Affordance-Graphed Task Worlds: Self-Evolving Task Generation for Scalable Embodied Learning
作者: Xiang Liu, Sen Cui, Guocai Yao, Zhong Cao, Jingheng Ma, Min Zhang, Changshui Zhang
分类: cs.RO
发布日期: 2026-02-12
💡 一句话要点
提出基于可供性图的任务世界,用于可扩展具身学习的自进化任务生成。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 具身学习 机器人学习 任务生成 可供性图 自进化 视觉-语言模型 仿真环境
📋 核心要点
- 现有机器人策略训练方法在真实世界成本高,仿真环境难以生成连贯长时程任务,且难以应对动态物理不确定性。
- AGT-World将任务空间建模为可供性图,实现复杂目标到原子原语的精确分层分解,并结合视觉-语言模型和几何验证进行策略自进化。
- 实验表明,AGT-World在成功率和泛化能力上显著优于现有方法,实现了提议、执行和纠正的自改进循环。
📝 摘要(中文)
在真实世界中直接训练机器人策略成本高昂且难以扩展。生成式仿真虽然能够大规模合成数据,但现有方法通常难以生成逻辑连贯的长时程任务,并且由于开环执行而难以应对动态物理不确定性。为了解决这些挑战,我们提出了可供性图任务世界(AGT-World),这是一个统一的框架,能够基于真实世界的观察自主构建交互式仿真环境和相应的机器人任务策略。与依赖随机提议或静态复制的方法不同,AGT-World将任务空间形式化为结构化图,从而能够将复杂目标精确地、分层地分解为理论上合理的原子原语。此外,我们引入了一种具有混合反馈的自进化机制,通过结合视觉-语言模型推理和几何验证来自主地改进策略。大量实验表明,我们的方法在成功率和泛化方面显著优于现有方法,实现了用于可扩展机器人学习的提议、执行和纠正的自改进循环。
🔬 方法详解
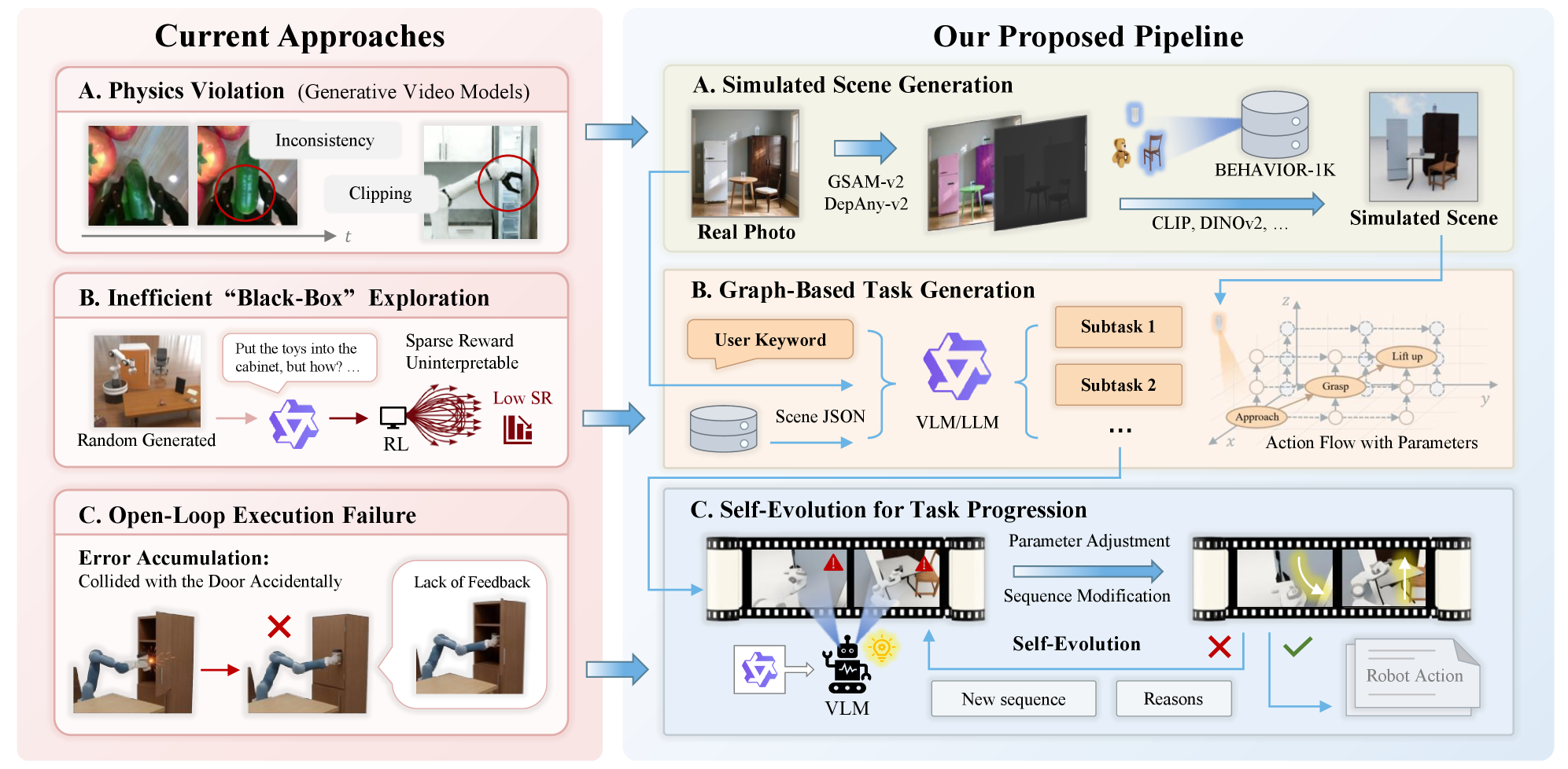
问题定义:论文旨在解决机器人学习中,在真实世界训练成本高昂,以及现有仿真方法难以生成逻辑连贯、能应对动态物理不确定性的长时程任务的问题。现有方法主要依赖随机提议或静态复制,缺乏对任务空间的结构化理解,导致任务生成效率低且质量不高。
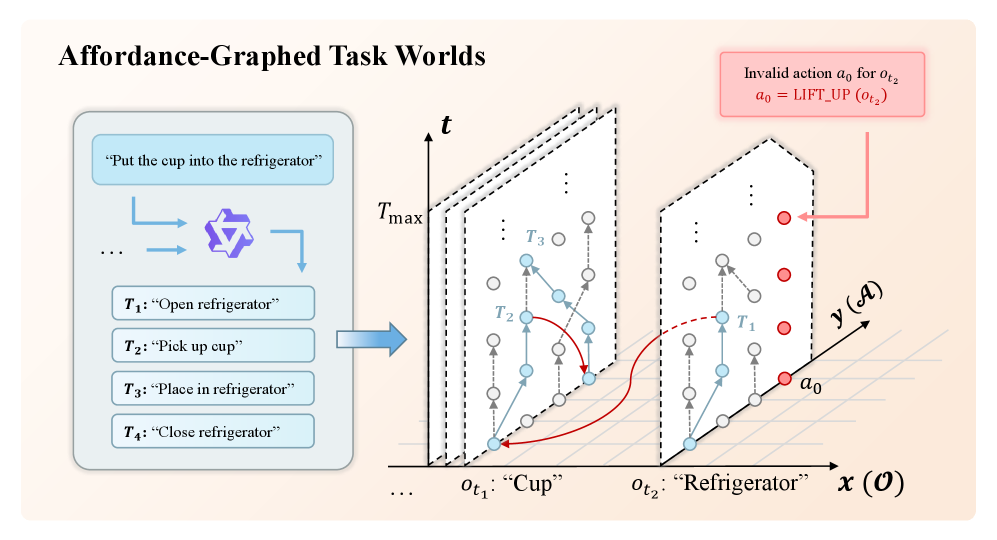
