Beyond Imitation: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models
作者: Liangzhi Shi, Shuaihang Chen, Feng Gao, Yinuo Chen, Kang Chen, Tonghe Zhang, Hongzhi Zang, Weinan Zhang, Chao Yu, Yu Wang
分类: cs.RO
发布日期: 2026-02-13 (更新: 2026-02-16)
💡 一句话要点
提出基于强化学习的Sim-Real协同训练框架RL-Co,提升VLA模型在真实机器人操作任务中的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Sim-Real协同训练 强化学习 视觉-语言-动作模型 机器人操作 仿真环境 监督微调 泛化能力 数据效率
📋 核心要点
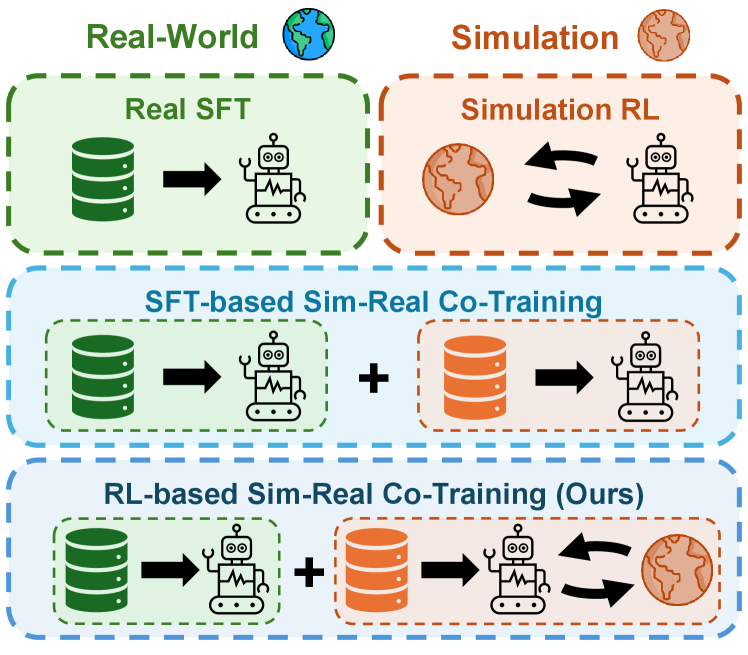
- 现有Sim-Real协同训练方法依赖监督微调,将仿真视为静态数据源,缺乏大规模闭环交互。
- 提出RL-Co框架,利用强化学习在仿真环境中进行策略优化,并结合真实数据监督损失,保持真实世界能力。
- 实验表明,RL-Co在真实机器人操作任务中,相比现有方法,成功率显著提升,泛化能力更强。
📝 摘要(中文)
本文提出了一种基于强化学习(RL)的Sim-Real协同训练(RL-Co)框架,旨在利用交互式仿真来增强视觉-语言-动作(VLA)模型的训练,同时保持其在真实世界的性能。该方法采用通用的两阶段设计:首先,使用真实和模拟数据的混合进行监督微调(SFT)来预热策略;然后,在仿真环境中利用强化学习进行微调,并添加一个辅助的真实数据监督损失,以稳定策略并减轻灾难性遗忘。在四个真实世界的桌面操作任务上,使用OpenVLA和$π_{0.5}$两种VLA架构评估了该框架,结果表明,与仅在真实数据上微调和基于SFT的协同训练相比,该框架实现了持续的改进,OpenVLA的真实世界成功率提高了24%,$π_{0.5}$提高了20%。除了更高的成功率,RL协同训练还增强了对未见过的任务变化的泛化能力,并显著提高了真实世界的数据效率,为利用仿真来增强真实机器人部署提供了一条实用且可扩展的途径。
🔬 方法详解
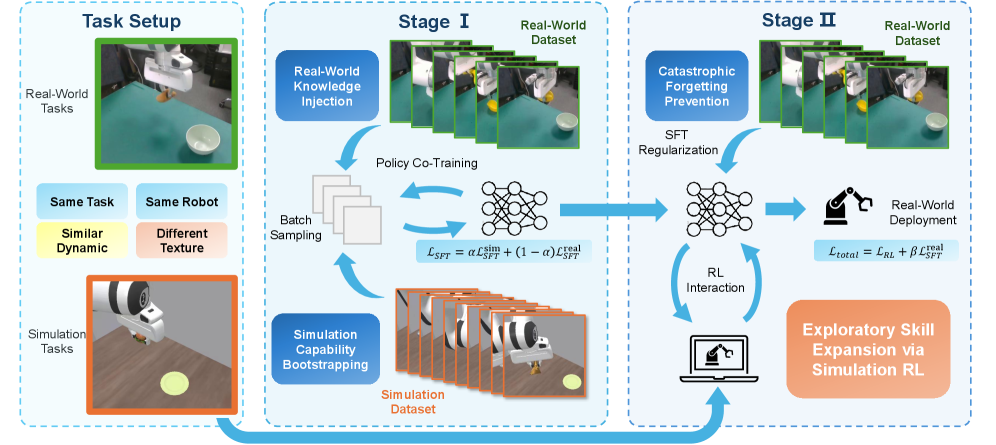
问题定义:现有VLA模型训练依赖昂贵的真实机器人演示数据,而Sim-Real协同训练虽然能利用仿真数据,但现有方法主要采用监督微调(SFT),将仿真数据视为静态数据集,无法充分利用仿真环境中的交互性,导致模型在真实环境中的性能提升有限,泛化能力不足。
核心思路:本文的核心思路是利用强化学习(RL)在仿真环境中进行策略优化,充分挖掘仿真环境的交互潜力。同时,为了避免在仿真环境中过度优化导致模型在真实环境中的性能下降(即负迁移),引入真实数据的监督损失作为锚定,以保持模型在真实环境中的性能。
技术框架:RL-Co框架采用两阶段训练流程: 1. 预训练阶段:使用真实数据和仿真数据的混合数据集,通过监督微调(SFT)预训练VLA模型,使其具备初步的操作能力。 2. 协同训练阶段:在仿真环境中,使用强化学习算法(具体算法未知)对预训练模型进行微调,以提升其在仿真环境中的性能。同时,为了防止模型在仿真环境中过度优化,引入一个辅助的真实数据监督损失,以约束模型的参数更新,使其不会偏离真实数据的分布。
关键创新:RL-Co框架的关键创新在于将强化学习引入Sim-Real协同训练,充分利用仿真环境的交互性,克服了传统SFT方法的局限性。通过结合强化学习和真实数据监督损失,实现了在提升模型性能的同时,保持其在真实环境中的泛化能力。
关键设计: * 混合数据集:预训练阶段使用真实数据和仿真数据的混合数据集,比例未知。 * 强化学习算法:具体使用的强化学习算法未知。 * 真实数据监督损失:具体形式未知,但其作用是约束模型参数,使其不会过度拟合仿真数据。 * VLA架构:使用了OpenVLA和$π_{0.5}$两种代表性的VLA架构。
