AsyncVLA: An Asynchronous VLA for Fast and Robust Navigation on the Edge
作者: Noriaki Hirose, Catherine Glossop, Dhruv Shah, Sergey Levine
分类: cs.RO, cs.LG
发布日期: 2026-02-13
备注: 13 pages, 9 figures, 2 tables
💡 一句话要点
AsyncVLA:一种异步VLA框架,用于边缘端快速鲁棒导航
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 异步控制 视觉导航 边缘计算 机器人基础模型 视觉-语言模型 端到端微调 轨迹重加权
📋 核心要点
- 现有机器人基础模型计算成本高,推理延迟大,难以在动态环境中实时部署。
- AsyncVLA通过异步控制框架解耦语义推理和反应式执行,利用远程大模型和本地轻量级边缘适配器。
- 实验表明,AsyncVLA在真实导航任务中比现有方法成功率高40%,有效应对通信延迟。
📝 摘要(中文)
机器人基础模型通过利用互联网规模的视觉-语言表征实现了强大的泛化能力,但其巨大的计算成本造成了一个根本性的瓶颈:高推理延迟。在动态环境中,这种延迟破坏了控制回路,使得强大的模型对于实时部署而言是不安全的。我们提出了AsyncVLA,一个异步控制框架,它将语义推理与反应式执行解耦。受到分层控制的启发,AsyncVLA在一个远程工作站上运行一个大型基础模型以提供高层次的指导,而一个轻量级的、板载的边缘适配器则以高频率持续地细化动作。为了弥合这些异步流之间的领域差距,我们引入了一个端到端微调协议和一个轨迹重加权策略,该策略优先考虑动态交互。我们在具有高达6秒通信延迟的真实视觉导航任务上评估了我们的方法。AsyncVLA实现了比最先进的基线高40%的成功率,有效地弥合了大型模型的语义智能与边缘机器人所需的反应性之间的差距。
🔬 方法详解
问题定义:论文旨在解决机器人基础模型因计算量大导致的推理延迟问题,尤其是在动态环境中,高延迟会严重影响机器人的实时控制和安全性。现有方法难以兼顾大模型的语义理解能力和边缘计算的实时性。
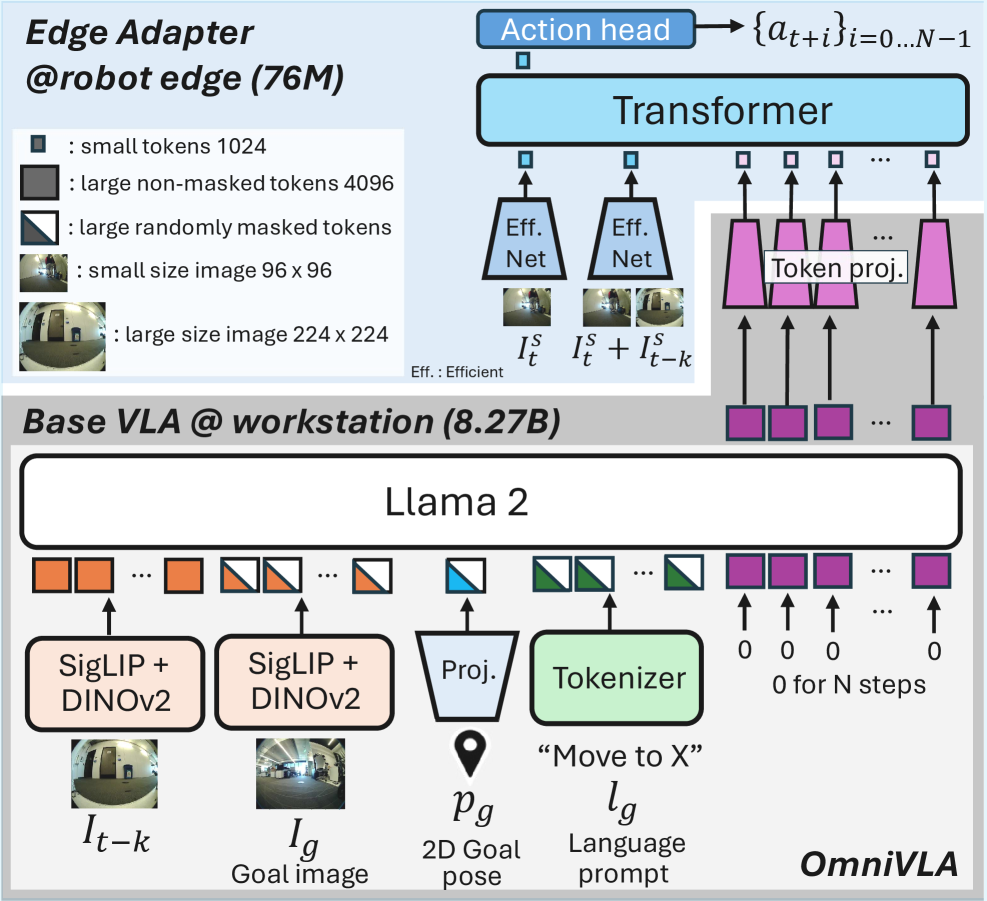
核心思路:论文的核心思路是将语义推理和反应式执行解耦,采用异步控制框架。具体来说,利用远程工作站运行大型视觉-语言模型(VLA)进行高层次的语义理解和决策,同时在机器人本地部署一个轻量级的边缘适配器,负责快速响应环境变化,细化动作。
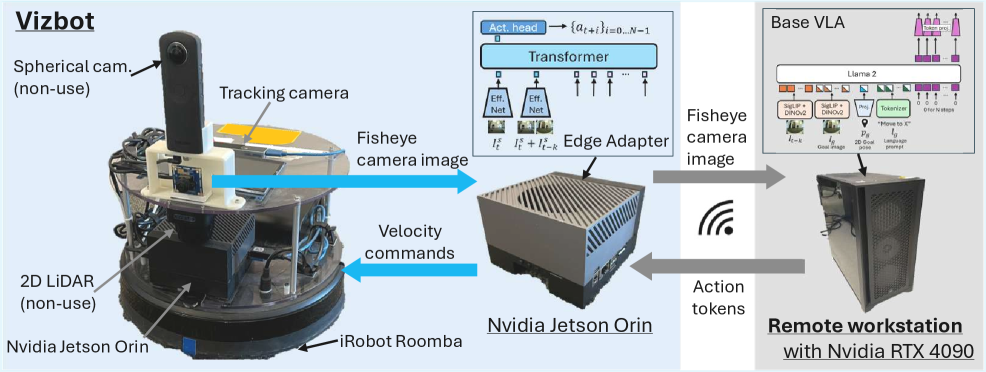
技术框架:AsyncVLA框架包含两个主要部分:远程VLA和本地边缘适配器。远程VLA负责接收环境信息,进行语义理解,并生成高层次的导航指令。这些指令通过网络传输到本地边缘适配器。边缘适配器接收到指令后,结合本地传感器数据,以高频率生成控制指令,驱动机器人运动。为了弥合远程VLA和本地边缘适配器之间的领域差距,论文还提出了端到端微调协议和轨迹重加权策略。
关键创新:AsyncVLA的关键创新在于其异步控制框架,它允许大型模型在远程运行,避免了本地计算资源的瓶颈。此外,端到端微调协议和轨迹重加权策略是弥合远程VLA和本地边缘适配器之间领域差距的关键。这种异步架构使得机器人能够同时利用大型模型的语义理解能力和边缘计算的实时性。
关键设计:论文提出了一个端到端微调协议,用于优化边缘适配器,使其能够更好地理解和执行远程VLA的指令。此外,还设计了一个轨迹重加权策略,该策略优先考虑动态交互,使得模型能够更好地适应环境变化。具体的网络结构和损失函数等细节在论文中进行了详细描述,但未在摘要中体现。
