CRAFT: Adapting VLA Models to Contact-rich Manipulation via Force-aware Curriculum Fine-tuning
作者: Yike Zhang, Yaonan Wang, Xinxin Sun, Kaizhen Huang, Zhiyuan Xu, Junjie Ji, Zhengping Che, Jian Tang, Jingtao Sun
分类: cs.RO
发布日期: 2026-02-13
💡 一句话要点
CRAFT:通过力感知的课程微调,使VLA模型适应接触式操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 接触式操作 视觉-语言-动作模型 力感知 课程学习 机器人控制
📋 核心要点
- 现有VLA模型在接触式操作中面临挑战,原因是视觉语言信息与关键的力反馈信号之间存在不平衡,导致控制不稳定。
- CRAFT框架通过力感知的课程微调,在训练初期优先关注力信号,逐步融合多模态信息,从而解决上述问题。
- 实验结果表明,CRAFT能够显著提高接触式操作任务的成功率,并具备良好的泛化能力,适用于不同的VLA架构。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在使机器人执行通用指令方面表现出强大的能力,但它们在接触式操作任务中表现不佳,这类任务的成功需要精确的对齐、稳定的接触维持和对可变形物体的有效处理。一个根本的挑战来自于高熵的视觉和语言输入与低熵但关键的力信号之间的不平衡,这通常导致过度依赖感知和不稳定的控制。为了解决这个问题,我们引入了CRAFT,一个力感知的课程微调框架,它集成了一个变分信息瓶颈模块,以在早期训练中调节视觉和语言嵌入。这种课程策略鼓励模型最初优先考虑力信号,然后再逐步恢复对完整多模态信息的访问。为了实现力感知的学习,我们进一步设计了一个同源的主从遥操作系统,该系统收集跨各种接触式任务同步的视觉、语言和力数据。真实世界的实验表明,CRAFT始终提高任务成功率,推广到未见过的物体和新的任务变化,并有效地适应各种VLA架构,从而实现鲁棒和通用的接触式操作。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在处理接触式操作任务时,由于视觉和语言信息的高熵特性,模型容易过度依赖视觉感知,而忽略了低熵但至关重要的力反馈信号。这种信息不平衡导致模型在需要精确对齐、稳定接触和处理可变形物体等任务中表现不佳,控制不稳定,任务成功率低。
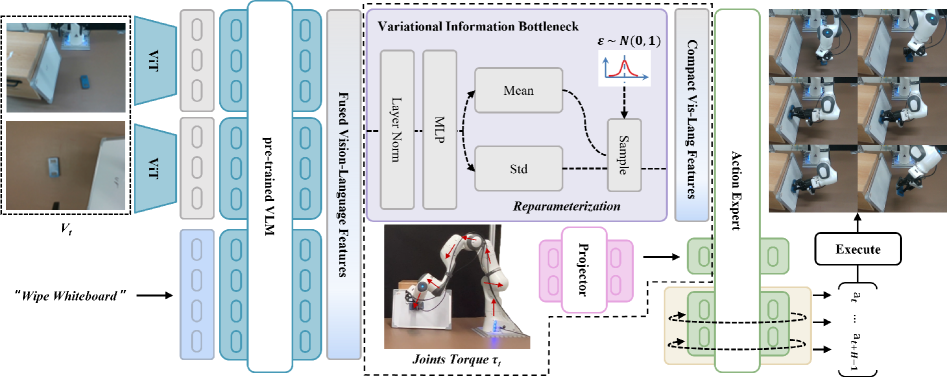
核心思路:CRAFT的核心思路是通过课程学习的方式,逐步引导模型关注并利用力反馈信息。在训练初期,通过变分信息瓶颈模块限制视觉和语言信息的传递,迫使模型更多地依赖力信号进行学习。随着训练的进行,逐步放开对视觉和语言信息的限制,使模型能够融合多模态信息,从而实现更鲁棒的控制。
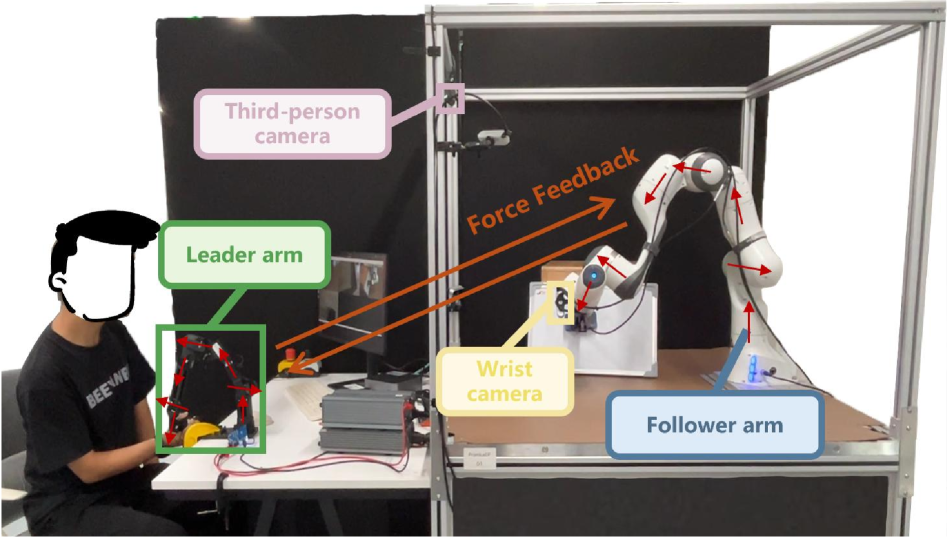
技术框架:CRAFT框架主要包含三个部分:数据采集系统、力感知课程微调模块和VLA模型。数据采集系统采用同源的主从遥操作系统,同步采集视觉、语言和力数据。力感知课程微调模块包含变分信息瓶颈模块和课程学习策略,用于调节视觉和语言嵌入,并逐步引导模型关注力信号。VLA模型可以是任意的视觉-语言-动作模型,CRAFT框架可以对其进行微调,使其适应接触式操作任务。
关键创新:CRAFT最重要的创新点在于提出了力感知的课程微调策略,通过变分信息瓶颈模块和课程学习策略,有效地解决了视觉语言信息与力反馈信号之间的不平衡问题。这种方法能够引导模型在训练初期优先关注力信号,从而提高模型在接触式操作任务中的性能。
