FlowHOI: Flow-based Semantics-Grounded Generation of Hand-Object Interactions for Dexterous Robot Manipulation
作者: Huajian Zeng, Lingyun Chen, Jiaqi Yang, Yuantai Zhang, Fan Shi, Peidong Liu, Xingxing Zuo
分类: cs.RO, cs.AI, cs.CV
发布日期: 2026-02-13
备注: Project Page: https://huajian-zeng.github.io/projects/flowhoi/
💡 一句话要点
FlowHOI:基于流模型生成语义驱动的手-物交互,用于灵巧机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱五:交互与反应 (Interaction & Reaction) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手-物交互 机器人操作 流匹配 语义驱动 3D场景理解 运动生成 视觉语言动作
📋 核心要点
- 现有的视觉-语言-动作(VLA)模型在长时程、接触丰富的任务中表现不佳,因为缺乏对手-物交互(HOI)结构的显式表示。
- FlowHOI通过两阶段流匹配框架生成语义驱动的HOI序列,解耦几何抓取和语义操作,并利用运动-文本对齐损失进行语义 grounding。
- 实验表明,FlowHOI在动作识别精度和物理模拟成功率上优于现有方法,并实现了真实机器人的操作演示。
📝 摘要(中文)
本文提出FlowHOI,一个两阶段的流匹配框架,用于生成语义驱动、时间上连贯的手-物交互(HOI)序列。该序列包括手部姿态、物体姿态和手-物接触状态,以第一人称视角观察、语言指令和3D高斯溅射(3DGS)场景重建为条件。FlowHOI将以几何为中心的手部抓取与以语义为中心的操作解耦,后者以紧凑的3D场景tokens为条件,并采用运动-文本对齐损失,从而在物理场景布局和语言指令中对生成的交互进行语义 grounding。为了解决高保真HOI监督数据稀缺的问题,本文引入了一个重建流程,从大规模第一人称视频中恢复对齐的手-物轨迹和网格,从而为鲁棒生成提供HOI先验。在GRAB和HOT3D基准测试中,FlowHOI实现了最高的动作识别精度,并且比最强的基于扩散的基线提高了1.7倍的物理模拟成功率,同时实现了40倍的推理速度提升。进一步在四个灵巧操作任务上进行了真实机器人执行演示,证明了将生成的HOI表示重新定向到真实机器人执行流程的可行性。
🔬 方法详解
问题定义:论文旨在解决机器人灵巧操作中,现有VLA模型难以处理长时程、接触丰富的任务的问题。现有方法缺乏对手-物交互(HOI)结构的显式表示,导致生成的动作序列难以验证和迁移到不同机器人上。此外,高保真HOI监督数据的稀缺也限制了模型的性能。
