VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model
作者: Yanjiang Guo, Tony Lee, Lucy Xiaoyang Shi, Jianyu Chen, Percy Liang, Chelsea Finn
分类: cs.RO
发布日期: 2026-02-12
备注: 13 pages
💡 一句话要点
VLAW:迭代共提升视觉-语言-动作策略与世界模型,提升机器人操作性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作 世界模型 迭代学习 机器人操作 强化学习
📋 核心要点
- 现有世界模型在物理保真度上存在不足,尤其是在模拟复杂物理交互和失败案例时,限制了策略改进。
- 提出一种迭代改进算法,利用真实世界数据提升世界模型,再用改进后的世界模型生成合成数据,反哺VLA模型。
- 实验表明,该方法在真实机器人上显著提升了VLA模型的性能,成功率提升高达39.2%。
📝 摘要(中文)
本文旨在通过迭代在线交互,提高视觉-语言-动作(VLA)模型的性能和可靠性。由于在现实世界中收集策略rollout的成本很高,因此我们研究是否可以使用学习到的模拟器(特别是动作条件视频生成模型)来生成额外的rollout数据。然而,现有的世界模型缺乏策略改进所需的物理保真度:它们主要在缺乏各种物理交互(特别是失败案例)的演示数据集上进行训练,并且难以准确地模拟富含接触的物体操作中微小但关键的物理细节。我们提出了一种简单的迭代改进算法,该算法使用真实世界的rollout数据来提高世界模型的保真度,然后可以将其用于生成补充合成数据,以改进VLA模型。在真实机器人上的实验中,我们使用这种方法来提高最先进的VLA模型在多个下游任务上的性能。与基础策略相比,我们实现了39.2%的绝对成功率提升,并且通过使用生成的合成rollout进行训练,实现了11.6%的提升。
🔬 方法详解
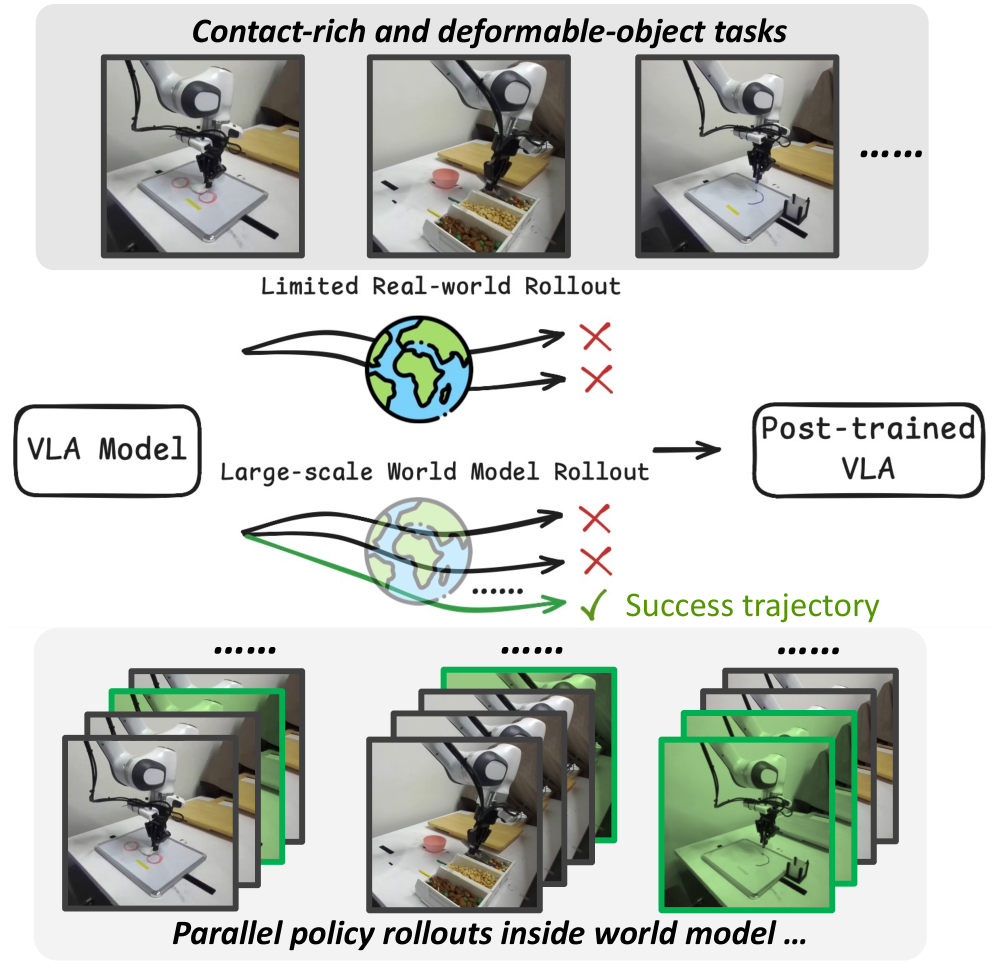
问题定义:现有视觉-语言-动作(VLA)模型依赖于大量真实世界数据进行训练,但真实世界数据采集成本高昂。利用世界模型生成合成数据是一种潜在的解决方案,然而,现有世界模型在模拟复杂物理交互(尤其是失败案例)以及精确建模接触力等方面存在不足,导致合成数据质量不高,难以有效提升VLA模型的性能。
核心思路:本文的核心思路是通过迭代的方式,交替提升VLA策略和世界模型的性能。首先,利用少量真实世界数据训练初始的VLA策略和世界模型。然后,利用VLA策略在真实世界中进行rollout,并将rollout数据用于改进世界模型。改进后的世界模型可以生成更高质量的合成数据,用于进一步提升VLA策略。
技术框架:VLAW的整体框架包含以下几个主要模块:1) 真实世界数据采集模块:用于采集少量真实世界rollout数据。2) 世界模型训练模块:利用真实世界数据训练动作条件视频生成模型作为世界模型。3) VLA策略训练模块:利用真实世界数据和合成数据训练VLA策略。4) 迭代优化模块:交替进行世界模型和VLA策略的训练,并利用VLA策略在真实世界中进行rollout,收集新的数据用于改进世界模型。
关键创新:VLAW的关键创新在于提出了一种迭代共提升的框架,能够有效地利用少量真实世界数据和大量合成数据,提升VLA策略的性能。与传统的先训练世界模型再训练策略的方法不同,VLAW通过迭代的方式,使得世界模型和VLA策略能够相互促进,共同提升。