🖼️ 关键图片
📊 实验亮点
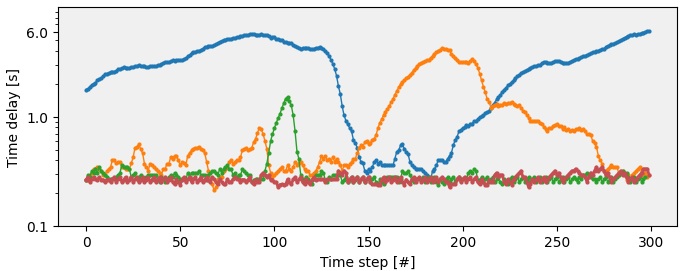
AsyncVLA在真实世界的视觉导航任务中取得了显著的性能提升。实验结果表明,AsyncVLA比最先进的基线方法成功率提高了40%。即使在高达6秒的通信延迟下,AsyncVLA仍然能够保持较高的导航成功率,证明了其鲁棒性和实时性。这些结果表明,AsyncVLA有效地弥合了大型模型的语义智能与边缘机器人所需的反应性之间的差距。
🎯 应用场景
AsyncVLA具有广泛的应用前景,例如在自动驾驶、物流机器人、搜救机器人等领域。该框架能够使机器人在复杂、动态的环境中进行安全、高效的导航。通过将计算密集型的语义理解任务卸载到远程服务器,AsyncVLA降低了对机器人本地计算资源的要求,使得更强大的模型能够部署在资源受限的平台上。未来,AsyncVLA可以进一步扩展到其他机器人任务,例如物体识别、操作等。
📄 摘要(原文)
Robotic foundation models achieve strong generalization by leveraging internet-scale vision-language representations, but their massive computational cost creates a fundamental bottleneck: high inference latency. In dynamic environments, this latency breaks the control loop, rendering powerful models unsafe for real-time deployment. We propose AsyncVLA, an asynchronous control framework that decouples semantic reasoning from reactive execution. Inspired by hierarchical control, AsyncVLA runs a large foundation model on a remote workstation to provide high-level guidance, while a lightweight, onboard Edge Adapter continuously refines actions at high frequency. To bridge the domain gap between these asynchronous streams, we introduce an end-to-end finetuning protocol and a trajectory re-weighting strategy that prioritizes dynamic interactions. We evaluate our approach on real-world vision-based navigation tasks with communication delays up to 6 seconds. AsyncVLA achieves a 40% higher success rate than state-of-the-art baselines, effectively bridging the gap between the semantic intelligence of large models and the reactivity required for edge robotics.