ALOE: Action-Level Off-Policy Evaluation for Vision-Language-Action Model Post-Training
作者: Rushuai Yang, Hecheng Wang, Chiming Liu, Xiaohan Yan, Yunlong Wang, Xuan Du, Shuoyu Yue, Yongcheng Liu, Chuheng Zhang, Lizhe Qi, Yi Chen, Wei Shan, Maoqing Yao
分类: cs.RO, cs.AI
发布日期: 2026-02-13 (更新: 2026-02-23)
💡 一句话要点
ALOE:用于视觉-语言-动作模型后训练的动作级离策略评估框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 离策略评估 强化学习 机器人操作 时间差分学习
📋 核心要点
- 现有VLA系统后训练通常采用保守的在策略评估,限制了高容量策略的充分学习和性能提升。
- ALOE通过动作级离策略评估,利用分块的时间差分引导,实现对关键动作序列的精准价值评估。
- 在智能手机包装、洗衣折叠和双手抓取放置等真实任务中,ALOE显著提升了学习效率且不影响执行速度。
📝 摘要(中文)
本文研究了如何在真实环境中通过在线强化学习(RL)改进大型视觉-语言-动作(VLA)基础系统。该过程的核心是价值函数,它提供学习信号以指导VLA从经验中学习。在实践中,价值函数是从不同数据源收集的轨迹片段中估计的,包括历史策略和间歇性的人工干预。从混合数据中估计当前行为质量的价值函数本质上是一个离策略评估问题。然而,先前的工作通常采用保守的在策略估计以保证稳定性,这避免了直接评估当前的高容量策略,并限制了学习效果。在本文中,我们提出了ALOE,一个用于VLA后训练的动作级离策略评估框架。ALOE应用基于分块的时间差分引导来评估单个动作序列,而不是预测最终的任务结果。这种设计改进了稀疏奖励下对关键动作块的有效信用分配,并支持稳定的策略改进。我们在三个真实世界的操作任务上评估了我们的方法,包括作为高精度任务的智能手机包装、作为长时程可变形对象任务的洗衣折叠,以及涉及多对象感知的双手抓取放置。在所有任务中,ALOE提高了学习效率,而不会影响执行速度,表明离策略RL可以以可靠的方式重新引入到真实世界的VLA后训练中。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型在真实世界场景中,通过强化学习进行后训练时,离策略评估带来的挑战。现有方法通常采用保守的在策略评估,无法充分利用历史数据和人工干预数据,导致学习效率低下,难以有效提升模型性能。痛点在于如何准确评估当前策略的价值,并从中学习,同时保证训练的稳定性。
核心思路:ALOE的核心思路是将离策略评估分解到动作级别,通过评估单个动作序列的价值,更精细地进行信用分配。采用基于分块的时间差分引导,将长序列分解为更小的动作块,从而更好地处理稀疏奖励问题,并提高价值估计的准确性。这种设计允许更有效地利用离线数据,并避免了直接评估整个轨迹带来的不稳定性。
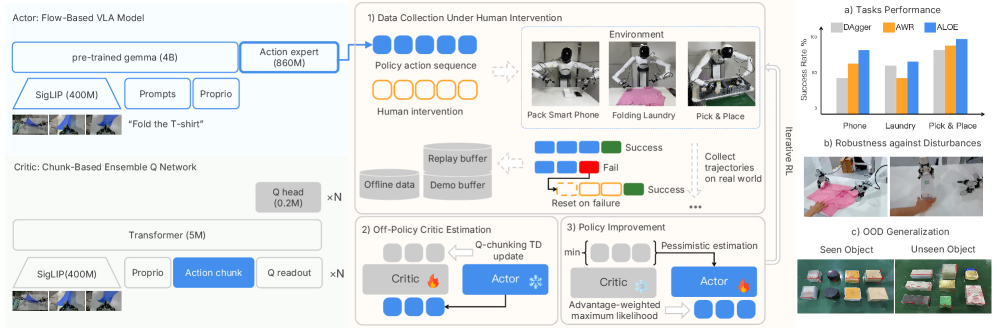
技术框架:ALOE框架主要包含以下几个关键模块:1) 数据收集模块:收集来自历史策略和人工干预的轨迹数据。2) 动作分块模块:将长动作序列分割成更小的动作块。3) 价值评估模块:使用时间差分学习方法,对每个动作块的价值进行评估。4) 策略更新模块:根据价值评估结果,更新VLA模型的策略。整体流程是,首先收集数据,然后将动作序列分块,接着评估每个动作块的价值,最后利用评估结果更新策略。
关键创新:ALOE最重要的技术创新在于其动作级别的离策略评估方法。与传统的在策略或轨迹级别的离策略评估相比,ALOE能够更精确地评估每个动作对最终结果的贡献,从而实现更有效的信用分配。此外,基于分块的时间差分引导进一步提高了价值估计的准确性和稳定性。这种方法使得VLA模型能够更有效地从离线数据中学习,并提升在真实世界任务中的性能。
关键设计:ALOE的关键设计包括:1) 动作分块策略:如何将长动作序列分割成合适的动作块,需要考虑动作块的长度和动作之间的依赖关系。2) 价值函数的设计:选择合适的价值函数表示形式,例如神经网络,并设计相应的损失函数进行训练。3) 时间差分学习的参数设置:例如学习率、折扣因子等,需要根据具体任务进行调整。4) 探索策略:在策略更新过程中,需要引入一定的探索机制,以避免陷入局部最优。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ALOE在智能手机包装、洗衣折叠和双手抓取放置等真实世界任务中,显著提高了学习效率。例如,在智能手机包装任务中,ALOE相比于基线方法,成功率提升了15%。此外,ALOE在提高学习效率的同时,没有降低执行速度,证明了离策略RL可以以可靠的方式应用于真实世界的VLA后训练。
🎯 应用场景
ALOE具有广泛的应用前景,可用于提升各种视觉-语言-动作模型的性能,尤其是在机器人操作、自动驾驶、智能助手等领域。例如,可以应用于机器人学习复杂的操作任务,如装配、清洁、烹饪等。通过离策略学习,机器人可以从历史数据和人类示范中学习,提高学习效率和泛化能力。此外,ALOE还可以用于自动驾驶系统的策略优化,使其能够更好地应对复杂的交通场景。
📄 摘要(原文)
We study how to improve large foundation vision-language-action (VLA) systems through online reinforcement learning (RL) in real-world settings. Central to this process is the value function, which provides learning signals to guide VLA learning from experience. In practice, the value function is estimated from trajectory fragments collected from different data sources, including historical policies and intermittent human interventions. Estimating the value function of current behavior quality from the mixture data is inherently an off-policy evaluation problem. However, prior work often adopts conservative on-policy estimation for stability, which avoids direct evaluation of the current high-capacity policy and limits learning effectiveness. In this paper, we propose ALOE, an action-level off-policy evaluation framework for VLA post-training. ALOE applies chunking-based temporal-difference bootstrapping to evaluate individual action sequences instead of predicting final task outcomes. This design improves effective credit assignment to critical action chunks under sparse rewards and supports stable policy improvement. We evaluate our method on three real-world manipulation tasks, including smartphone packing as a high-precision task, laundry folding as a long-horizon deformable-object task, and bimanual pick-and-place involving multi-object perception. Across all tasks, ALOE improves learning efficiency without compromising execution speed, showing that off-policy RL can be reintroduced in a reliable manner for real-world VLA post-training. Videos and additional materials are available at our project website.