Learning to Manipulate Anything: Revealing Data Scaling Laws in Bounding-Box Guided Policies
作者: Yihao Wu, Jinming Ma, Junbo Tan, Yanzhao Yu, Shoujie Li, Mingliang Zhou, Diyun Xiang, Xueqian Wang
分类: cs.RO
发布日期: 2026-02-12
💡 一句话要点
提出基于边界框引导的策略,揭示语义操作中的数据缩放规律
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 扩散模型 边界框引导 语义操作 数据缩放规律
📋 核心要点
- 现有基于扩散模型的机器人操作策略依赖文本指令,难以在复杂环境中有效引导策略关注目标对象。
- 论文提出利用边界框指令直接指定目标对象,并设计语义-运动解耦框架,提升策略的泛化性和适应性。
- 通过大规模真实世界实验,验证了方法的有效性,并揭示了泛化性能与边界框对象数量之间的幂律关系。
📝 摘要(中文)
基于扩散模型的策略在语义操作中泛化能力有限,这是实际机器人部署的关键障碍。这种限制源于仅依赖文本指令不足以引导策略关注复杂动态环境中的目标对象。为了解决这个问题,我们提出利用边界框指令直接指定目标对象,并进一步研究语义操作任务中是否存在数据缩放规律。具体来说,我们设计了一个带有自动标注流水线的手持分割设备Label-UMI,可以高效收集带有语义标签的演示数据。我们还提出了一个语义-运动解耦框架,该框架集成了对象检测和边界框引导的扩散策略,以提高语义操作的泛化性和适应性。通过大规模真实世界实验,我们验证了该方法的有效性,并揭示了泛化性能与边界框对象数量之间的幂律关系。最后,我们总结了一种有效的语义操作数据收集策略,该策略在已见和未见对象的四个任务中均可实现85%的成功率。所有数据集和代码将向社区发布。
🔬 方法详解
问题定义:现有基于扩散模型的机器人操作策略,主要依赖文本指令来引导机器人完成语义操作任务。然而,在复杂和动态的环境中,仅凭文本指令很难精确地引导策略关注到目标对象,导致泛化能力不足。现有方法难以有效处理未见过的物体和场景,限制了其在真实世界中的应用。
核心思路:论文的核心思路是利用边界框(bounding box)信息来直接指定目标对象,从而更精确地引导机器人策略。通过结合对象检测和边界框引导的扩散策略,实现语义和运动的解耦,提高策略的泛化能力和适应性。此外,论文还探索了数据规模与策略性能之间的关系,旨在揭示语义操作任务中的数据缩放规律。
技术框架:整体框架包含数据收集、模型训练和策略执行三个主要阶段。首先,使用Label-UMI手持分割设备收集带有语义标签的演示数据,并构建大规模数据集。然后,训练一个语义-运动解耦的扩散模型,该模型以边界框信息作为条件,生成机器人的运动轨迹。最后,在真实机器人平台上执行策略,完成语义操作任务。该框架集成了对象检测模块,用于识别场景中的目标对象,并生成边界框信息,作为扩散模型的输入。
关键创新:论文的关键创新在于:1) 提出利用边界框信息直接引导机器人策略,克服了文本指令的局限性;2) 设计了语义-运动解耦框架,提高了策略的泛化能力;3) 揭示了语义操作任务中泛化性能与边界框对象数量之间的幂律关系,为数据收集提供了指导;4) 开发了Label-UMI手持分割设备,实现了高效的语义标注数据收集。
关键设计:Label-UMI设备采用手持式设计,方便在真实场景中进行数据采集。自动标注流水线能够高效地为采集到的图像数据添加语义标签。语义-运动解耦框架将策略分为语义理解和运动生成两个模块,分别处理对象识别和轨迹生成。扩散模型采用条件扩散模型,以边界框信息作为条件,生成机器人的运动轨迹。损失函数包括运动损失和语义一致性损失,用于优化模型的性能。
🖼️ 关键图片
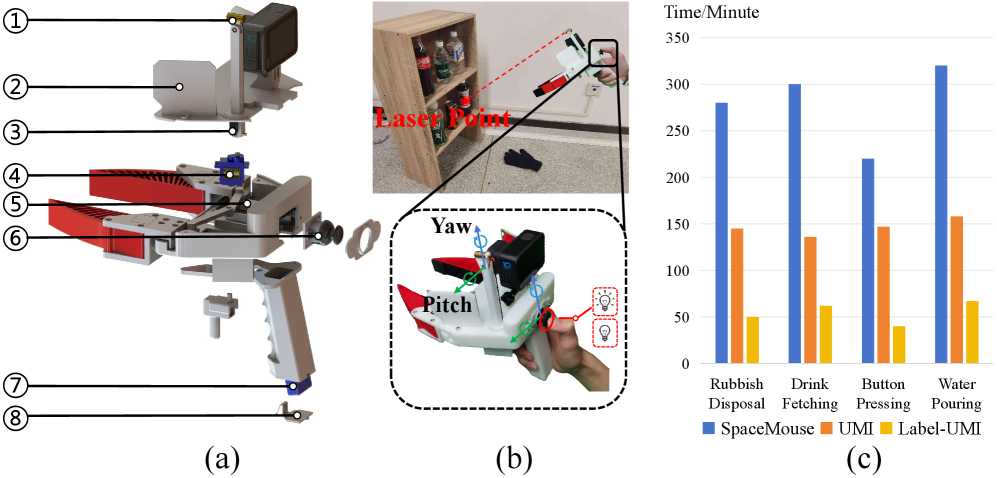
