Accelerating Robotic Reinforcement Learning with Agent Guidance
作者: Haojun Chen, Zili Zou, Chengdong Ma, Yaoxiang Pu, Haotong Zhang, Yuanpei Chen, Yaodong Yang
分类: cs.RO, cs.AI
发布日期: 2026-02-12
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出AGPS框架,用多模态Agent指导机器人强化学习,提升样本效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人强化学习 Agent指导 多模态学习 样本效率 自动化监督
📋 核心要点
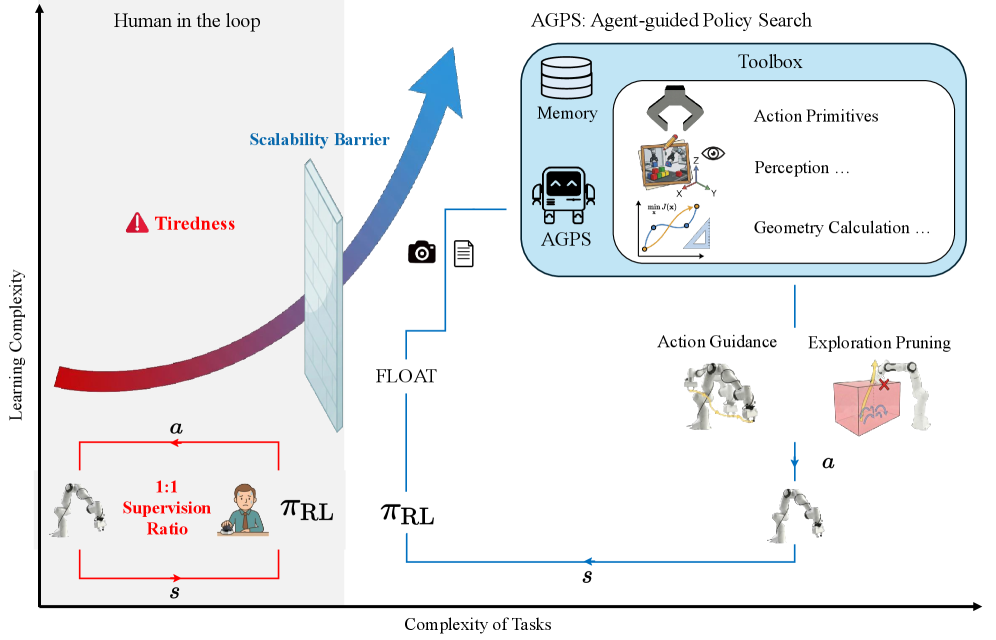
- 现有机器人强化学习方法样本效率低,而人机协作(HIL)方法虽能加速训练,但依赖人工监督,存在可扩展性问题。
- AGPS框架用多模态Agent取代人工监督,将Agent视为语义世界模型,通过可执行工具提供精确指导,引导机器人探索。
- 实验表明,AGPS在精密插入和可变形物体操作等任务中,样本效率优于HIL方法,实现了自动化和可扩展的机器人学习。
📝 摘要(中文)
强化学习(RL)为自主机器人掌握通用操作技能提供了一种强大的范例,但其在现实世界的应用受到严重样本效率问题的阻碍。最近的人在环(HIL)方法通过使用人工校正来加速训练,但这种方法面临可扩展性瓶颈。对人工监督的依赖导致1:1的监督比例,限制了机器人集群的扩展,长时间的会话会导致操作员疲劳,并且由于人工熟练程度的不一致而引入高方差。我们提出了Agent引导策略搜索(AGPS),该框架通过用多模态Agent替换人工监督者来自动化训练流程。我们的关键见解是,Agent可以被视为一个语义世界模型,注入内在价值先验来构建物理探索。通过使用可执行工具,Agent通过校正航点和空间约束为探索剪枝提供精确指导。我们在两个任务上验证了我们的方法,范围从精密插入到可变形物体操作。结果表明,AGPS在样本效率方面优于HIL方法。这自动化了监督流程,开启了无需人工且可扩展的机器人学习之路。
🔬 方法详解
问题定义:论文旨在解决机器人强化学习中样本效率低下的问题,尤其是在复杂操作任务中。现有的人在环(HIL)方法虽然可以加速学习,但严重依赖人工监督,这限制了其可扩展性,并且人工干预引入了不一致性和操作员疲劳等问题。
核心思路:论文的核心思路是用一个多模态Agent来替代人工监督者,从而实现自动化和可扩展的机器人强化学习。这个Agent被视为一个语义世界模型,能够理解任务目标和环境约束,并为机器人提供指导,从而更有效地探索状态空间。
技术框架:AGPS框架包含以下主要模块:1) 强化学习Agent:负责学习控制策略,与环境交互并收集经验数据。2) 多模态指导Agent:作为语义世界模型,利用视觉、语言等多种模态的信息,理解任务目标和环境约束,并生成指导信号。3) 指导信号生成模块:利用可执行工具,生成校正航点和空间约束等指导信号,引导强化学习Agent进行探索。4) 策略更新模块:根据强化学习Agent的经验数据和指导信号,更新控制策略。
关键创新:AGPS的关键创新在于使用多模态Agent来自动化监督流程,取代了传统的人工监督。这种方法不仅提高了样本效率,还解决了HIL方法的可扩展性问题。Agent提供的指导信号是基于语义理解的,能够更有效地引导机器人进行探索。
关键设计:论文中Agent的设计利用了多模态信息,例如视觉和语言,来理解任务目标和环境约束。指导信号的生成采用了可执行工具,例如运动规划器,来生成校正航点和空间约束。损失函数的设计考虑了指导信号的有效性,鼓励强化学习Agent遵循Agent的指导。
🖼️ 关键图片


📊 实验亮点
实验结果表明,AGPS在精密插入和可变形物体操作等任务中,显著提高了样本效率,优于传统的人在环(HIL)方法。具体而言,AGPS能够更快地学习到有效的控制策略,并且在相同的训练时间内,能够达到更高的性能水平。这表明AGPS能够有效地利用Agent提供的指导信号,引导机器人进行高效的探索。
🎯 应用场景
AGPS框架具有广泛的应用前景,可用于各种需要高精度和灵活性的机器人操作任务,例如工业自动化、医疗手术、家庭服务等。通过自动化监督流程,AGPS可以降低机器人学习的成本,提高机器人的自主性和适应性,从而推动机器人技术在各个领域的应用。
📄 摘要(原文)
Reinforcement Learning (RL) offers a powerful paradigm for autonomous robots to master generalist manipulation skills through trial-and-error. However, its real-world application is stifled by severe sample inefficiency. Recent Human-in-the-Loop (HIL) methods accelerate training by using human corrections, yet this approach faces a scalability barrier. Reliance on human supervisors imposes a 1:1 supervision ratio that limits fleet expansion, suffers from operator fatigue over extended sessions, and introduces high variance due to inconsistent human proficiency. We present Agent-guided Policy Search (AGPS), a framework that automates the training pipeline by replacing human supervisors with a multimodal agent. Our key insight is that the agent can be viewed as a semantic world model, injecting intrinsic value priors to structure physical exploration. By using executable tools, the agent provides precise guidance via corrective waypoints and spatial constraints for exploration pruning. We validate our approach on two tasks, ranging from precision insertion to deformable object manipulation. Results demonstrate that AGPS outperforms HIL methods in sample efficiency. This automates the supervision pipeline, unlocking the path to labor-free and scalable robot learning. Project website: https://agps-rl.github.io/agps.