MOTIF: Learning Action Motifs for Few-shot Cross-Embodiment Transfer
作者: Heng Zhi, Wentao Tan, Lei Zhu, Fengling Li, Jingjing Li, Guoli Yang, Heng Tao Shen
分类: cs.RO, cs.AI
发布日期: 2026-02-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出MOTIF,通过学习动作模体实现少样本跨具身迁移
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨具身迁移 机器人学习 动作模体 少样本学习 流匹配 矢量量化
📋 核心要点
- 现有跨具身策略依赖共享-私有架构,私有参数容量有限,缺乏显式适应机制,限制了迁移性能。
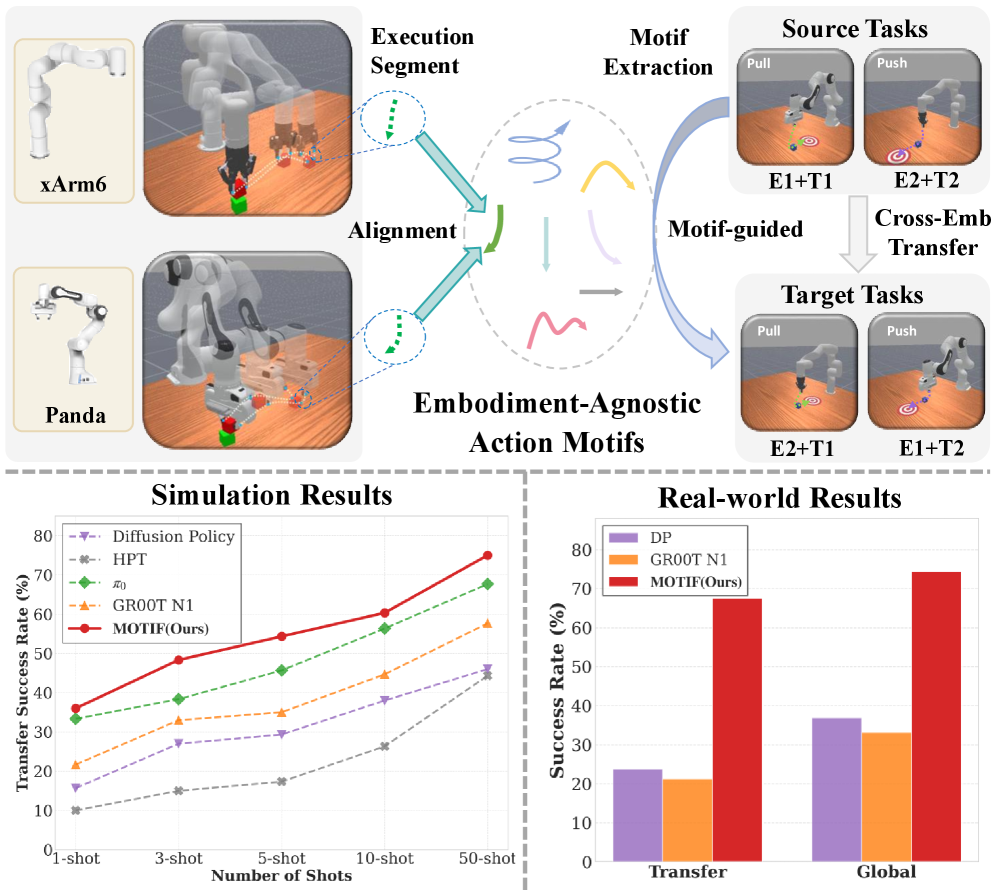
- MOTIF解耦具身无关的时空模式(动作模体)与异构动作数据,实现高效的少样本跨具身迁移。
- MOTIF在模拟和真实环境中显著优于基线,真实环境中性能提升高达43.7%,验证了其优越性。
📝 摘要(中文)
尽管视觉-语言-动作(VLA)模型在通用机器人学习方面取得了进展,但由于运动学异质性和收集足够真实世界演示数据以支持微调的高成本,跨具身迁移仍然具有挑战性。现有的跨具身策略通常依赖于共享-私有架构,但私有参数的容量有限,并且缺乏显式的适应机制。为了解决这些限制,我们引入了MOTIF,用于高效的少样本跨具身迁移,它将与具身无关的时空模式(称为动作模体)与异构动作数据解耦。具体来说,MOTIF首先通过矢量量化学习统一的模体,并结合进度感知对齐和具身对抗约束,以确保时间和跨具身的一致性。然后,我们设计了一个轻量级预测器,从实时输入中预测这些模体,以指导流匹配策略,并将它们与特定于机器人的状态融合,从而在新具身上实现动作生成。在模拟和真实环境中的评估验证了MOTIF的优越性,在少样本迁移场景中,其性能显著优于强大的基线,在模拟环境中提高了6.5%,在真实环境中提高了43.7%。代码可在https://github.com/buduz/MOTIF 获取。
🔬 方法详解
问题定义:论文旨在解决机器人学习中跨具身迁移的问题。现有方法,特别是基于共享-私有架构的方法,在处理不同机器人之间的运动学差异时存在局限性。私有参数的容量限制了模型对新具身的适应能力,并且缺乏明确的适应机制,导致在少样本情况下性能不佳。
