Robot-DIFT: Distilling Diffusion Features for Geometrically Consistent Visuomotor Control
作者: Yu Deng, Yufeng Jin, Xiaogang Jia, Jiahong Xue, Gerhard Neumann, Georgia Chalvatzaki
分类: cs.RO
发布日期: 2026-02-12
💡 一句话要点
Robot-DIFT:通过蒸馏扩散特征实现几何一致的视觉运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉运动控制 扩散模型 知识蒸馏 几何一致性 特征提取 空间推理
📋 核心要点
- 现有视觉骨干网络在几何敏感性方面存在不足,难以满足机器人操作对精细控制的需求。
- Robot-DIFT通过流形蒸馏,将扩散模型的几何先验知识迁移到确定性的特征提取网络中。
- 实验表明,Robot-DIFT在几何一致性和控制性能上优于现有判别模型,验证了其有效性。
📝 摘要(中文)
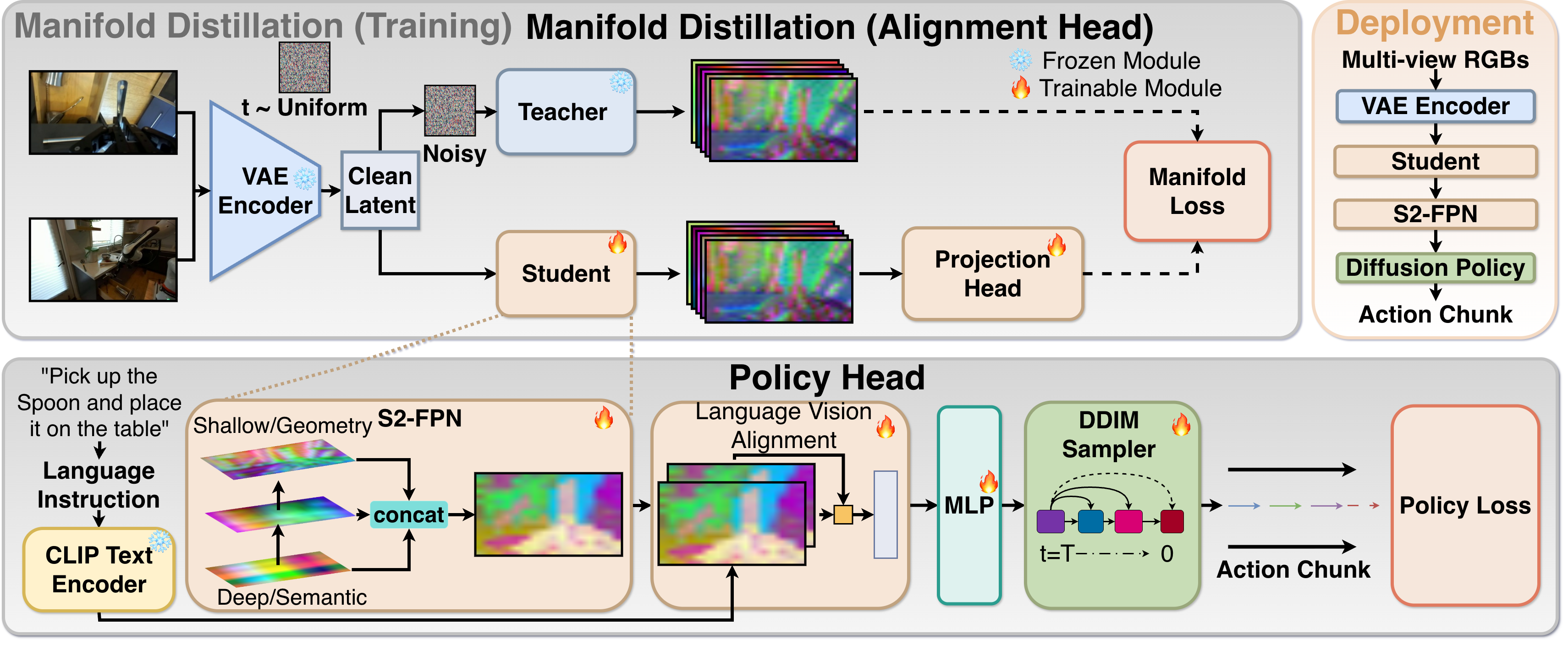
我们假设通用机器人操作中的一个关键瓶颈不仅仅是数据规模或策略能力,而是当前视觉骨干网络与闭环控制的物理需求之间的结构不匹配。虽然最先进的视觉编码器(包括VLA中使用的编码器)优化语义不变性以稳定分类,但操作通常需要几何敏感性,即能够将毫米级的姿态变化映射到可预测的特征变化。它们的判别目标为精细控制创建了一个“盲点”,而生成扩散模型固有地在其潜在流形中编码了几何依赖性,从而鼓励保留密集的、多尺度的空间结构。然而,直接部署随机扩散特征进行控制受到随机不稳定性、推理延迟和微调期间的表示漂移的阻碍。为了弥合这一差距,我们提出了Robot-DIFT,一个通过流形蒸馏将几何信息的来源与推理过程解耦的框架。通过将冻结的扩散教师模型提炼成确定性的空间-语义特征金字塔网络(S2-FPN),我们保留了生成模型丰富的几何先验,同时确保了时间稳定性、实时执行和对漂移的鲁棒性。在大型DROID数据集上预训练的Robot-DIFT展示了优于领先的判别基线的几何一致性和控制性能,支持了模型学习如何“看”决定了它能多好地学习如何“行动”的观点。
🔬 方法详解
问题定义:现有基于判别式视觉模型的机器人操作方法,由于其优化目标是语义不变性,导致模型对细微的几何变化不敏感,无法实现精确的闭环控制。这种“几何盲点”限制了机器人操作的泛化能力和性能。
核心思路:利用扩散模型在生成过程中天然地编码了几何依赖关系,将其作为几何信息的来源。通过知识蒸馏,将扩散模型中蕴含的几何先验知识迁移到一个确定性的、高效的特征提取网络中,从而克服判别式模型的局限性。
技术框架:Robot-DIFT框架包含一个冻结的扩散模型教师网络和一个可训练的空间-语义特征金字塔网络(S2-FPN)学生网络。首先,使用扩散模型提取图像的特征表示。然后,利用蒸馏损失,训练S2-FPN网络,使其能够模仿扩散模型的特征表示,从而获得几何敏感性。最后,将训练好的S2-FPN网络用于机器人控制任务。
关键创新:该方法的核心创新在于利用扩散模型作为几何信息的来源,并通过流形蒸馏的方式,将这些信息迁移到确定性的特征提取网络中。这种方法既保留了扩散模型的几何先验知识,又避免了直接使用扩散模型进行控制所带来的随机性和计算开销。
关键设计:S2-FPN网络的设计至关重要,它需要能够有效地捕捉图像中的空间和语义信息,并能够模仿扩散模型的特征表示。具体的网络结构和损失函数(例如,特征匹配损失)需要根据具体的任务进行调整。DROID数据集被用于预训练,以提供大规模的几何信息。
🖼️ 关键图片

📊 实验亮点
Robot-DIFT在几何一致性和控制性能方面均优于现有的判别式基线方法。实验结果表明,Robot-DIFT能够更准确地预测图像中像素的运动,并能够实现更精确的机器人操作。具体性能提升数据在论文中给出,证明了该方法的有效性。
🎯 应用场景
