机器人任务,例如自动驾驶、智能制造等。
📄 摘要(原文)
Reinforcement learning (RL) promises to unlock capabilities beyond imitation learning for Vision-Language-Action (VLA) models, but its requirement for massive real-world interaction prevents direct deployment on physical robots. Recent work attempts to use learned world models as simulators for policy optimization, yet closed-loop imagined rollouts inevitably suffer from hallucination and long-horizon error accumulation. Such errors do not merely degrade visual fidelity; they corrupt the optimization signal, encouraging policies to exploit model inaccuracies rather than genuine task progress. We propose WoVR, a reliable world-model-based reinforcement learning framework for post-training VLA policies. Instead of assuming a faithful world model, WoVR explicitly regulates how RL interacts with imperfect imagined dynamics. It improves rollout stability through a controllable action-conditioned video world model, reshapes imagined interaction to reduce effective error depth via Keyframe-Initialized Rollouts, and maintains policy-simulator alignment through World Model-Policy co-evolution. Extensive experiments on LIBERO benchmarks and real-world robotic manipulation demonstrate that WoVR enables stable long-horizon imagined rollouts and effective policy optimization, improving average LIBERO success from 39.95% to 69.2% (+29.3 points) and real-robot success from 61.7% to 91.7% (+30.0 points). These results show that learned world models can serve as practical simulators for reinforcement learning when hallucination is explicitly controlled.