LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion
作者: Jiangran Lyu, Kai Liu, Xuheng Zhang, Haoran Liao, Yusen Feng, Wenxuan Zhu, Tingrui Shen, Jiayi Chen, Jiazhao Zhang, Yifei Dong, Wenbo Cui, Senmao Qi, Shuo Wang, Yixin Zheng, Mi Yan, Xuesong Shi, Haoran Li, Dongbin Zhao, Ming-Yu Liu, Zhizheng Zhang, Li Yi, Yizhou Wang, He Wang
分类: cs.RO
发布日期: 2026-02-12
备注: Project Page:https://pku-epic.github.io/LDA
💡 一句话要点
LDA-1B:通过通用具身数据摄取扩展潜在动力学行为模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人基础模型 具身智能 动力学学习 通用数据摄取 DINO潜在空间
📋 核心要点
- 现有机器人基础模型主要依赖大规模行为克隆,忽略了异构具身数据中蕴含的可迁移动力学知识。
- LDA-1B通过联合学习动力学、策略和视觉预测,并为不同质量的数据分配不同角色,从而实现通用具身数据摄取。
- 实验表明,LDA-1B在多种任务上显著优于现有方法,并能有效利用低质量数据进行数据高效的微调。
📝 摘要(中文)
本文提出LDA-1B,一个机器人基础模型,通过通用具身数据摄取进行扩展,联合学习动力学、策略和视觉预测,为不同质量的数据分配不同的角色。为了支持这种大规模训练,作者构建并标准化了EI-30k,一个包含超过3万小时人类和机器人轨迹的具身交互数据集,并统一了数据格式。通过在结构化的DINO潜在空间中进行预测,实现了对异构数据的可扩展动力学学习,避免了冗余的像素空间外观建模。此外,LDA-1B采用多模态扩散Transformer来处理异步视觉和动作流,从而实现10亿参数规模的稳定训练。在模拟和真实世界的实验表明,LDA-1B在接触丰富的、灵巧的和长时程任务上,优于现有方法(例如,$π_{0.5}$)高达21%、48%和23%。值得注意的是,LDA-1B实现了数据高效的微调,通过利用通常有害且被丢弃的30%低质量轨迹,获得了10%的性能提升。
🔬 方法详解
问题定义:现有机器人基础模型主要采用行为克隆,直接模仿专家动作,但忽略了异构具身数据中蕴含的、可迁移的动力学知识。统一世界模型(UWM)理论上有潜力利用这些多样化数据,但现有实现由于数据使用粗糙和数据集分散,难以扩展到基础模型的规模。
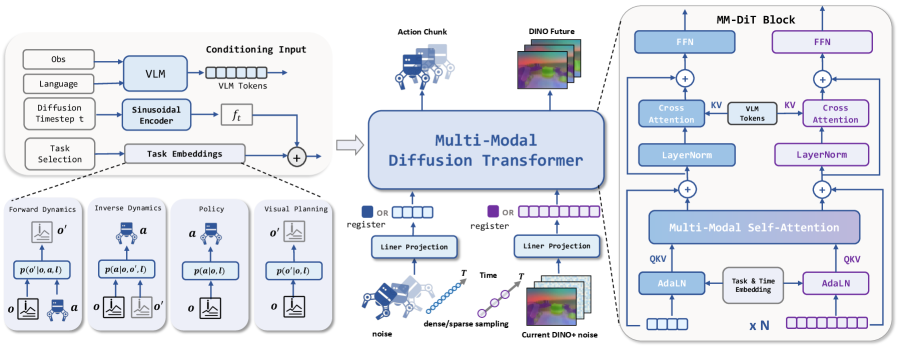
核心思路:LDA-1B的核心思路是通过联合学习动力学、策略和视觉预测,并根据数据质量分配不同的角色,从而实现对大规模异构具身数据的有效利用。通过在DINO潜在空间中进行预测,避免了对像素空间外观的冗余建模,从而提高了学习效率和泛化能力。
技术框架:LDA-1B的整体框架包含以下几个主要模块:1) EI-30k数据集:一个包含超过3万小时人类和机器人轨迹的统一格式具身交互数据集。2) DINO潜在空间:用于学习数据的结构化潜在表示,避免像素级别的冗余建模。3) 多模态扩散Transformer:用于处理异步的视觉和动作流,实现大规模模型的稳定训练。模型首先将视觉输入编码到DINO潜在空间,然后使用Transformer预测未来的潜在状态和动作。
关键创新:LDA-1B的关键创新在于其通用的具身数据摄取方法,能够有效地利用大规模异构数据进行动力学学习。通过在DINO潜在空间中进行预测,避免了对像素空间外观的冗余建模,从而提高了学习效率和泛化能力。此外,多模态扩散Transformer的设计也使得模型能够处理异步的视觉和动作流,实现大规模模型的稳定训练。
关键设计:LDA-1B的关键设计包括:1) EI-30k数据集的构建和标准化,为大规模具身数据学习提供了基础。2) 使用DINO模型提取视觉特征,并在其潜在空间中进行预测,降低了计算复杂度。3) 采用多模态扩散Transformer,能够有效处理异步的视觉和动作流,并支持大规模模型的训练。损失函数方面,可能包括动力学预测损失、策略学习损失和视觉预测损失等,具体细节未知。
🖼️ 关键图片


📊 实验亮点
LDA-1B在模拟和真实世界的实验中表现出色,在接触丰富的、灵巧的和长时程任务上,分别优于现有方法(例如,$π_{0.5}$)高达21%、48%和23%。更重要的是,LDA-1B能够有效利用低质量数据进行数据高效的微调,通过利用通常被丢弃的30%低质量轨迹,获得了10%的性能提升,证明了其强大的数据利用能力。
🎯 应用场景
LDA-1B具有广泛的应用前景,包括机器人操作、自动驾驶、虚拟现实等领域。它可以用于训练更智能、更灵活的机器人,使其能够更好地适应复杂多变的环境。此外,LDA-1B还可以用于生成逼真的虚拟环境,为用户提供更沉浸式的体验。未来,该研究有望推动机器人和人工智能技术的进一步发展。
📄 摘要(原文)
Recent robot foundation models largely rely on large-scale behavior cloning, which imitates expert actions but discards transferable dynamics knowledge embedded in heterogeneous embodied data. While the Unified World Model (UWM) formulation has the potential to leverage such diverse data, existing instantiations struggle to scale to foundation-level due to coarse data usage and fragmented datasets. We introduce LDA-1B, a robot foundation model that scales through universal embodied data ingestion by jointly learning dynamics, policy, and visual forecasting, assigning distinct roles to data of varying quality. To support this regime at scale, we assemble and standardize EI-30k, an embodied interaction dataset comprising over 30k hours of human and robot trajectories in a unified format. Scalable dynamics learning over such heterogeneous data is enabled by prediction in a structured DINO latent space, which avoids redundant pixel-space appearance modeling. Complementing this representation, LDA-1B employs a multi-modal diffusion transformer to handle asynchronous vision and action streams, enabling stable training at the 1B-parameter scale. Experiments in simulation and the real world show LDA-1B outperforms prior methods (e.g., $π_{0.5}$) by up to 21\%, 48\%, and 23\% on contact-rich, dexterous, and long-horizon tasks, respectively. Notably, LDA-1B enables data-efficient fine-tuning, gaining 10\% by leveraging 30\% low-quality trajectories typically harmful and discarded.