ViTaS: Visual Tactile Soft Fusion Contrastive Learning for Visuomotor Learning
作者: Yufeng Tian, Shuiqi Cheng, Tianming Wei, Tianxing Zhou, Yuanhang Zhang, Zixian Liu, Qianwei Han, Zhecheng Yuan, Huazhe Xu
分类: cs.RO, cs.AI, cs.CV
发布日期: 2026-02-12
备注: Published to ICRA 2026
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ViTaS:基于视觉触觉软融合对比学习的机器人灵巧操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉触觉融合 对比学习 机器人操作 软融合 CVAE 多模态学习 机器人灵巧操作
📋 核心要点
- 现有视觉触觉融合方法主要关注特征对齐和直接拼接,忽略了模态互补性,导致在遮挡场景下性能下降。
- ViTaS框架通过软融合对比学习和CVAE模块,显式地利用视觉和触觉信息的对齐性和互补性,提升鲁棒性。
- 实验结果表明,ViTaS在模拟和真实环境中均显著优于现有基线,验证了其有效性。
📝 摘要(中文)
触觉信息在人类操作任务中起着关键作用,并且最近在机器人操作中受到了越来越多的关注。然而,现有的方法主要集中在视觉和触觉特征的对齐上,并且融合机制倾向于直接连接。因此,由于忽略了两种模态固有的互补性,并且对齐可能没有得到充分利用,它们难以有效地应对遮挡场景,限制了它们在现实世界中的部署潜力。在本文中,我们提出了一种简单而有效的框架ViTaS,它结合了视觉和触觉信息来指导智能体的行为。我们引入了软融合对比学习,这是一种传统对比学习方法的改进版本,以及一个CVAE模块,以利用视觉-触觉表征中的对齐和互补性。我们在12个模拟环境和3个真实世界环境中证明了我们方法的有效性,我们的实验表明ViTaS明显优于现有的基线。
🔬 方法详解
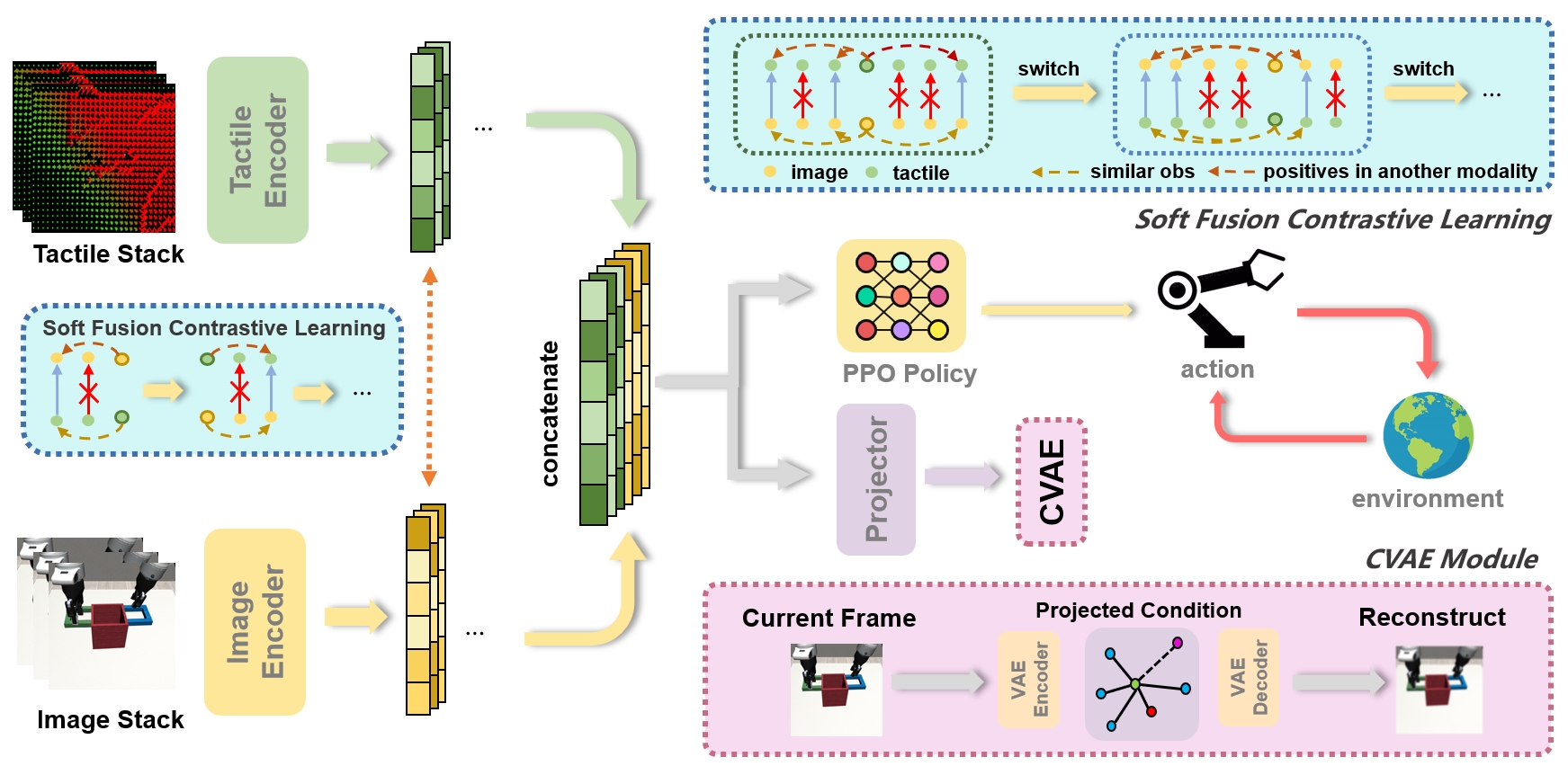
问题定义:现有基于视觉和触觉的机器人操作方法,在融合视觉和触觉信息时,通常采用直接拼接的方式,忽略了两种模态之间的互补性。此外,现有的对齐方法可能无法充分利用视觉和触觉信息之间的关联,导致在遮挡等复杂场景下性能下降。因此,如何有效利用视觉和触觉信息的互补性和对齐性,是本文要解决的关键问题。
