HoloBrain-0 Technical Report
作者: Xuewu Lin, Tianwei Lin, Yun Du, Hongyu Xie, Yiwei Jin, Jiawei Li, Shijie Wu, Qingze Wang, Mengdi Li, Mengao Zhao, Ziang Li, Chaodong Huang, Hongzhe Bi, Lichao Huang, Zhizhong Su
分类: cs.RO
发布日期: 2026-02-12
备注: 32 pages
💡 一句话要点
HoloBrain-0:提出融合机器人先验知识的VLA框架,实现高效真实世界机器人部署
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 具身智能 多模态学习 机器人先验知识 3D空间推理 模型部署
📋 核心要点
- 现有VLA模型在真实机器人部署中面临挑战,缺乏对机器人自身结构和环境的有效理解。
- HoloBrain-0通过融合多视角相机参数和URDF等机器人先验知识,增强3D空间推理能力。
- 实验表明,该框架在模拟和真实世界任务中均表现出色,且0.2B参数版本可媲美更大模型。
📝 摘要(中文)
本文介绍了HoloBrain-0,一个全面的视觉-语言-动作(VLA)框架,旨在弥合基础模型研究与可靠的真实世界机器人部署之间的差距。该系统的核心是一种新颖的VLA架构,它显式地结合了机器人本体先验知识,包括多视角相机参数和运动学描述(URDF),以增强3D空间推理并支持多样化的机器人形态。通过可扩展的“预训练然后后训练”范式验证了该设计的有效性,在RoboTwin 2.0、LIBERO和GenieSim等模拟基准测试中取得了最先进的结果,并在具有挑战性的长时程真实世界操作任务中取得了优异的成绩。值得注意的是,我们高效的0.2B参数变体可以与更大的基线模型相媲美,从而实现低延迟的设备端部署。为了进一步加速研究和实际应用,我们完全开源了整个HoloBrain生态系统,其中包括:(1)强大的预训练VLA基础模型;(2)针对多个模拟套件和真实世界任务的后训练检查点;(3)RoboOrchard,一个用于数据管理、模型训练和部署的全栈VLA基础设施。结合标准化的数据收集协议,此版本为社区提供了一条完整、可复现的通往高性能机器人操作的道路。
🔬 方法详解
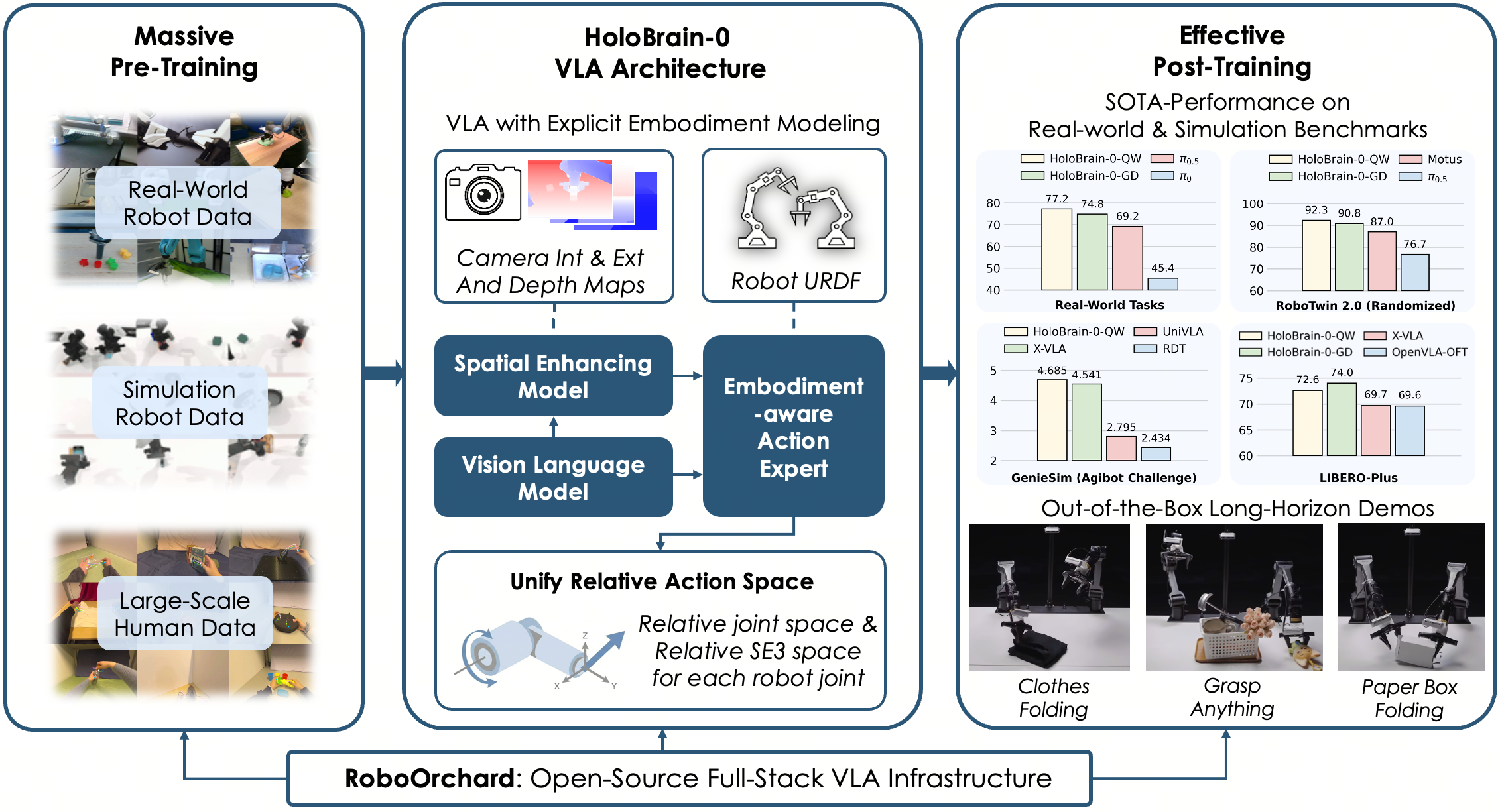
问题定义:现有视觉-语言-动作(VLA)模型在从模拟环境迁移到真实机器人操作时,面临着泛化能力不足的问题。这些模型通常忽略了机器人自身的物理结构和运动学约束,导致在复杂的三维空间推理和操作任务中表现不佳。此外,现有模型通常参数量巨大,难以在资源受限的机器人平台上进行实时部署。
核心思路:HoloBrain-0的核心思路是将机器人本体的先验知识(如多视角相机参数和URDF)显式地融入到VLA模型的架构中。通过这种方式,模型能够更好地理解机器人的自身状态和周围环境,从而提高其在真实世界中的操作能力。同时,该框架采用高效的模型设计,降低了参数量,使其能够在设备端进行低延迟部署。
技术框架:HoloBrain-0采用一种“预训练然后后训练”的范式。首先,在大量的模拟数据上对VLA模型进行预训练,使其具备初步的视觉、语言和动作理解能力。然后,针对特定的机器人操作任务,利用真实世界的数据对模型进行后训练,以提高其在真实环境中的泛化能力。该框架包含以下主要模块:视觉编码器、语言编码器、动作解码器和机器人先验知识融合模块。
关键创新:HoloBrain-0最重要的技术创新点在于其显式地将机器人本体先验知识融入到VLA模型中。与传统的VLA模型相比,HoloBrain-0能够更好地理解机器人的自身状态和周围环境,从而提高其在真实世界中的操作能力。此外,该框架采用高效的模型设计,降低了参数量,使其能够在设备端进行低延迟部署。
关键设计:HoloBrain-0的关键设计包括:(1) 使用多视角相机数据来增强3D空间感知能力;(2) 利用URDF文件来描述机器人的运动学结构;(3) 设计了一种新的机器人先验知识融合模块,将相机参数和URDF信息有效地融入到VLA模型中;(4) 采用了一种轻量级的模型架构,以降低参数量和计算复杂度。
