Hierarchical Audio-Visual-Proprioceptive Fusion for Precise Robotic Manipulation
作者: Siyuan Li, Jiani Lu, Yu Song, Xianren Li, Bo An, Peng Liu
分类: cs.RO, cs.AI
发布日期: 2026-02-14
💡 一句话要点
提出一种层级音视频触觉融合框架,用于提升机器人操作的精确性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 多模态融合 音视频触觉融合 层级融合 扩散模型
📋 核心要点
- 现有机器人操作方法依赖视觉和触觉,在复杂环境中难以准确感知接触状态,限制了操作精度。
- 论文提出层级融合框架,利用声音线索增强感知,先以声音为条件融合视觉和触觉,再建模跨模态交互。
- 实验表明,该方法在真实机器人操作任务中优于现有方法,尤其在声音信息丰富的场景下提升显著。
📝 摘要(中文)
现有的机器人操作方法主要依赖视觉和触觉信息,但在部分可观察的真实环境中,难以推断与接触相关的交互状态。相比之下,声音线索自然地编码了接触过程中的丰富交互动态,但在当前的多模态融合文献中仍未得到充分利用。大多数多模态融合方法隐式地假设了模态之间具有同质的角色,因此设计了扁平且对称的融合结构。然而,这种假设不适用于声音信号,因为声音信号本质上是稀疏的且由接触驱动的。为了通过声音信息增强的感知来实现精确的机器人操作,我们提出了一种层级表示融合框架,该框架逐步整合音频、视觉和触觉信息。我们的方法首先以声音线索为条件来处理视觉和触觉表示,然后显式地建模高阶跨模态交互,以捕获模态之间的互补依赖关系。融合后的表示被基于扩散的策略利用,以直接从多模态观察中生成连续的机器人动作。端到端学习和层级融合结构的结合使策略能够利用任务相关的声音信息,同时减轻来自信息量较少的模态的干扰。所提出的方法已经在真实的机器人操作任务(包括液体倾倒和橱柜打开)上进行了评估。大量的实验结果表明,我们的方法始终优于最先进的多模态融合框架,尤其是在声音线索提供视觉观察不易获得的任务相关信息的场景中。此外,还进行了互信息分析,以解释声音线索在通过多模态融合进行机器人操作中的作用。
🔬 方法详解
问题定义:现有机器人操作方法主要依赖视觉和触觉信息,但在部分可观察的真实环境中,难以准确推断与接触相关的交互状态。例如,在遮挡或光照变化的情况下,视觉信息可能不足以判断物体是否发生接触,以及接触的力度和位置。同时,现有的多模态融合方法通常采用扁平结构,忽略了不同模态信息的重要性差异,特别是声音信号的稀疏性和接触驱动特性,导致融合效果不佳。
核心思路:论文的核心思路是利用声音信息增强机器人操作的感知能力,通过层级融合的方式,逐步整合音频、视觉和触觉信息。首先,利用声音信息作为条件,对视觉和触觉信息进行初步处理,提取与接触相关的特征。然后,显式地建模高阶跨模态交互,捕获模态之间的互补依赖关系,从而更准确地推断交互状态。这种层级融合的方式能够更好地利用任务相关的声音信息,同时减轻来自信息量较少的模态的干扰。
技术框架:整体框架包含三个主要模块:音频特征提取模块、视觉和触觉特征提取模块以及层级融合模块。音频特征提取模块负责从声音信号中提取与接触相关的特征,例如频率、能量等。视觉和触觉特征提取模块负责从视觉图像和触觉传感器数据中提取特征。层级融合模块首先以声音特征为条件,融合视觉和触觉特征,然后建模高阶跨模态交互,得到最终的融合表示。最后,将融合表示输入到基于扩散的策略网络中,生成连续的机器人动作。
关键创新:论文的关键创新在于提出了层级音视频触觉融合框架,该框架能够有效地利用声音信息增强机器人操作的感知能力。与现有的扁平融合方法相比,该框架能够更好地处理声音信号的稀疏性和接触驱动特性,从而更准确地推断交互状态。此外,论文还采用了基于扩散的策略网络,能够直接从多模态观察中生成连续的机器人动作,避免了传统方法中需要手动设计奖励函数的问题。
关键设计:在层级融合模块中,论文采用了注意力机制来建模高阶跨模态交互。具体来说,首先计算不同模态特征之间的注意力权重,然后利用注意力权重对特征进行加权融合。此外,论文还设计了一种新的损失函数,用于训练基于扩散的策略网络。该损失函数包括重构损失和策略损失,能够有效地提高策略网络的性能。
🖼️ 关键图片
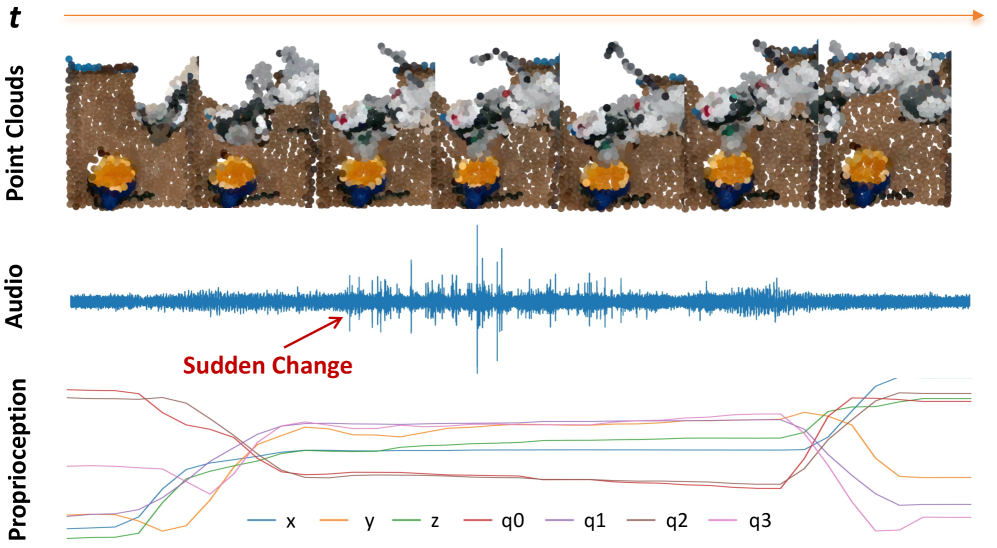
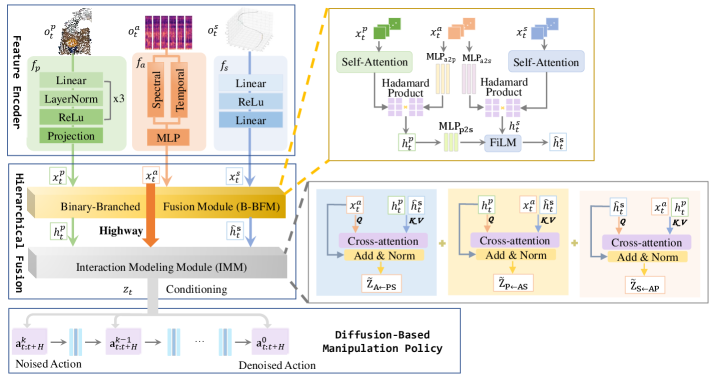

📊 实验亮点
实验结果表明,该方法在液体倾倒和橱柜打开等真实机器人操作任务中, consistently 优于 state-of-the-art 的多模态融合框架。尤其是在声音线索提供视觉观察不易获得的任务相关信息的场景中,性能提升更为显著。互信息分析也验证了声音线索在机器人操作中的重要作用。
