APEX: Learning Adaptive High-Platform Traversal for Humanoid Robots
作者: Yikai Wang, Tingxuan Leng, Changyi Lin, Shiqi Liu, Shir Simon, Bingqing Chen, Jonathan Francis, Ding Zhao
分类: cs.RO
发布日期: 2026-02-11
备注: Project Website: https://apex-humanoid.github.io/
💡 一句话要点
APEX:学习人型机器人自适应高平台攀爬策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 人型机器人 强化学习 高平台穿越 攀爬 地形感知 模拟到真实 多技能学习
📋 核心要点
- 现有基于深度强化学习的人型机器人运动方法难以处理超出腿长的平台,容易收敛到跳跃式解决方案,存在冲击大、扭矩受限和不安全等问题。
- APEX系统通过组合攀爬、行走等多种行为,并引入广义棘轮式进度奖励,实现安全高效的平台穿越学习,解决了现有方法的局限性。
- 实验表明,APEX系统在Unitree G1机器人上实现了0.8米平台的零样本模拟到真实穿越,并能适应不同的平台高度和初始姿势。
📝 摘要(中文)
本文提出了一种名为APEX的系统,用于实现人型机器人基于攀爬的高平台穿越。该系统能够感知地形并组合多种行为:垂直边缘的向上和向下攀爬、平台上的行走或爬行,以及用于姿态重构的站立和躺下。核心在于一种广义棘轮式进度奖励,用于学习富含接触、目标导向的动作。它跟踪迄今为止的最佳任务进度,并惩罚非改进步骤,提供密集且无速度监督,从而在强大的安全正则化下实现高效探索。基于此,我们训练了基于激光雷达的全身动作策略,并通过双重策略减少了模拟到真实的感知差距:在训练期间对映射伪影进行建模,并在部署期间对高程图应用过滤和修复。最后,我们将所有六种技能提炼成一个单一策略,该策略基于局部几何和命令自主选择行为和转换。在29自由度Unitree G1人型机器人上的实验表明,实现了0.8米平台(约占腿长的114%)的零样本模拟到真实穿越,并能鲁棒地适应平台高度和初始姿势,以及平稳稳定的多技能转换。
🔬 方法详解
问题定义:现有基于深度强化学习的人形机器人运动方法在处理高平台穿越任务时,往往会学习到跳跃式的策略。这种策略冲击力大,容易超出机器人的扭矩限制,并且在实际应用中存在安全隐患。因此,需要一种能够让人形机器人安全、稳定地穿越高平台的策略。
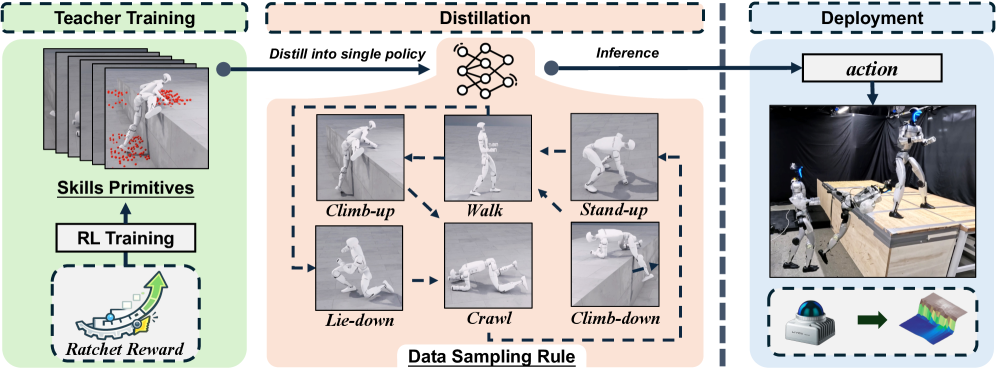
核心思路:APEX的核心思路是将高平台穿越任务分解为多个子任务,包括向上攀爬、向下攀爬、在平台上行走或爬行、站立和躺下等。通过学习这些子任务的策略,并将其组合起来,实现整体的高平台穿越。此外,APEX还引入了一种广义棘轮式进度奖励,用于鼓励机器人探索更有效的策略,并避免陷入局部最优。
技术框架:APEX系统的整体框架包括以下几个主要模块:1) 感知模块:使用激光雷达获取环境信息,并生成高程图。2) 行为策略模块:学习各种子任务的策略,包括向上攀爬、向下攀爬、在平台上行走或爬行、站立和躺下等。3) 行为选择模块:根据当前的环境信息和任务目标,选择合适的行为策略。4) 控制模块:根据选择的行为策略,控制机器人的运动。
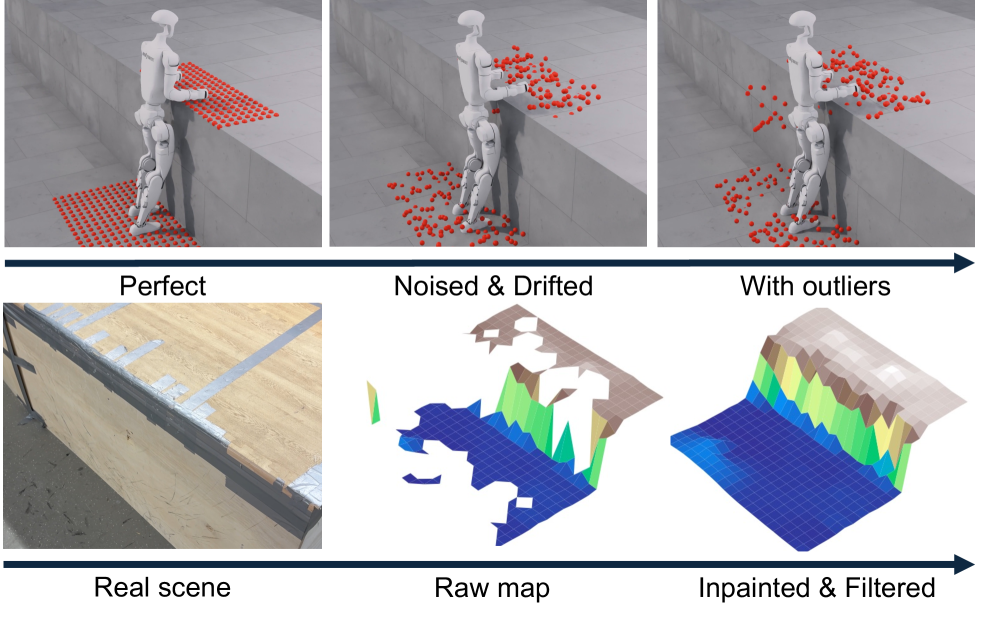
关键创新:APEX的几个关键创新点包括:1) 提出了一种广义棘轮式进度奖励,用于鼓励机器人探索更有效的策略。2) 采用了一种双重策略来减少模拟到真实的感知差距,包括在训练期间对映射伪影进行建模,并在部署期间对高程图应用过滤和修复。3) 将所有子任务的策略提炼成一个单一策略,该策略可以根据局部几何和命令自主选择行为和转换。
关键设计:广义棘轮式进度奖励的设计是APEX的关键。该奖励函数跟踪迄今为止的最佳任务进度,并惩罚非改进步骤,从而提供密集且无速度监督,使得机器人能够在强大的安全正则化下实现高效探索。此外,为了减少模拟到真实的感知差距,APEX在训练期间对激光雷达的映射伪影进行建模,并在部署期间对高程图应用过滤和修复。
🖼️ 关键图片

📊 实验亮点