关键设计:CRAFT的关键设计包括:1)变分信息瓶颈模块,用于限制视觉和语言信息的传递;2)课程学习策略,逐步放开对视觉和语言信息的限制;3)同源的主从遥操作系统,用于采集同步的视觉、语言和力数据。课程学习策略的具体实现方式是,在训练初期,设置一个较低的信息瓶颈约束,随着训练的进行,逐步提高该约束,从而逐步放开对视觉和语言信息的限制。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CRAFT框架能够显著提高接触式操作任务的成功率,并且具有良好的泛化能力。在真实世界的实验中,CRAFT在多个接触式操作任务上都取得了显著的性能提升,并且能够推广到未见过的物体和新的任务变化。此外,CRAFT还能够有效地适应各种VLA架构,表明其具有良好的通用性。
🎯 应用场景
CRAFT框架可应用于各种需要精确接触和力控制的机器人操作任务,例如装配、抓取、操作可变形物体、医疗手术等。该研究有助于提高机器人在复杂环境中的适应性和鲁棒性,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Vision-Language-Action (VLA) models have shown a strong capability in enabling robots to execute general instructions, yet they struggle with contact-rich manipulation tasks, where success requires precise alignment, stable contact maintenance, and effective handling of deformable objects. A fundamental challenge arises from the imbalance between high-entropy vision and language inputs and low-entropy but critical force signals, which often leads to over-reliance on perception and unstable control. To address this, we introduce CRAFT, a force-aware curriculum fine-tuning framework that integrates a variational information bottleneck module to regulate vision and language embeddings during early training. This curriculum strategy encourages the model to prioritize force signals initially, before progressively restoring access to the full multimodal information. To enable force-aware learning, we further design a homologous leader-follower teleoperation system that collects synchronized vision, language, and force data across diverse contact-rich tasks. Real-world experiments demonstrate that CRAFT consistently improves task success, generalizes to unseen objects and novel task variations, and adapts effectively across diverse VLA architectures, enabling robust and generalizable contact-rich manipulation.