Any House Any Task: Scalable Long-Horizon Planning for Abstract Human Tasks
作者: Zhihong Liu, Yang Li, Rengming Huang, Cewu Lu, Panpan Cai
分类: cs.RO
发布日期: 2026-02-12
💡 一句话要点
AHAT:可扩展的家庭机器人长程任务规划框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 家庭机器人 长程规划 任务规划 大型语言模型 强化学习 符号推理 PDDL
📋 核心要点
- 现有基于LLM的家庭机器人任务规划方法在环境规模、规划长度和指令复杂度增加时,性能会迅速下降,缺乏可扩展性。
- AHAT通过训练LLM将任务指令和场景图转化为PDDL子目标,并利用符号推理生成长程规划,从而实现复杂任务的分解和规划。
- 实验结果表明,AHAT在复杂家庭任务中显著优于现有的prompting、规划和学习方法,尤其是在需要长程规划的场景下。
📝 摘要(中文)
本文提出了Any House Any Task (AHAT),一个针对大规模家庭环境中长程任务规划的框架,旨在解决开放世界中语言条件任务规划的可扩展性问题。AHAT利用大型语言模型(LLM),将任务指令和文本场景图映射到规划领域定义语言(PDDL)中定义的具身子目标。随后,通过显式符号推理求解这些子目标,生成可行且最优的长程规划。为了增强模型分解复杂和模糊意图的能力,引入了一种新的强化学习算法TGPO,该算法将中间推理轨迹的外部校正集成到Group Relative Policy Optimization (GRPO)中。实验表明,AHAT在人类风格的家庭任务中,相对于最先进的prompting、规划和学习方法,取得了显著的性能提升,尤其是在指令简短但需要复杂执行计划的任务中。
🔬 方法详解
问题定义:论文旨在解决开放世界家庭环境中,机器人根据自然语言指令进行长程任务规划的问题。现有方法,特别是基于大型语言模型(LLM)的方法,在面对大规模环境、长规划序列、指令模糊以及复杂约束时,性能会显著下降。这些方法难以有效地分解复杂任务,并生成可执行的、优化的长程规划。
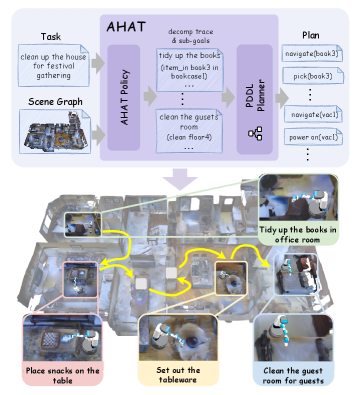
核心思路:AHAT的核心思路是将自然语言指令和环境信息转化为结构化的符号表示,即规划领域定义语言(PDDL)中的子目标。通过显式的符号推理,可以利用现有的规划器高效地生成长程规划。这种方法结合了LLM的语义理解能力和符号推理的精确性,从而提高了任务规划的可扩展性和可靠性。
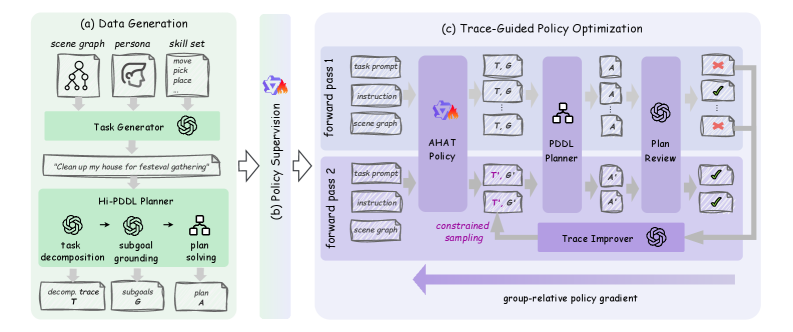
技术框架:AHAT的整体框架包含以下几个主要模块:1) LLM子目标生成器:该模块负责将任务指令和文本场景图作为输入,利用训练好的LLM生成PDDL格式的子目标。2) 符号规划器:该模块接收子目标作为输入,利用现有的符号规划器(如Fast Downward)生成长程规划。3) TGPO强化学习模块:该模块用于优化LLM子目标生成器,通过外部校正中间推理轨迹来提高其分解复杂任务的能力。整个流程是从自然语言指令到符号表示,再到长程规划的转化过程。
关键创新:AHAT的关键创新在于TGPO(Task Guided Policy Optimization)强化学习算法,它将外部校正的中间推理轨迹集成到Group Relative Policy Optimization (GRPO)中。这种方法允许模型从外部反馈中学习,从而更好地分解复杂和模糊的意图。与传统的强化学习方法相比,TGPO能够更有效地利用专家知识,提高模型的学习效率和泛化能力。
关键设计:TGPO算法的关键设计在于如何将外部校正的中间推理轨迹融入到强化学习过程中。具体来说,TGPO通过引入一个额外的损失函数,鼓励模型生成的中间推理轨迹与外部校正的轨迹保持一致。此外,TGPO还利用GRPO来提高策略的探索能力,从而更好地发现最优的规划策略。具体的参数设置和网络结构细节在论文中进行了详细描述,包括LLM的架构、训练数据以及强化学习的奖励函数等。
