RynnBrain: Open Embodied Foundation Models
作者: Ronghao Dang, Jiayan Guo, Bohan Hou, Sicong Leng, Kehan Li, Xin Li, Jiangpin Liu, Yunxuan Mao, Zhikai Wang, Yuqian Yuan, Minghao Zhu, Xiao Lin, Yang Bai, Qian Jiang, Yaxi Zhao, Minghua Zeng, Junlong Gao, Yuming Jiang, Jun Cen, Siteng Huang, Liuyi Wang, Wenqiao Zhang, Chengju Liu, Jianfei Yang, Shijian Lu, Deli Zhao
分类: cs.RO
发布日期: 2026-02-13
备注: Homepage: https://alibaba-damo-academy.github.io/RynnBrain.github.io
💡 一句话要点
提出RynnBrain:一个用于具身智能的开源时空基础模型
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 基础模型 时空建模 物理推理 机器人导航
📋 核心要点
- 现有具身智能缺乏统一、物理合理的模型,难以整合感知、推理和规划。
- RynnBrain通过统一框架,强化自我中心理解、时空定位、物理推理和规划能力。
- RynnBrain在多个基准测试中大幅超越现有模型,并展现出强大的迁移潜力。
📝 摘要(中文)
本文介绍了RynnBrain,一个用于具身智能的开源时空基础模型。具身智能领域缺乏一个统一的、物理上合理的基础模型,该模型能够整合真实世界时空动态中的感知、推理和规划能力。RynnBrain通过统一的框架强化了四个核心能力:全面的自我中心理解、多样的时空定位、基于物理的推理和物理感知的规划。RynnBrain系列包含三个规模的基础模型(2B、8B和30B-A3B MoE)和四个针对下游具身任务进行后训练的变体(即RynnBrain-Nav、RynnBrain-Plan和RynnBrain-VLA)或复杂的空间推理任务(即RynnBrain-CoP)。在20个具身基准和8个通用视觉理解基准上的大量评估表明,RynnBrain基础模型显著优于现有的具身基础模型。后训练模型套件进一步证实了RynnBrain基础模型的两个关键潜力:(i)实现基于物理的推理和规划,以及(ii)作为强大的预训练骨干,可以有效地适应各种具身任务。
🔬 方法详解
问题定义:现有具身智能基础模型难以在真实世界的时空动态中统一感知、推理和规划,缺乏物理世界的先验知识,导致在复杂具身任务中表现受限。现有模型通常是针对特定任务设计的,泛化能力不足。
核心思路:RynnBrain的核心思路是构建一个统一的时空基础模型,通过大规模预训练学习物理世界的先验知识,并具备强大的感知、推理和规划能力。通过对模型进行后训练,使其能够更好地适应各种下游具身任务。
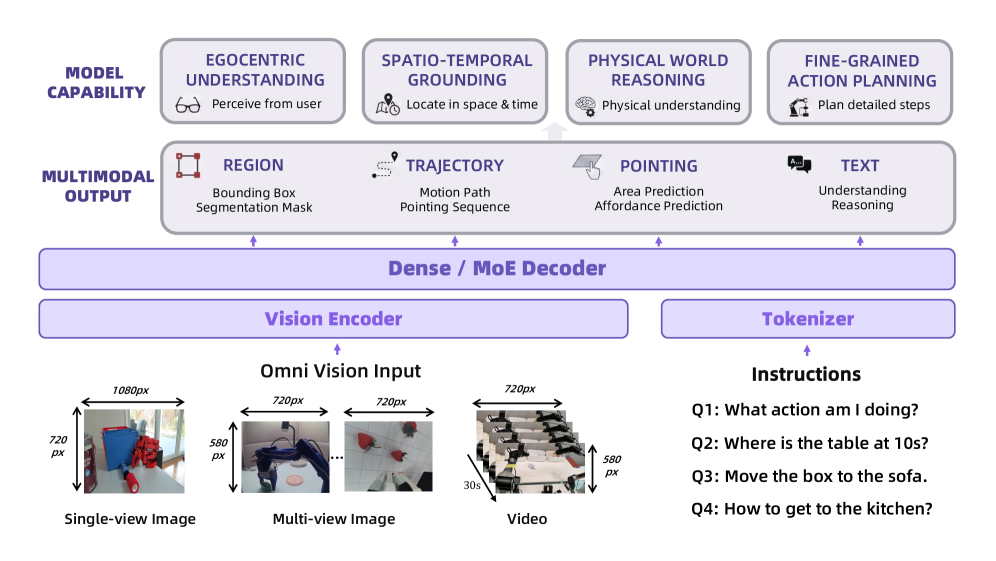
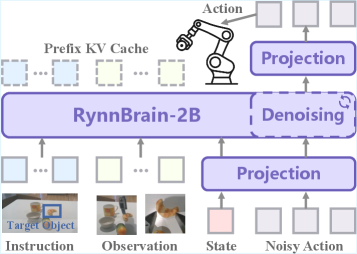
技术框架:RynnBrain的技术框架包含三个主要部分:(1) 大规模预训练:使用包含视觉、语言和动作数据的混合数据集对模型进行预训练,学习通用的时空表示。(2) 针对性后训练:针对不同的下游具身任务,使用特定任务的数据对模型进行后训练,提高模型在特定任务上的性能。(3) 模型变体:提供不同规模的模型(2B、8B、30B-A3B MoE)和针对不同任务优化的变体(RynnBrain-Nav、RynnBrain-Plan、RynnBrain-VLA、RynnBrain-CoP)。
关键创新:RynnBrain的关键创新在于其统一的时空建模框架,能够同时处理视觉、语言和动作信息,并学习物理世界的先验知识。此外,RynnBrain还提出了针对不同具身任务的后训练策略,提高了模型的泛化能力。
关键设计:RynnBrain使用了Transformer架构作为其核心建模单元。在预训练阶段,使用了对比学习和掩码语言建模等技术来学习通用的时空表示。在后训练阶段,使用了特定任务的损失函数来优化模型。具体的参数设置和网络结构细节未在摘要中详细描述,需要参考论文全文。
🖼️ 关键图片

📊 实验亮点
RynnBrain在20个具身基准测试和8个通用视觉理解基准测试中,显著优于现有的具身基础模型。具体性能数据和提升幅度未在摘要中给出,需要在论文全文中查找。后训练模型套件验证了RynnBrain在物理推理、规划和作为预训练骨干方面的潜力。
🎯 应用场景
RynnBrain可应用于机器人导航、物体操作、场景理解等多种具身智能任务。它能够帮助机器人更好地理解周围环境,进行更智能的决策和规划,从而提高机器人在现实世界中的自主性和适应性。未来,RynnBrain有望推动具身智能技术在工业自动化、智能家居、医疗健康等领域的广泛应用。
📄 摘要(原文)
Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.