Scaling Verification Can Be More Effective than Scaling Policy Learning for Vision-Language-Action Alignment
作者: Jacky Kwok, Xilun Zhang, Mengdi Xu, Yuejiang Liu, Azalia Mirhoseini, Chelsea Finn, Marco Pavone
分类: cs.RO, cs.AI, eess.SY
发布日期: 2026-02-12
💡 一句话要点
提出CoVer:通过验证而非策略学习提升视觉-语言-动作对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作对齐 对比学习 机器人控制 指令跟随 测试时验证
📋 核心要点
- 现有视觉-语言-动作(VLA)模型在理解指令和执行动作方面仍存在“意图-动作差距”,导致动作与指令不符。
- 论文提出对比验证器CoVer,通过扩展复述指令和生成动作的多样性,并使用验证器选择最优动作,从而弥合意图-动作差距。
- 实验表明,CoVer在SIMPLER和PolaRiS基准测试中均优于扩展策略预训练的方法,并在真实世界实验中取得了显著提升。
📝 摘要(中文)
本文研究了测试时验证方法,旨在缩小通用机器人理解自然语言指令并执行动作时的“意图-动作差距”。研究表明,联合扩展复述指令和生成动作的数量能显著增加测试时样本的多样性,比单独扩展每个维度更有效地恢复正确的动作。为此,本文提出了CoVer,一种用于视觉-语言-动作对齐的对比验证器,并证明其架构能随着计算资源和数据的增加而优雅地扩展。此外,本文还引入了“启动时计算”和分层验证推理流程。在部署时,该框架预先计算来自视觉-语言模型(VLM)的各种复述指令,重复生成每个指令的动作候选,然后使用验证器选择最佳的高级提示和低级动作块。与在相同数据上扩展策略预训练相比,本文的验证方法在SIMPLER基准测试中,在同分布数据上获得了22%的收益,在异分布数据上获得了13%的收益,并在真实世界实验中进一步提高了45%。在PolaRiS基准测试中,CoVer在任务进度上实现了14%的收益,在成功率上实现了9%的收益。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作模型中,生成的动作与给定的自然语言指令不一致的问题,即“意图-动作差距”。现有方法主要依赖于策略学习,但策略学习可能无法充分覆盖所有可能的指令和环境状态,导致泛化能力不足。
核心思路:论文的核心思路是利用测试时验证来提升VLA模型的性能。通过生成多个可能的动作序列,并使用一个验证器来判断哪个序列最符合给定的指令,从而提高动作的准确性。这种方法的核心在于增加动作的多样性,并利用验证器来筛选出最佳动作。
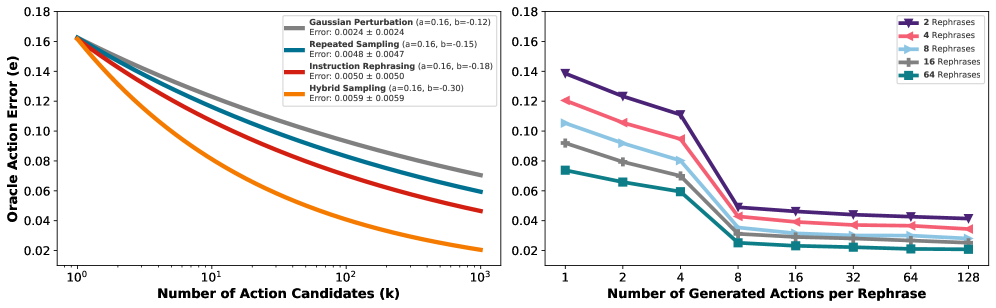
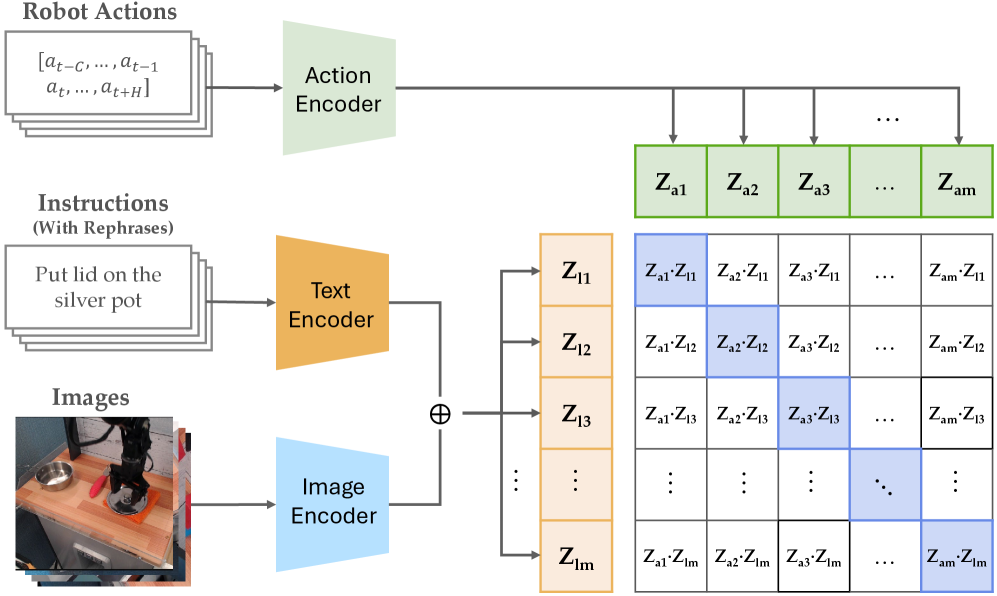
技术框架:整体框架包含以下几个主要阶段:1) 指令复述:使用视觉-语言模型(VLM)生成多个对原始指令的复述,增加指令的多样性。2) 动作生成:对于每个复述指令,生成多个候选动作序列。3) 对比验证:使用对比验证器CoVer,对每个候选动作序列进行评分,判断其与指令的对齐程度。4) 动作选择:选择得分最高的动作序列作为最终执行的动作。该框架引入了“启动时计算”的概念,即预先计算大量的复述指令,以便在部署时快速生成候选动作。
关键创新:论文的关键创新在于:1) 提出了对比验证器CoVer,用于评估动作序列与指令的对齐程度。2) 提出了“启动时计算”的概念,预先计算复述指令,提高推理效率。3) 证明了联合扩展复述指令和生成动作的数量比单独扩展每个维度更有效。4) 提出了分层验证推理流程,选择最佳的高级提示和低级动作块。
关键设计:CoVer是一个对比学习模型,其损失函数旨在区分正样本(与指令对齐的动作序列)和负样本(与指令不对齐的动作序列)。网络结构方面,CoVer可能包含视觉编码器、语言编码器和动作编码器,用于提取视觉、语言和动作特征。具体的网络结构和损失函数细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoVer在SIMPLER基准测试中,在同分布数据上获得了22%的收益,在异分布数据上获得了13%的收益,并在真实世界实验中进一步提高了45%。在PolaRiS基准测试中,CoVer在任务进度上实现了14%的收益,在成功率上实现了9%的收益。这些结果表明,CoVer在视觉-语言-动作对齐方面具有显著的优势。
