Learning Native Continuation for Action Chunking Flow Policies
作者: Yufeng Liu, Hang Yu, Juntu Zhao, Bocheng Li, Di Zhang, Mingzhu Li, Wenxuan Wu, Yingdong Hu, Junyuan Xie, Junliang Guo, Dequan Wang, Yang Gao
分类: cs.RO, cs.AI
发布日期: 2026-02-13
备注: Project page: https://lyfeng001.github.io/Legato/
💡 一句话要点
Legato:面向动作分块流程策略的连续性学习方法,提升VLA模型平滑性和效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作 动作分块 连续性学习 流程策略 机器人操作
📋 核心要点
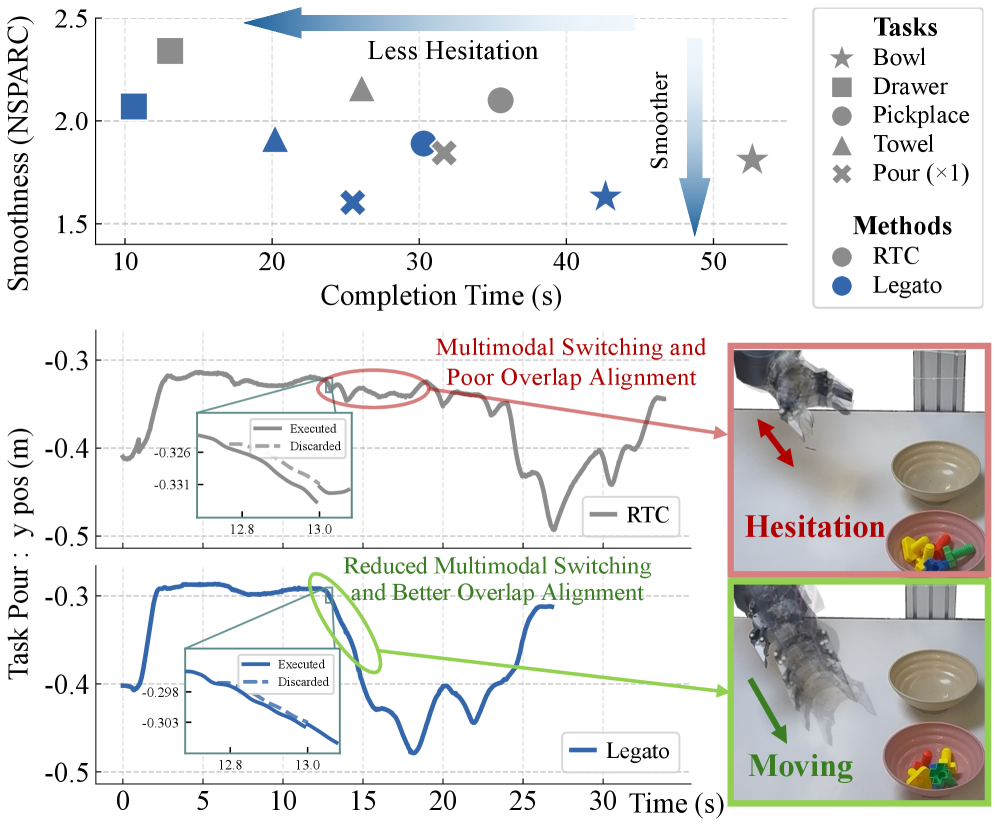
- 现有动作分块方法在视觉语言动作模型中存在块边界不连续问题,导致轨迹不平滑和多模态切换。
- Legato通过在训练时引入连续性学习,利用schedule-shaped混合初始化去噪过程,并重塑流程动态,保证训练和推理一致性。
- 实验结果表明,Legato在真实操作任务中显著提升了轨迹平滑性和任务完成时间,优于现有实时分块方法。
📝 摘要(中文)
动作分块技术使视觉语言动作(VLA)模型能够实时运行,但简单的分块执行常在块边界处产生不连续性。实时分块(RTC)缓解了这个问题,但它位于策略外部,导致虚假的多模态切换和非内在平滑的轨迹。我们提出了Legato,一种用于动作分块流程VLA策略的训练时连续性方法。具体来说,Legato从一个由已知动作和噪声组成的schedule-shaped混合中初始化去噪过程,使模型暴露于部分动作信息。此外,Legato重塑了学习到的流程动态,以确保去噪过程在训练和推理过程中在每步指导下保持一致。Legato还在训练期间使用随机schedule条件,以支持不同的推理延迟并实现可控的平滑性。实验表明,Legato产生更平滑的轨迹,并减少执行期间的虚假多模态切换,从而减少犹豫并缩短任务完成时间。广泛的真实世界实验表明,Legato在五个操作任务中始终优于RTC,在轨迹平滑性和任务完成时间方面均实现了约10%的改进。
🔬 方法详解
问题定义:论文旨在解决视觉语言动作(VLA)模型中使用动作分块技术时,由于块边界的不连续性导致的轨迹不平滑、多模态切换频繁以及任务完成效率低下的问题。现有的实时分块(RTC)方法虽然可以缓解这些问题,但它作为策略的外部组件,无法从根本上解决轨迹内在平滑性的问题。
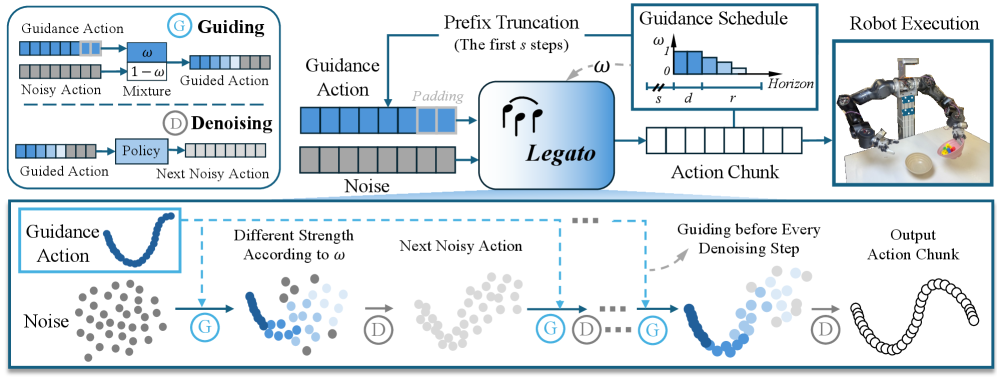
核心思路:Legato的核心思路是在训练阶段就让模型学习动作之间的连续性。通过引入一个schedule-shaped的混合动作和噪声作为去噪过程的初始化,使模型在训练时就能够感知到部分动作信息,从而学习到更平滑的动作过渡。同时,通过重塑学习到的流程动态,保证训练和推理过程中的一致性,避免了推理时出现不连续的情况。
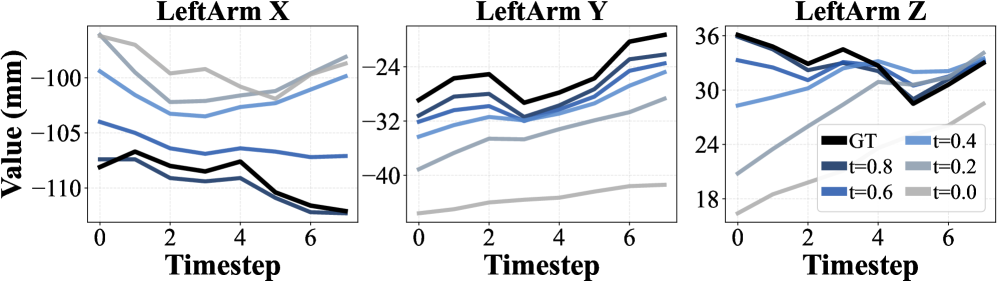
技术框架:Legato方法主要包含以下几个关键模块:1) 动作分块流程策略:作为基础的VLA模型,负责生成动作序列。2) Schedule-shaped混合初始化:将已知动作和噪声按照一定的schedule混合,作为去噪过程的初始状态。3) 流程动态重塑:通过特定的损失函数,重塑学习到的流程动态,保证训练和推理过程的一致性。4) 随机Schedule条件:在训练过程中引入随机的schedule条件,以支持不同的推理延迟,并实现可控的平滑性。
关键创新:Legato的关键创新在于其训练时连续性学习方法。与传统的先分块再优化的方法不同,Legato直接在训练阶段就让模型学习动作之间的连续性,从而避免了块边界处的不连续问题。此外,通过流程动态重塑和随机schedule条件,Legato能够保证训练和推理过程的一致性,并支持不同的推理延迟。