核心思路:论文的核心思路是提出一个两阶段的流匹配框架FlowHOI,将手部抓取(几何中心)和物体操作(语义中心)解耦。通过3D场景tokens和运动-文本对齐损失,实现生成的HOI序列在物理场景和语言指令上的语义 grounding。同时,利用大规模第一人称视频重建HOI数据,提供HOI先验。
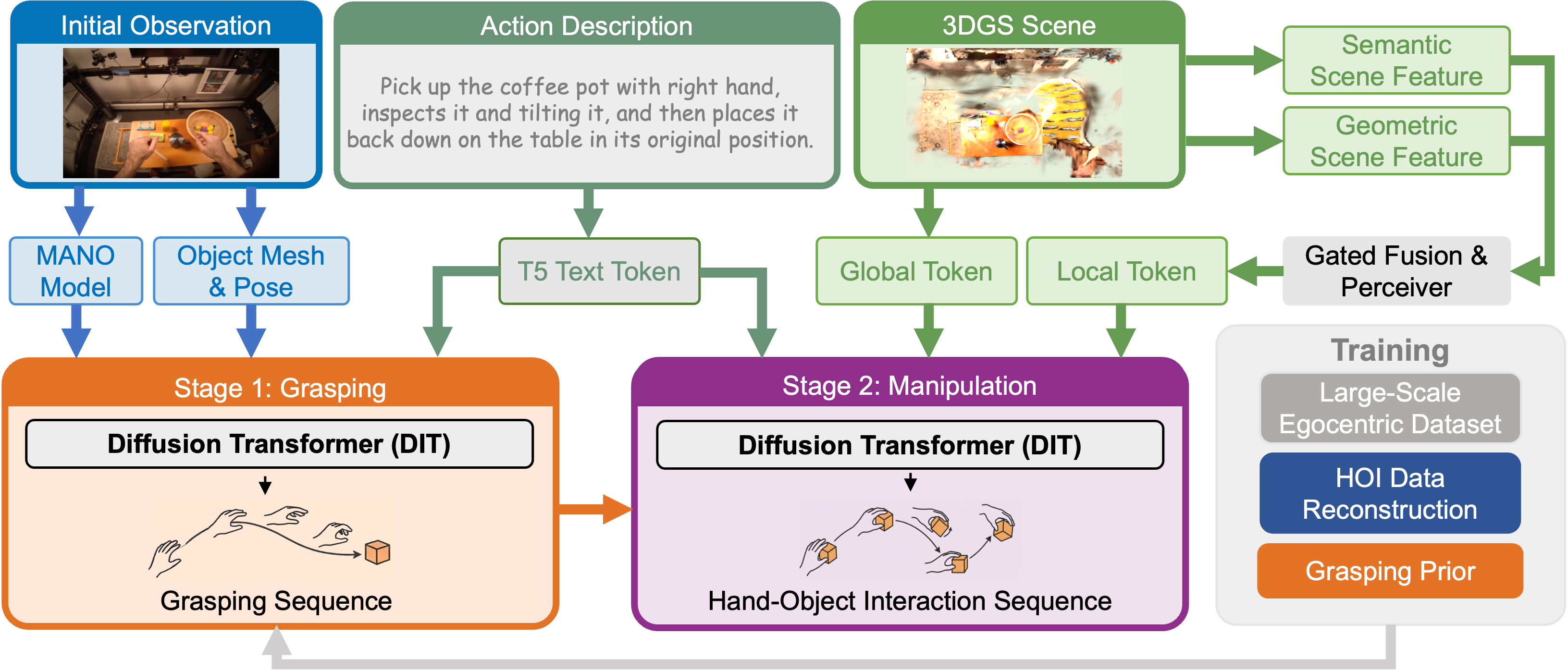
技术框架:FlowHOI包含两个主要阶段:第一阶段是几何抓取阶段,负责生成初始的手部姿态和物体姿态。第二阶段是语义操作阶段,以第一阶段的结果、3D场景tokens和语言指令为条件,生成最终的HOI序列。整个框架利用流匹配模型进行序列生成,保证时间上的连贯性。
关键创新:论文的关键创新在于:1) 提出了一种新的HOI表示方法,显式地建模了手部、物体和接触状态之间的关系。2) 提出了两阶段的流匹配框架,解耦了几何抓取和语义操作,提高了生成HOI序列的质量和可控性。3) 利用大规模第一人称视频重建HOI数据,缓解了数据稀缺问题。
关键设计:FlowHOI的关键设计包括:1) 使用3D高斯溅射(3DGS)进行场景重建,提取紧凑的3D场景tokens。2) 采用运动-文本对齐损失,鼓励生成的HOI序列与语言指令在语义上对齐。3) 设计了一个数据重建pipeline,从大规模第一人称视频中恢复对齐的手-物轨迹和网格。4) 使用流匹配模型进行序列生成,保证时间上的连贯性。
🖼️ 关键图片

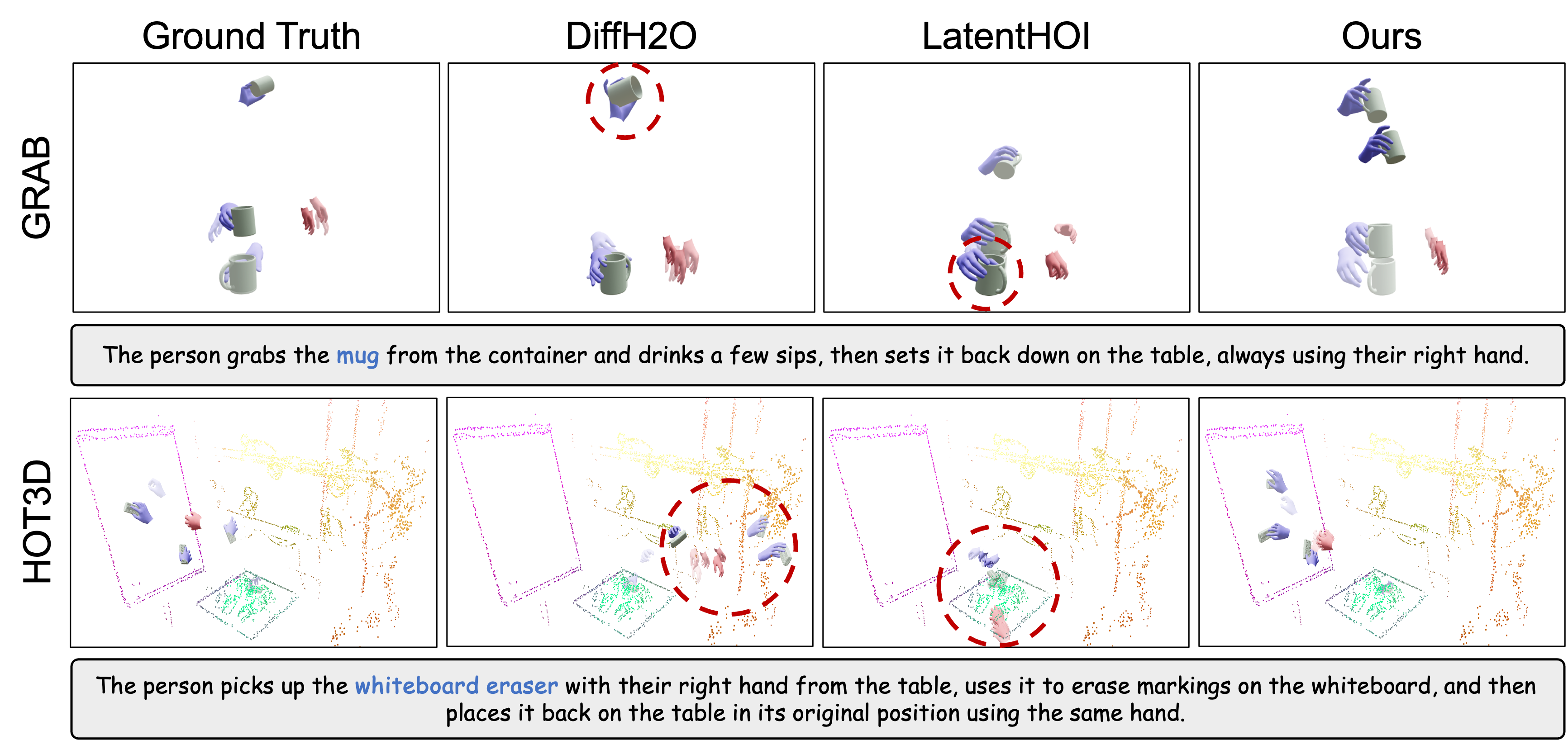
📊 实验亮点
FlowHOI在GRAB和HOT3D基准测试中取得了显著的成果。在动作识别精度上达到了最高水平,并且比最强的基于扩散的基线提高了1.7倍的物理模拟成功率,同时实现了40倍的推理速度提升。此外,FlowHOI还在四个灵巧操作任务上进行了真实机器人执行演示,验证了其在实际应用中的可行性。
🎯 应用场景
FlowHOI在机器人灵巧操作领域具有广泛的应用前景,例如家庭服务机器人、工业机器人等。它可以帮助机器人理解人类的指令,并生成合理的、符合物理规律的操作序列,从而完成复杂的任务。此外,FlowHOI生成的HOI表示可以用于机器人技能学习和迁移,提高机器人的泛化能力。
📄 摘要(原文)
Recent vision-language-action (VLA) models can generate plausible end-effector motions, yet they often fail in long-horizon, contact-rich tasks because the underlying hand-object interaction (HOI) structure is not explicitly represented. An embodiment-agnostic interaction representation that captures this structure would make manipulation behaviors easier to validate and transfer across robots. We propose FlowHOI, a two-stage flow-matching framework that generates semantically grounded, temporally coherent HOI sequences, comprising hand poses, object poses, and hand-object contact states, conditioned on an egocentric observation, a language instruction, and a 3D Gaussian splatting (3DGS) scene reconstruction. We decouple geometry-centric grasping from semantics-centric manipulation, conditioning the latter on compact 3D scene tokens and employing a motion-text alignment loss to semantically ground the generated interactions in both the physical scene layout and the language instruction. To address the scarcity of high-fidelity HOI supervision, we introduce a reconstruction pipeline that recovers aligned hand-object trajectories and meshes from large-scale egocentric videos, yielding an HOI prior for robust generation. Across the GRAB and HOT3D benchmarks, FlowHOI achieves the highest action recognition accuracy and a 1.7$\times$ higher physics simulation success rate than the strongest diffusion-based baseline, while delivering a 40$\times$ inference speedup. We further demonstrate real-robot execution on four dexterous manipulation tasks, illustrating the feasibility of retargeting generated HOI representations to real-robot execution pipelines.