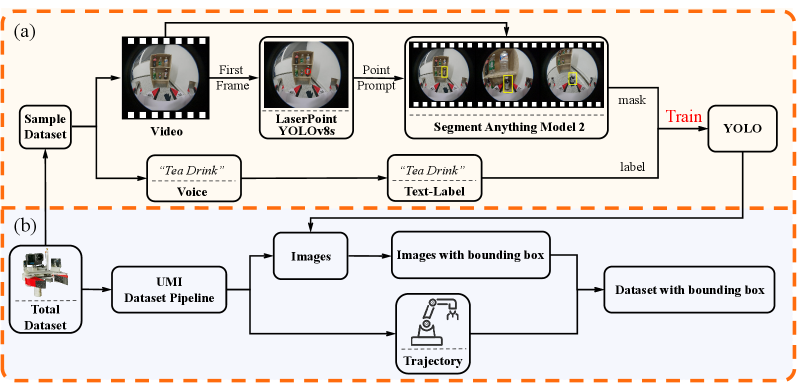
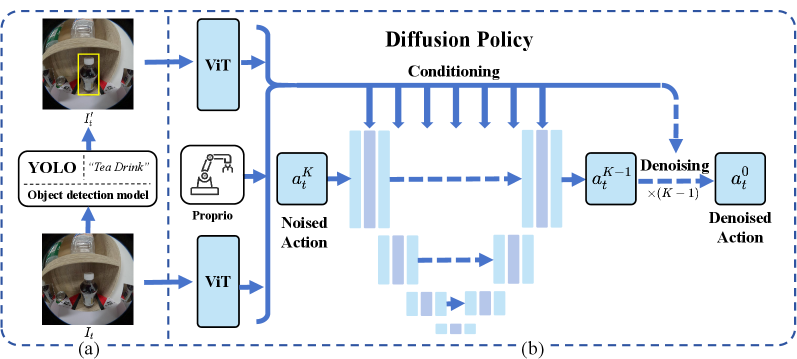
📊 实验亮点
实验结果表明,该方法在四个语义操作任务中均取得了显著的成功率,在已见和未见对象上均达到85%。通过大规模数据集的训练,验证了泛化性能与边界框对象数量之间的幂律关系。与仅使用文本指令的方法相比,该方法在泛化能力和适应性方面均有显著提升。
🎯 应用场景
该研究成果可应用于各种需要精确操作的机器人任务,例如智能制造、物流分拣、家庭服务等。通过边界框引导,机器人可以更准确地识别和操作目标对象,提高工作效率和安全性。未来的研究可以进一步探索更复杂的环境和任务,例如多对象操作、动态环境适应等,推动机器人技术在实际场景中的广泛应用。
📄 摘要(原文)
Diffusion-based policies show limited generalization in semantic manipulation, posing a key obstacle to the deployment of real-world robots. This limitation arises because relying solely on text instructions is inadequate to direct the policy's attention toward the target object in complex and dynamic environments. To solve this problem, we propose leveraging bounding-box instruction to directly specify target object, and further investigate whether data scaling laws exist in semantic manipulation tasks. Specifically, we design a handheld segmentation device with an automated annotation pipeline, Label-UMI, which enables the efficient collection of demonstration data with semantic labels. We further propose a semantic-motion-decoupled framework that integrates object detection and bounding-box guided diffusion policy to improve generalization and adaptability in semantic manipulation. Throughout extensive real-world experiments on large-scale datasets, we validate the effectiveness of the approach, and reveal a power-law relationship between generalization performance and the number of bounding-box objects. Finally, we summarize an effective data collection strategy for semantic manipulation, which can achieve 85\% success rates across four tasks on both seen and unseen objects. All datasets and code will be released to the community.