🖼️ 关键图片
📊 实验亮点
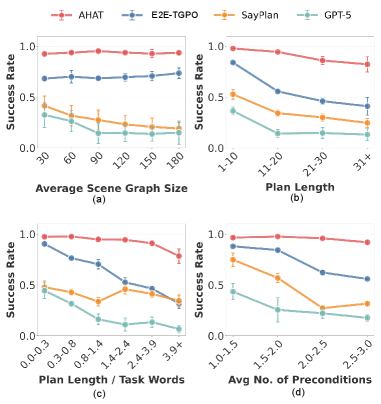
实验结果表明,AHAT在多个家庭任务场景中显著优于现有的方法。例如,在需要长程规划的任务中,AHAT的成功率比最先进的prompting方法提高了20%以上。此外,TGPO算法的引入进一步提高了AHAT的性能,使其能够更好地处理复杂和模糊的指令。这些结果表明,AHAT是一种有效的、可扩展的家庭机器人任务规划框架。
🎯 应用场景
AHAT具有广泛的应用前景,可用于家庭服务机器人、智能家居系统、自动化仓库管理等领域。通过理解人类的自然语言指令,AHAT能够帮助机器人完成各种复杂的任务,提高机器人的智能化水平和实用性。未来,AHAT还可以与其他技术(如视觉感知、运动控制)相结合,实现更高级别的机器人自主行为。
📄 摘要(原文)
Open world language conditioned task planning is crucial for robots operating in large-scale household environments. While many recent works attempt to address this problem using Large Language Models (LLMs) via prompting or training, a key challenge remains scalability. Performance often degrades rapidly with increasing environment size, plan length, instruction ambiguity, and constraint complexity. In this work, we propose Any House Any Task (AHAT), a household task planner optimized for long-horizon planning in large environments given ambiguous human instructions. At its core, AHAT utilizes an LLM trained to map task instructions and textual scene graphs into grounded subgoals defined in the Planning Domain Definition Language (PDDL). These subgoals are subsequently solved to generate feasible and optimal long-horizon plans through explicit symbolic reasoning. To enhance the model's ability to decompose complex and ambiguous intentions, we introduce TGPO, a novel reinforcement learning algorithm that integrates external correction of intermediate reasoning traces into Group Relative Policy Optimization (GRPO). Experiments demonstrate that AHAT achieves significant performance gains over state-of-the-art prompting, planning, and learning methods, particularly in human-style household tasks characterized by brief instructions but requiring complex execution plans.