Robot-DIFT具有广泛的应用前景,例如高精度装配、精细操作、医疗机器人等领域。通过提升机器人对几何信息的感知能力,可以显著提高其操作精度、稳定性和泛化能力。未来,该方法有望应用于更复杂的机器人任务,例如自主导航、环境探索等。
📄 摘要(原文)
We hypothesize that a key bottleneck in generalizable robot manipulation is not solely data scale or policy capacity, but a structural mismatch between current visual backbones and the physical requirements of closed-loop control. While state-of-the-art vision encoders (including those used in VLAs) optimize for semantic invariance to stabilize classification, manipulation typically demands geometric sensitivity the ability to map millimeter-level pose shifts to predictable feature changes. Their discriminative objective creates a "blind spot" for fine-grained control, whereas generative diffusion models inherently encode geometric dependencies within their latent manifolds, encouraging the preservation of dense multi-scale spatial structure. However, directly deploying stochastic diffusion features for control is hindered by stochastic instability, inference latency, and representation drift during fine-tuning. To bridge this gap, we propose Robot-DIFT, a framework that decouples the source of geometric information from the process of inference via Manifold Distillation. By distilling a frozen diffusion teacher into a deterministic Spatial-Semantic Feature Pyramid Network (S2-FPN), we retain the rich geometric priors of the generative model while ensuring temporal stability, real-time execution, and robustness against drift. Pretrained on the large-scale DROID dataset, Robot-DIFT demonstrates superior geometric consistency and control performance compared to leading discriminative baselines, supporting the view that how a model learns to see dictates how well it can learn to act.