关键设计:在世界模型方面,采用了动作条件视频生成模型,能够根据给定的动作序列生成相应的视频序列。在VLA策略方面,采用了现有的最先进的VLA模型。在迭代优化方面,采用了简单的交替训练策略,即先训练世界模型,再训练VLA策略,然后重复这个过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VLAW方法在真实机器人操作任务上取得了显著的性能提升。与基线VLA策略相比,VLAW实现了39.2%的绝对成功率提升。此外,仅使用VLAW生成的合成数据进行训练,也能获得11.6%的性能提升,验证了该方法在数据效率方面的优势。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶等领域。通过迭代优化视觉-语言-动作策略和世界模型,可以显著提高机器人在复杂环境中的适应性和鲁棒性,降低对大量真实世界数据的依赖,加速机器人智能化进程,并降低开发和部署成本。
📄 摘要(原文)
The goal of this paper is to improve the performance and reliability of vision-language-action (VLA) models through iterative online interaction. Since collecting policy rollouts in the real world is expensive, we investigate whether a learned simulator-specifically, an action-conditioned video generation model-can be used to generate additional rollout data. Unfortunately, existing world models lack the physical fidelity necessary for policy improvement: they are predominantly trained on demonstration datasets that lack coverage of many different physical interactions (particularly failure cases) and struggle to accurately model small yet critical physical details in contact-rich object manipulation. We propose a simple iterative improvement algorithm that uses real-world roll-out data to improve the fidelity of the world model, which can then, in turn, be used to generate supplemental synthetic data for improving the VLA model. In our experiments on a real robot, we use this approach to improve the performance of a state-of-the-art VLA model on multiple downstream tasks. We achieve a 39.2% absolute success rate improvement over the base policy and 11.6% improvement from training with the generated synthetic rollouts. Videos can be found at this anonymous website: https://sites.google.com/view/vla-w