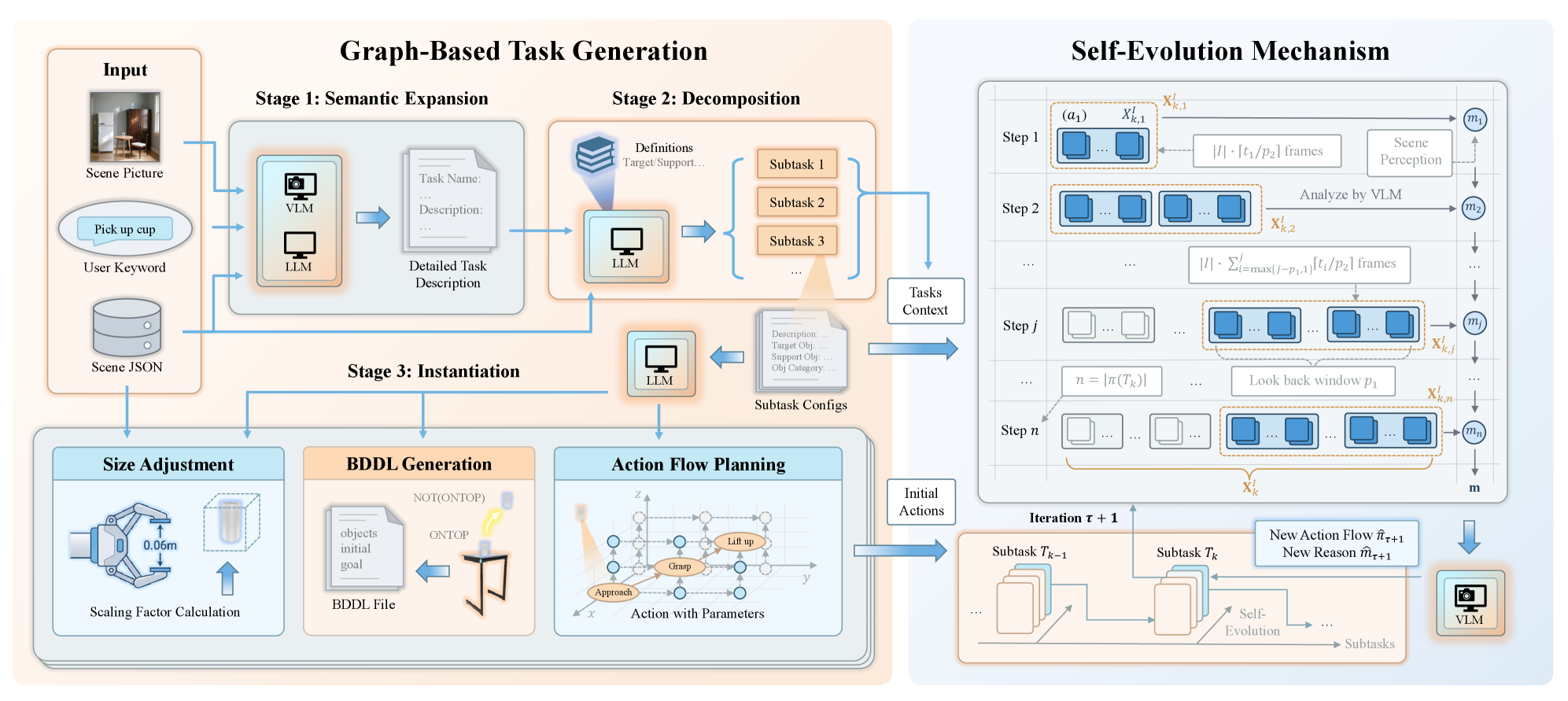
核心思路:论文的核心思路是将任务空间形式化为可供性图(Affordance Graph),利用图中节点表示原子操作,边表示操作之间的依赖关系,从而实现复杂任务的精确分解和组合。此外,通过引入自进化机制,利用视觉-语言模型和几何验证对策略进行持续改进,形成一个闭环的自学习系统。
技术框架:AGT-World框架主要包含以下几个模块:1) 可供性图构建模块:基于真实世界观察,构建包含原子操作及其依赖关系的可供性图。2) 任务生成模块:利用可供性图,将复杂目标分解为原子操作序列,生成相应的机器人任务。3) 策略执行模块:在仿真环境中执行生成的任务,并记录执行结果。4) 自进化模块:利用视觉-语言模型和几何验证对执行结果进行分析,并对策略进行改进。
关键创新:论文最重要的技术创新点在于将可供性图引入到任务生成中,实现了对任务空间的结构化建模,从而能够精确地分解和组合复杂任务。与现有方法相比,AGT-World不再依赖随机提议或静态复制,而是基于对环境和机器人能力的理解,生成更合理、更有效的任务。此外,自进化机制的引入,使得系统能够不断学习和改进,提高任务执行的成功率和泛化能力。
关键设计:在可供性图构建方面,论文可能采用了基于视觉和语言信息的联合推理方法,自动识别环境中的可供性。在自进化模块中,视觉-语言模型可能用于判断任务执行是否符合预期,几何验证则用于检查机器人动作是否满足物理约束。具体的损失函数和网络结构等技术细节未知,需要查阅论文原文。
🖼️ 关键图片
📊 实验亮点
论文通过大量实验验证了AGT-World的有效性。实验结果表明,AGT-World在任务成功率和泛化能力方面显著优于现有方法。具体的性能数据和对比基线未知,需要查阅论文原文。但摘要中明确指出,该方法实现了提议、执行和纠正的自改进循环,表明其具有良好的学习能力。
🎯 应用场景
该研究成果可应用于各种需要机器人自主完成复杂任务的场景,例如智能制造、家庭服务、仓储物流等。通过AGT-World,机器人可以自主学习和适应新的任务环境,提高工作效率和智能化水平。未来,该技术有望推动机器人从简单的重复性劳动向更复杂的创造性工作转型。
📄 摘要(原文)
Training robotic policies directly in the real world is expensive and unscalable. Although generative simulation enables large-scale data synthesis, current approaches often fail to generate logically coherent long-horizon tasks and struggle with dynamic physical uncertainties due to open-loop execution. To address these challenges, we propose Affordance-Graphed Task Worlds (AGT-World), a unified framework that autonomously constructs interactive simulated environments and corresponding robot task policies based on real-world observations. Unlike methods relying on random proposals or static replication, AGT-World formalizes the task space as a structured graph, enabling the precise, hierarchical decomposition of complex goals into theoretically grounded atomic primitives. Furthermore, we introduce a Self-Evolution mechanism with hybrid feedback to autonomously refine policies, combining Vision-Language Model reasoning and geometric verification. Extensive experiments demonstrate that our method significantly outperforms in success rates and generalization, achieving a self-improving cycle of proposal, execution, and correction for scalable robot learning.