TRANS: Terrain-aware Reinforcement Learning for Agile Navigation of Quadruped Robots under Social Interactions
作者: Wei Zhu, Irfan Tito Kurniawan, Ye Zhao, Mistuhiro Hayashibe
分类: cs.RO
发布日期: 2026-02-13
💡 一句话要点
提出TRANS框架,实现四足机器人在复杂地形和社交环境下的敏捷导航
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 强化学习 地形感知 社交导航 敏捷运动
📋 核心要点
- 现有四足机器人导航方法难以兼顾地形感知、整体运动约束和社交互动环境。
- TRANS框架通过两阶段训练,分别学习地形运动和社交导航,最终集成实现复杂环境下的敏捷导航。
- 实验表明,TRANS在不平坦地形和社交环境中优于现有方法,并具有良好的sim-to-real迁移能力。
📝 摘要(中文)
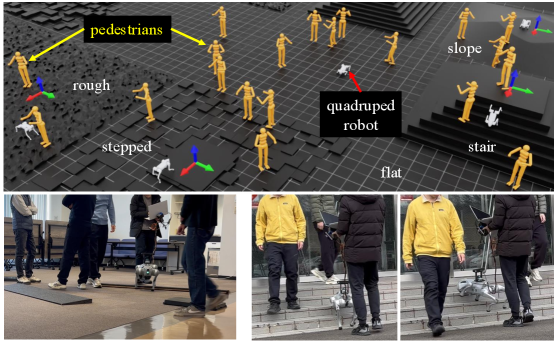
本研究提出TRANS:一种用于四足机器人在非结构化地形上进行社交导航的、具有地形感知能力的强化学习框架。传统的四足导航通常将运动规划与步态控制分离,忽略了整体约束和地形感知。端到端方法更集成,但需要高频传感,这通常会带来噪声且计算成本高昂。此外,大多数现有方法假设静态环境,限制了其在人群环境中的应用。为了解决这些局限性,我们提出了一个包含三个DRL流程的两阶段训练框架。(1) TRANS-Loco采用非对称Actor-Critic (AC)模型进行四足运动,无需显式地形或接触观测即可穿越不平坦地形。(2) TRANS-Nav应用对称AC框架进行社交导航,在差速驱动运动学下,直接将转换后的激光雷达数据映射到自我代理的动作。(3) 统一的流程TRANS集成了TRANS-Loco和TRANS-Nav,支持在不平坦和社交互动环境中进行地形感知的四足导航。与运动和社交导航基线的全面基准测试证明了TRANS的有效性。硬件实验进一步证实了其在sim-to-real迁移方面的潜力。
🔬 方法详解
问题定义:现有四足机器人导航方法主要存在三个痛点:一是将运动规划和步态控制分离,忽略了整体运动约束和地形感知;二是端到端方法依赖高频传感器数据,计算成本高且易受噪声影响;三是大多假设环境静态,无法应用于动态的社交互动场景。因此,需要一种能够适应复杂地形、考虑整体运动约束,并在动态社交环境中实现敏捷导航的四足机器人控制方法。
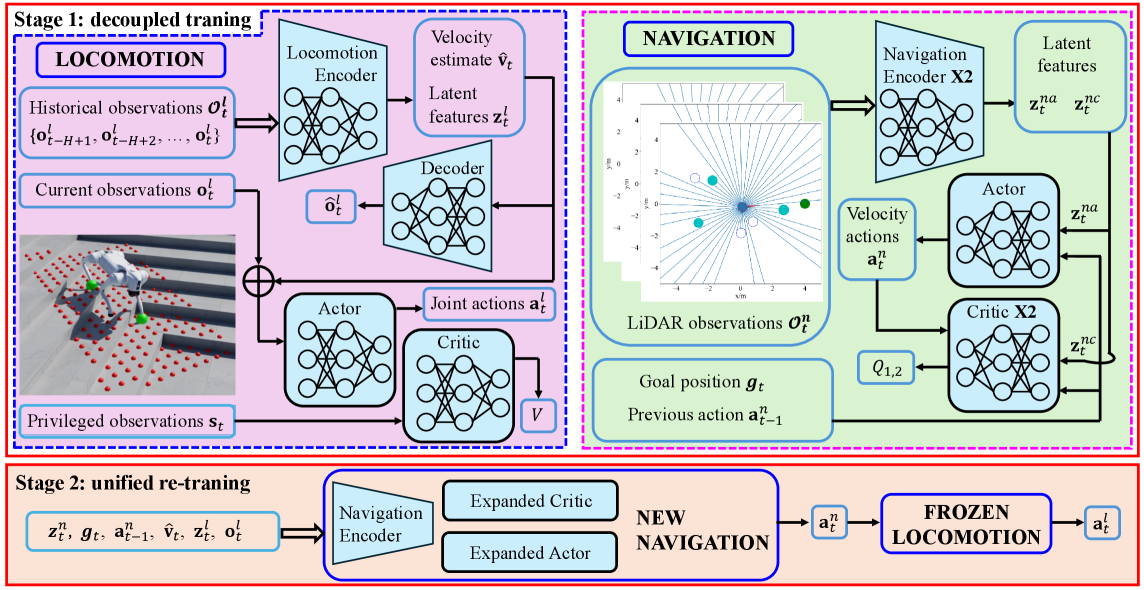
核心思路:TRANS框架的核心思路是将复杂的导航任务分解为两个阶段:首先,通过TRANS-Loco学习在复杂地形上的稳健运动控制;然后,通过TRANS-Nav学习在社交环境中的导航策略。最后,将两者集成,实现地形感知和社交感知的敏捷导航。这种分阶段训练的方式降低了学习难度,提高了模型的泛化能力。
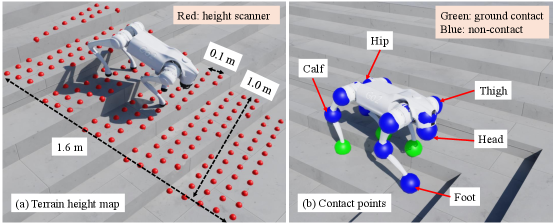
技术框架:TRANS框架包含两个主要阶段:TRANS-Loco和TRANS-Nav。TRANS-Loco阶段使用非对称Actor-Critic模型,训练四足机器人在不平坦地形上的运动能力,无需显式地形或接触观测。TRANS-Nav阶段使用对称Actor-Critic模型,将激光雷达数据映射到机器人的运动指令,实现社交导航。最后,TRANS将TRANS-Loco和TRANS-Nav集成,实现整体的导航控制。
关键创新:TRANS的关键创新在于其两阶段训练框架和地形感知的运动控制方法。通过分阶段训练,降低了学习难度,提高了模型的泛化能力。TRANS-Loco采用非对称Actor-Critic模型,无需显式地形信息即可实现稳健的运动控制,降低了对传感器精度的要求。