🖼️ 关键图片


📊 实验亮点
HoloBrain-0在RoboTwin 2.0、LIBERO和GenieSim等模拟基准测试中取得了最先进的结果。更重要的是,在具有挑战性的长时程真实世界操作任务中也表现出色。值得关注的是,其0.2B参数的轻量级版本,性能可以与参数量更大的基线模型相媲美,同时实现了低延迟的设备端部署。
🎯 应用场景
HoloBrain-0具有广泛的应用前景,可用于各种机器人操作任务,如工业自动化、家庭服务、医疗辅助等。该框架能够提高机器人在复杂环境中的操作能力和自主性,降低人工干预的需求,从而提高生产效率和服务质量。未来,HoloBrain-0有望成为机器人领域的重要基础设施,推动机器人技术的进一步发展。
📄 摘要(原文)
In this work, we introduce HoloBrain-0, a comprehensive Vision-Language-Action (VLA) framework that bridges the gap between foundation model research and reliable real-world robot deployment. The core of our system is a novel VLA architecture that explicitly incorporates robot embodiment priors, including multi-view camera parameters and kinematic descriptions (URDF), to enhance 3D spatial reasoning and support diverse embodiments. We validate this design through a scalable ``pre-train then post-train" paradigm, achieving state-of-the-art results on simulation benchmarks such as RoboTwin 2.0, LIBERO, and GenieSim, as well as strong results on challenging long-horizon real-world manipulation tasks. Notably, our efficient 0.2B-parameter variant rivals significantly larger baselines, enabling low-latency on-device deployment. To further accelerate research and practical adoption, we fully open-source the entire HoloBrain ecosystem, which includes: (1) powerful pre-trained VLA foundations; (2) post-trained checkpoints for multiple simulation suites and real-world tasks; and (3) RoboOrchard, a full-stack VLA infrastructure for data curation, model training and deployment. Together with standardized data collection protocols, this release provides the community with a complete, reproducible path toward high-performance robotic manipulation.