🎯 应用场景
该研究成果可应用于各种需要精确操作的机器人任务,例如医疗手术、精密装配、家庭服务等。通过利用声音信息增强感知能力,机器人可以在复杂环境中更准确地完成任务,提高工作效率和安全性。未来,该方法有望推广到更多模态的融合,实现更智能、更可靠的机器人系统。
📄 摘要(原文)
Existing robotic manipulation methods primarily rely on visual and proprioceptive observations, which may struggle to infer contact-related interaction states in partially observable real-world environments. Acoustic cues, by contrast, naturally encode rich interaction dynamics during contact, yet remain underexploited in current multimodal fusion literature. Most multimodal fusion approaches implicitly assume homogeneous roles across modalities, and thus design flat and symmetric fusion structures. However, this assumption is ill-suited for acoustic signals, which are inherently sparse and contact-driven. To achieve precise robotic manipulation through acoustic-informed perception, we propose a hierarchical representation fusion framework that progressively integrates audio, vision, and proprioception. Our approach first conditions visual and proprioceptive representations on acoustic cues, and then explicitly models higher-order cross-modal interactions to capture complementary dependencies among modalities. The fused representation is leveraged by a diffusion-based policy to directly generate continuous robot actions from multimodal observations. The combination of end-to-end learning and hierarchical fusion structure enables the policy to exploit task-relevant acoustic information while mitigating interference from less informative modalities. The proposed method has been evaluated on real-world robotic manipulation tasks, including liquid pouring and cabinet opening. Extensive experiment results demonstrate that our approach consistently outperforms state-of-the-art multimodal fusion frameworks, particularly in scenarios where acoustic cues provide task-relevant information not readily available from visual observations alone. Furthermore, a mutual information analysis is conducted to interpret the effect of audio cues in robotic manipulation via multimodal fusion.