🎯 应用场景
该研究成果可应用于各种需要机器人理解自然语言指令并执行任务的场景,例如家庭服务机器人、工业自动化、医疗辅助机器人等。通过提高机器人对指令的理解和执行能力,可以显著提升其在复杂环境中的适应性和自主性,从而实现更广泛的应用。
📄 摘要(原文)
The long-standing vision of general-purpose robots hinges on their ability to understand and act upon natural language instructions. Vision-Language-Action (VLA) models have made remarkable progress toward this goal, yet their generated actions can still misalign with the given instructions. In this paper, we investigate test-time verification as a means to shrink the "intention-action gap.'' We first characterize the test-time scaling law for embodied instruction following and demonstrate that jointly scaling the number of rephrased instructions and generated actions greatly increases test-time sample diversity, often recovering correct actions more efficiently than scaling each dimension independently. To capitalize on these scaling laws, we present CoVer, a contrastive verifier for vision-language-action alignment, and show that our architecture scales gracefully with additional computational resources and data. We then introduce "boot-time compute" and a hierarchical verification inference pipeline for VLAs. At deployment, our framework precomputes a diverse set of rephrased instructions from a Vision-Language-Model (VLM), repeatedly generates action candidates for each instruction, and then uses a verifier to select the optimal high-level prompt and low-level action chunks. Compared to scaling policy pre-training on the same data, our verification approach yields 22% gains in-distribution and 13% out-of-distribution on the SIMPLER benchmark, with a further 45% improvement in real-world experiments. On the PolaRiS benchmark, CoVer achieves 14% gains in task progress and 9% in success rate.