关键设计:Legato的关键设计包括:1) Schedule函数的设计:Schedule函数决定了已知动作和噪声的混合比例,需要根据具体的任务进行调整。2) 流程动态重塑的损失函数:需要设计合适的损失函数,以保证学习到的流程动态能够产生平滑的动作过渡。3) 随机Schedule条件的采样策略:需要设计合理的采样策略,以保证模型能够适应不同的推理延迟。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Legato在五个真实世界操作任务中均优于RTC方法,在轨迹平滑性和任务完成时间方面均实现了约10%的改进。这表明Legato能够有效地减少虚假的多模态切换,并生成更平滑的动作轨迹,从而显著提升VLA模型的性能。
🎯 应用场景
Legato方法可广泛应用于机器人操作、自动驾驶、游戏AI等领域。通过提升VLA模型的动作连贯性和效率,可以使机器人更流畅地完成复杂任务,提高自动驾驶系统的安全性,并创造更智能的游戏AI。该研究对于提升人机交互体验和推动智能体在复杂环境中的应用具有重要意义。
📄 摘要(原文)
Action chunking enables Vision Language Action (VLA) models to run in real time, but naive chunked execution often exhibits discontinuities at chunk boundaries. Real-Time Chunking (RTC) alleviates this issue but is external to the policy, leading to spurious multimodal switching and trajectories that are not intrinsically smooth. We propose Legato, a training-time continuation method for action-chunked flow-based VLA policies. Specifically, Legato initializes denoising from a schedule-shaped mixture of known actions and noise, exposing the model to partial action information. Moreover, Legato reshapes the learned flow dynamics to ensure that the denoising process remains consistent between training and inference under per-step guidance. Legato further uses randomized schedule condition during training to support varying inference delays and achieve controllable smoothness. Empirically, Legato produces smoother trajectories and reduces spurious multimodal switching during execution, leading to less hesitation and shorter task completion time. Extensive real-world experiments show that Legato consistently outperforms RTC across five manipulation tasks, achieving approximately 10% improvements in both trajectory smoothness and task completion time.