核心思路:ViTaS的核心思路是利用软融合对比学习(Soft Fusion Contrastive Learning)和条件变分自编码器(CVAE)来显式地建模视觉和触觉信息的对齐性和互补性。通过对比学习,鼓励相似的视觉-触觉对具有更接近的表示,而通过CVAE,可以学习到两种模态之间的条件依赖关系,从而更好地利用它们的互补性。
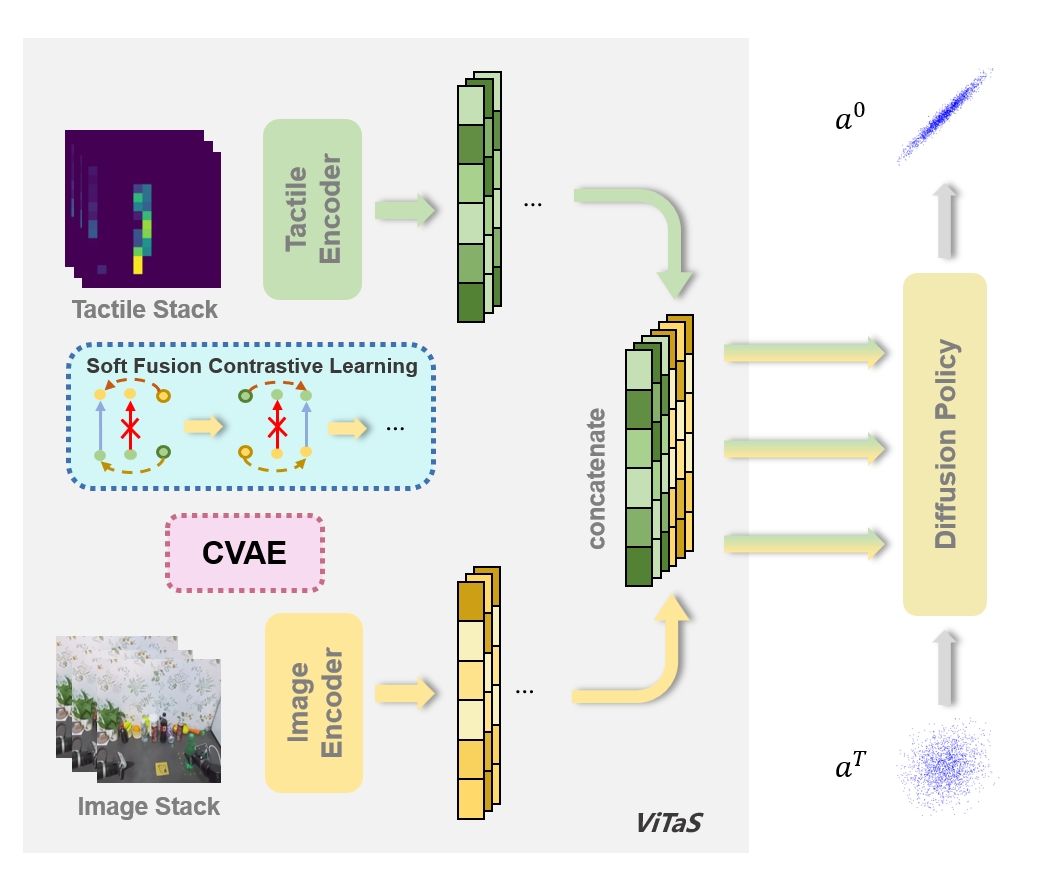
技术框架:ViTaS框架主要包含以下几个模块:1) 视觉编码器和触觉编码器,用于提取视觉和触觉特征;2) 软融合模块,用于将视觉和触觉特征进行融合,该模块允许模型学习不同模态的权重,实现软融合;3) 对比学习模块,使用改进的对比学习方法,学习视觉和触觉特征的对齐表示;4) CVAE模块,用于建模视觉和触觉特征之间的条件依赖关系,从而利用它们的互补性。整个框架通过端到端的方式进行训练。
关键创新:ViTaS的关键创新在于提出了软融合对比学习方法,该方法在传统的对比学习基础上,引入了软融合机制,允许模型学习不同模态的权重,从而更好地利用视觉和触觉信息的互补性。此外,CVAE模块的引入,也使得模型能够更好地建模视觉和触觉特征之间的条件依赖关系。
关键设计:在软融合模块中,使用了注意力机制来学习不同模态的权重。对比学习损失函数采用了InfoNCE损失,并进行了一些改进,以更好地适应视觉和触觉信息的特点。CVAE模块采用了标准的变分自编码器结构,并使用视觉特征作为条件信息,来重构触觉特征。
🖼️ 关键图片

📊 实验亮点
ViTaS在12个模拟环境和3个真实世界环境中进行了评估,实验结果表明,ViTaS显著优于现有的基线方法。例如,在某些任务中,ViTaS的性能提升超过了10%。这些结果表明,ViTaS能够有效地利用视觉和触觉信息的互补性和对齐性,从而提升机器人的操作性能。
🎯 应用场景
ViTaS框架可应用于各种需要视觉和触觉信息融合的机器人操作任务,例如物体抓取、装配、表面探索等。该研究成果有助于提升机器人在复杂环境下的操作能力和鲁棒性,使其能够更好地适应现实世界的挑战,具有广泛的应用前景。
📄 摘要(原文)
Tactile information plays a crucial role in human manipulation tasks and has recently garnered increasing attention in robotic manipulation. However, existing approaches mostly focus on the alignment of visual and tactile features and the integration mechanism tends to be direct concatenation. Consequently, they struggle to effectively cope with occluded scenarios due to neglecting the inherent complementary nature of both modalities and the alignment may not be exploited enough, limiting the potential of their real-world deployment. In this paper, we present ViTaS, a simple yet effective framework that incorporates both visual and tactile information to guide the behavior of an agent. We introduce Soft Fusion Contrastive Learning, an advanced version of conventional contrastive learning method and a CVAE module to utilize the alignment and complementarity within visuo-tactile representations. We demonstrate the effectiveness of our method in 12 simulated and 3 real-world environments, and our experiments show that ViTaS significantly outperforms existing baselines. Project page: https://skyrainwind.github.io/ViTaS/index.html.