Symmetry-Aware Fusion of Vision and Tactile Sensing via Bilateral Force Priors for Robotic Manipulation
作者: Wonju Lee, Matteo Grimaldi, Tao Yu
分类: cs.RO, cs.CV
发布日期: 2026-02-14
备注: Accepted By ICRA2026
💡 一句话要点
提出基于双边力先验的对称感知视觉触觉融合方法,用于机器人操作中的插入任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉触觉融合 跨模态Transformer 双边力平衡 物理先验 插入任务 机器人学习
📋 核心要点
- 机器人操作中的插入任务对精度要求高,单纯视觉信息不足以应对复杂接触交互。
- 提出跨模态Transformer (CMT) 融合视觉和触觉信息,并引入基于物理的双边力平衡正则化,稳定触觉嵌入。
- 实验表明,该方法在插入成功率上超越现有融合方法,接近使用特权信息的性能,验证了触觉传感的重要性。
📝 摘要(中文)
机器人操作中的插入任务需要精确且富含接触的交互,而仅靠视觉信息难以实现。虽然触觉反馈直观上很有价值,但现有研究表明,简单的视觉-触觉融合往往无法带来持续的改进。本文提出了一种用于视觉-触觉融合的跨模态Transformer (CMT),通过结构化的自注意力和交叉注意力将腕部相机观测与触觉信号相结合。为了稳定触觉嵌入,我们进一步引入了一种基于物理信息的正则化方法,鼓励双边力平衡,反映了人类运动控制的原理。在TacSL基准测试上的实验表明,具有对称正则化的CMT实现了96.59%的插入成功率,超过了简单的融合和门控融合基线,并与特权的“腕部+接触力”配置(96.09%)非常接近。这些结果突出了两个核心见解:(i) 触觉传感对于精确对齐是不可或缺的,(ii) 原则性的多模态融合,通过基于物理信息的正则化进一步加强,释放了视觉和触觉的互补优势,在现实传感下接近了特权性能。
🔬 方法详解
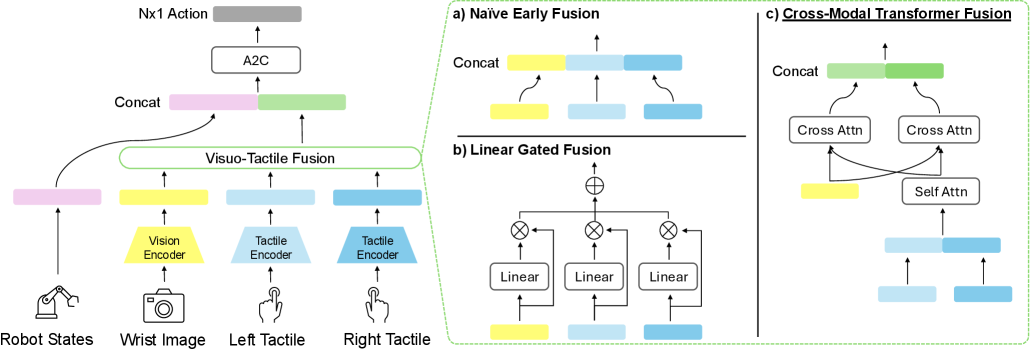
问题定义:机器人操作中的插入任务,需要精确控制机器人末端执行器,使其与目标物体进行紧密配合。单纯依靠视觉信息难以准确感知接触状态和力反馈,导致插入失败。现有的视觉-触觉融合方法,如简单的特征拼接或门控融合,无法有效利用两种模态信息的互补性,导致性能提升有限,甚至不如单独使用视觉信息。
核心思路:本文的核心思路是通过跨模态Transformer (CMT) 学习视觉和触觉特征之间的复杂关系,并利用物理先验知识(双边力平衡)对触觉嵌入进行正则化,从而提高融合模型的鲁棒性和准确性。CMT能够自适应地学习不同模态之间的权重,更好地利用视觉和触觉信息的互补性。双边力平衡正则化能够约束触觉嵌入,使其符合物理规律,从而提高触觉信息的可靠性。
技术框架:整体框架包括视觉特征提取模块、触觉特征提取模块、跨模态Transformer融合模块和双边力平衡正则化模块。首先,视觉特征提取模块从腕部相机图像中提取视觉特征。然后,触觉特征提取模块从触觉传感器信号中提取触觉特征。接着,跨模态Transformer融合模块将视觉特征和触觉特征进行融合,得到融合后的特征表示。最后,双边力平衡正则化模块对触觉嵌入进行正则化,使其符合物理规律。
关键创新:本文的关键创新在于以下两点:一是提出了跨模态Transformer (CMT) 用于视觉-触觉融合,能够自适应地学习不同模态之间的权重,更好地利用视觉和触觉信息的互补性。二是引入了基于物理信息的双边力平衡正则化,能够约束触觉嵌入,使其符合物理规律,从而提高触觉信息的可靠性。与现有方法的本质区别在于,本文的方法不仅考虑了视觉和触觉信息的融合,还考虑了物理先验知识的约束,从而提高了融合模型的鲁棒性和准确性。
关键设计:跨模态Transformer (CMT) 采用标准的Transformer结构,包括自注意力和交叉注意力机制。自注意力机制用于学习同一模态内的特征关系,交叉注意力机制用于学习不同模态之间的特征关系。双边力平衡正则化采用L2损失函数,约束触觉嵌入使其满足双边力平衡条件。具体来说,损失函数鼓励机器人末端执行器两侧的力大小相等,方向相反。实验中,Transformer的层数、注意力头数等超参数通过交叉验证进行选择。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的CMT模型在TacSL基准测试上取得了显著的性能提升,插入成功率达到96.59%,超过了简单的融合和门控融合基线。更重要的是,该模型的性能与使用特权信息(腕部+接触力)的配置(96.09%)非常接近,表明该方法能够有效地利用视觉和触觉信息的互补性,在现实传感条件下接近最优性能。
🎯 应用场景
该研究成果可应用于各种需要精确操作的机器人任务,例如精密装配、医疗手术、以及在复杂或遮挡环境中进行物体操作。通过融合视觉和触觉信息,并利用物理先验知识,可以提高机器人的操作精度和鲁棒性,使其能够更好地适应各种复杂环境,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Insertion tasks in robotic manipulation demand precise, contact-rich interactions that vision alone cannot resolve. While tactile feedback is intuitively valuable, existing studies have shown that naïve visuo-tactile fusion often fails to deliver consistent improvements. In this work, we propose a Cross-Modal Transformer (CMT) for visuo-tactile fusion that integrates wrist-camera observations with tactile signals through structured self- and cross-attention. To stabilize tactile embeddings, we further introduce a physics-informed regularization that encourages bilateral force balance, reflecting principles of human motor control. Experiments on the TacSL benchmark show that CMT with symmetry regularization achieves a 96.59% insertion success rate, surpassing naïve and gated fusion baselines and closely matching the privileged "wrist + contact force" configuration (96.09%). These results highlight two central insights: (i) tactile sensing is indispensable for precise alignment, and (ii) principled multimodal fusion, further strengthened by physics-informed regularization, unlocks complementary strengths of vision and touch, approaching privileged performance under realistic sensing.