🖼️ 关键图片

📊 实验亮点
在四个真实世界的桌面操作任务上,RL-Co框架在OpenVLA架构上实现了24%的真实世界成功率提升,在$π_{0.5}$架构上实现了20%的提升,显著优于仅在真实数据上微调和基于SFT的协同训练方法。此外,RL-Co还展现出更强的泛化能力和更高的数据效率。
🎯 应用场景
该研究成果可应用于各种需要机器人进行复杂操作的场景,例如智能制造、仓储物流、家庭服务等。通过利用仿真环境进行高效训练,可以降低机器人部署成本,提高其在真实环境中的适应性和智能化水平,加速机器人在各行业的普及应用。
📄 摘要(原文)
Simulation offers a scalable and low-cost way to enrich vision-language-action (VLA) training, reducing reliance on expensive real-robot demonstrations. However, most sim-real co-training methods rely on supervised fine-tuning (SFT), which treats simulation as a static source of demonstrations and does not exploit large-scale closed-loop interaction. Consequently, real-world gains and generalization are often limited. In this paper, we propose an \underline{\textit{RL}}-based sim-real \underline{\textit{Co}}-training \modify{(RL-Co)} framework that leverages interactive simulation while preserving real-world capabilities. Our method follows a generic two-stage design: we first warm-start the policy with SFT on a mixture of real and simulated demonstrations, then fine-tune it with reinforcement learning in simulation while adding an auxiliary supervised loss on real-world data to anchor the policy and mitigate catastrophic forgetting. We evaluate our framework on four real-world tabletop manipulation tasks using two representative VLA architectures, OpenVLA and $π_{0.5}$, and observe consistent improvements over real-only fine-tuning and SFT-based co-training, including +24% real-world success on OpenVLA and +20% on $π_{0.5}$. Beyond higher success rates, RL co-training yields stronger generalization to unseen task variations and substantially improved real-world data efficiency, providing a practical and scalable pathway for leveraging simulation to enhance real-robot deployment.