实验结果表明,APEX系统在Unitree G1人型机器人上实现了0.8米平台(约占腿长的114%)的零样本模拟到真实穿越。该系统能够鲁棒地适应平台高度和初始姿势的变化,并实现平稳稳定的多技能转换。这些结果表明,APEX系统具有很强的泛化能力和实用价值。
🎯 应用场景
该研究成果可应用于搜救、勘探、建筑等领域,使人型机器人能够在复杂地形环境下执行任务,例如在高处或狭窄空间进行作业。通过提升机器人的环境适应性和运动能力,可以降低人类在危险环境中的工作风险,提高工作效率。
📄 摘要(原文)
Humanoid locomotion has advanced rapidly with deep reinforcement learning (DRL), enabling robust feet-based traversal over uneven terrain. Yet platforms beyond leg length remain largely out of reach because current RL training paradigms often converge to jumping-like solutions that are high-impact, torque-limited, and unsafe for real-world deployment. To address this gap, we propose APEX, a system for perceptive, climbing-based high-platform traversal that composes terrain-conditioned behaviors: climb-up and climb-down at vertical edges, walking or crawling on the platform, and stand-up and lie-down for posture reconfiguration. Central to our approach is a generalized ratchet progress reward for learning contact-rich, goal-reaching maneuvers. It tracks the best-so-far task progress and penalizes non-improving steps, providing dense yet velocity-free supervision that enables efficient exploration under strong safety regularization. Based on this formulation, we train LiDAR-based full-body maneuver policies and reduce the sim-to-real perception gap through a dual strategy: modeling mapping artifacts during training and applying filtering and inpainting to elevation maps during deployment. Finally, we distill all six skills into a single policy that autonomously selects behaviors and transitions based on local geometry and commands. Experiments on a 29-DoF Unitree G1 humanoid demonstrate zero-shot sim-to-real traversal of 0.8 meter platforms (approximately 114% of leg length), with robust adaptation to platform height and initial pose, as well as smooth and stable multi-skill transitions.