核心思路:论文的核心思路是将动作分解为与具身无关的、可复用的时空模式,即“动作模体”。通过学习这些模体,模型可以更好地泛化到新的机器人具身上,而无需大量的特定于具身的数据。这种解耦的方式使得模型能够专注于学习通用的动作表示,从而提高迁移效率。
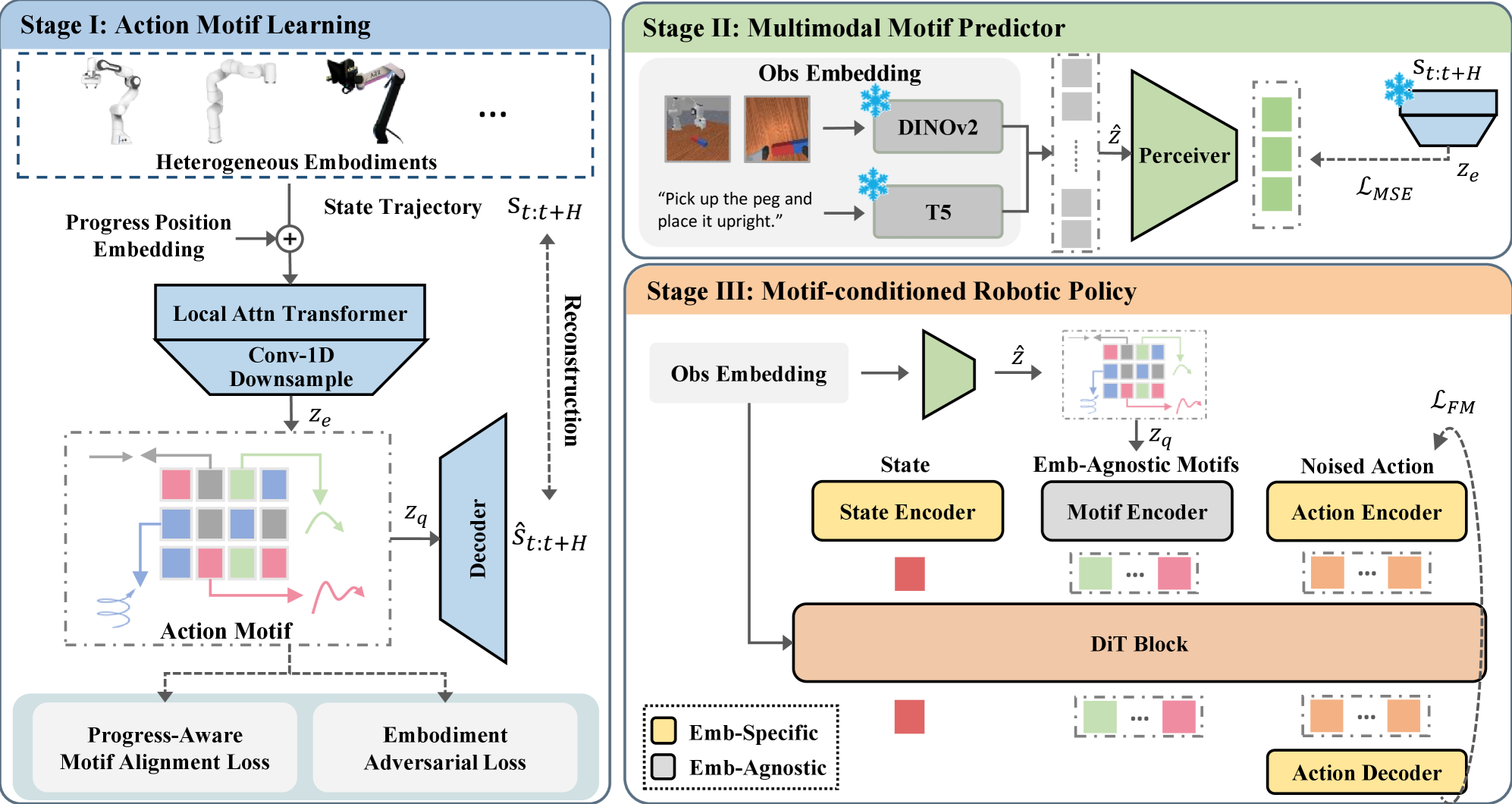
技术框架:MOTIF的整体框架包含以下几个主要模块:1) 统一模体学习模块:通过矢量量化学习动作模体,并使用进度感知对齐和具身对抗约束来保证时间和跨具身的一致性。2) 轻量级预测器:从实时输入中预测动作模体。3) 流匹配策略:将预测的模体与机器人特定状态融合,生成新的具身上的动作。
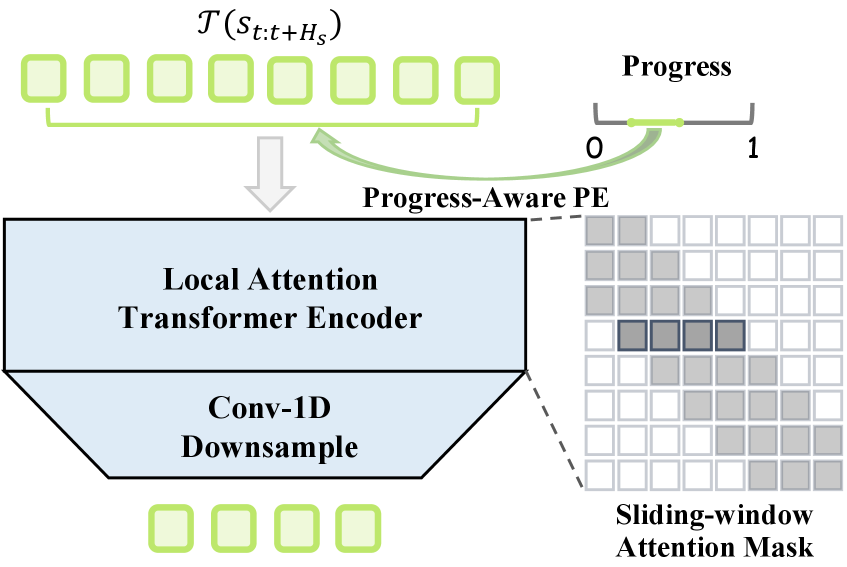
关键创新:该论文的关键创新在于提出了“动作模体”的概念,并将动作分解为与具身无关的、可复用的时空模式。这种解耦的方式使得模型能够更好地泛化到新的机器人具身上,而无需大量的特定于具身的数据。此外,论文还提出了进度感知对齐和具身对抗约束,以确保学习到的模体具有时间和跨具身的一致性。
关键设计:在统一模体学习模块中,使用了矢量量化技术来学习动作模体。进度感知对齐通过对齐不同动作的进度来提高时间一致性。具身对抗约束则通过对抗训练来减少不同具身之间的差异。轻量级预测器可以使用简单的神经网络结构,例如多层感知机。流匹配策略可以使用条件流模型,根据预测的模体和机器人状态生成动作。
🖼️ 关键图片
📊 实验亮点
MOTIF在少样本跨具身迁移任务中表现出色,在模拟环境中比现有方法提高了6.5%,在真实环境中提高了43.7%。这些结果表明,MOTIF能够有效地学习通用的动作表示,并将其迁移到新的机器人具身上,从而显著提高机器人的泛化能力和适应性。
🎯 应用场景
该研究成果可应用于各种机器人领域,例如工业自动化、服务机器人和医疗机器人。通过学习通用的动作模体,可以快速将机器人技能迁移到新的机器人平台上,降低开发成本,提高部署效率。此外,该方法还有助于实现人机协作,使机器人能够更好地理解和执行人类指令。
📄 摘要(原文)
While vision-language-action (VLA) models have advanced generalist robotic learning, cross-embodiment transfer remains challenging due to kinematic heterogeneity and the high cost of collecting sufficient real-world demonstrations to support fine-tuning. Existing cross-embodiment policies typically rely on shared-private architectures, which suffer from limited capacity of private parameters and lack explicit adaptation mechanisms. To address these limitations, we introduce MOTIF for efficient few-shot cross-embodiment transfer that decouples embodiment-agnostic spatiotemporal patterns, termed action motifs, from heterogeneous action data. Specifically, MOTIF first learns unified motifs via vector quantization with progress-aware alignment and embodiment adversarial constraints to ensure temporal and cross-embodiment consistency. We then design a lightweight predictor that predicts these motifs from real-time inputs to guide a flow-matching policy, fusing them with robot-specific states to enable action generation on new embodiments. Evaluations across both simulation and real-world environments validate the superiority of MOTIF, which significantly outperforms strong baselines in few-shot transfer scenarios by 6.5% in simulation and 43.7% in real-world settings. Code is available at https://github.com/buduz/MOTIF.