关键设计:TRANS-Loco使用非对称Actor-Critic模型,Critic网络接收更多环境信息,Actor网络只接收少量状态信息,从而提高模型的鲁棒性。TRANS-Nav使用对称Actor-Critic模型,直接将激光雷达数据映射到机器人的运动指令。损失函数的设计考虑了运动的平滑性和安全性,避免碰撞和剧烈运动。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TRANS框架在不平坦地形和社交环境中均优于现有方法。与基线方法相比,TRANS在导航成功率和运动效率方面均有显著提升。硬件实验验证了TRANS框架具有良好的sim-to-real迁移能力,能够在真实环境中稳定运行。
🎯 应用场景
TRANS框架可应用于搜索救援、物流运输、巡检等领域。在复杂地形和人群环境中,四足机器人能够凭借TRANS框架实现自主导航,完成特定任务。该研究成果有助于提升四足机器人在实际场景中的应用价值,并为未来人机协作提供技术支持。
📄 摘要(原文)
This study introduces TRANS: Terrain-aware Reinforcement learning for Agile Navigation under Social interactions, a deep reinforcement learning (DRL) framework for quadrupedal social navigation over unstructured terrains. Conventional quadrupedal navigation typically separates motion planning from locomotion control, neglecting whole-body constraints and terrain awareness. On the other hand, end-to-end methods are more integrated but require high-frequency sensing, which is often noisy and computationally costly. In addition, most existing approaches assume static environments, limiting their use in human-populated settings. To address these limitations, we propose a two-stage training framework with three DRL pipelines. (1) TRANS-Loco employs an asymmetric actor-critic (AC) model for quadrupedal locomotion, enabling traversal of uneven terrains without explicit terrain or contact observations. (2) TRANS-Nav applies a symmetric AC framework for social navigation, directly mapping transformed LiDAR data to ego-agent actions under differential-drive kinematics. (3) A unified pipeline, TRANS, integrates TRANS-Loco and TRANS-Nav, supporting terrain-aware quadrupedal navigation in uneven and socially interactive environments. Comprehensive benchmarks against locomotion and social navigation baselines demonstrate the effectiveness of TRANS. Hardware experiments further confirm its potential for sim-to-real transfer.