Data-Efficient Hierarchical Goal-Conditioned Reinforcement Learning via Normalizing Flows
作者: Shaswat Garg, Matin Moezzi, Brandon Da Silva
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-02-11
备注: 9 pages, 3 figures, IEEE International Conference on Robotics and Automation 2026
💡 一句话要点
提出NF-HIQL,通过Normalizing Flow提升分层强化学习的数据效率和策略表达能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分层强化学习 Normalizing Flow 目标条件强化学习 数据效率 多模态策略
📋 核心要点
- 分层强化学习在长时程任务中面临数据效率低和策略表达能力不足的挑战,尤其是在数据稀缺场景下。
- NF-HIQL利用Normalizing Flow构建高表达能力的策略,从而能够建模多模态行为,并提升数据利用率。
- 实验表明,NF-HIQL在多种复杂任务中超越了现有方法,验证了其在数据效率和鲁棒性方面的优势。
📝 摘要(中文)
本文提出了一种基于Normalizing Flow的分层隐式Q学习框架(NF-HIQL),旨在解决分层目标条件强化学习(H-GCRL)中数据效率低和策略表达能力有限的问题,尤其是在离线或数据稀缺的情况下。NF-HIQL在高层和低层都用富有表达能力的Normalizing Flow策略取代了单峰高斯策略。这种设计实现了可处理的对数似然计算、高效的采样以及对丰富多模态行为的建模能力。论文推导了新的理论保证,包括RealNVP策略的显式KL散度界限和PAC风格的样本效率结果,表明NF-HIQL在提高泛化能力的同时保持了稳定性。在OGBench中的运动、运球和多步操作等多种长时程任务中,NF-HIQL始终优于先前的目标条件和分层基线,证明了其在有限数据下卓越的鲁棒性,并突出了基于Flow的架构在可扩展、数据高效的分层强化学习中的潜力。
🔬 方法详解
问题定义:分层目标条件强化学习(H-GCRL)在解决复杂、长时程任务时,由于数据效率低和策略表达能力有限,导致其在实际应用中受到限制。尤其是在离线或数据稀缺的情况下,学习高质量的分层策略变得更加困难。现有的方法通常使用高斯策略,无法捕捉复杂的多模态行为,限制了其性能。
核心思路:NF-HIQL的核心思路是利用Normalizing Flow来构建高表达能力的策略,从而解决H-GCRL中数据效率和策略表达能力的问题。Normalizing Flow能够将简单的分布转换为复杂的分布,因此可以用来建模多模态行为。通过在高层和低层都使用Normalizing Flow策略,NF-HIQL能够学习更丰富、更有效的分层策略。
技术框架:NF-HIQL是一个分层强化学习框架,包含高层策略和低层策略。高层策略负责生成子目标,低层策略负责实现这些子目标。两个层级的策略都使用Normalizing Flow进行建模。整个训练过程基于隐式Q学习(IQL),通过最大化Q函数的期望来学习策略。框架的关键组成部分包括:Normalizing Flow策略网络、Q函数网络和目标生成器。
关键创新:NF-HIQL的关键创新在于使用Normalizing Flow来建模分层策略。与传统的高斯策略相比,Normalizing Flow能够表达更复杂的分布,从而可以建模多模态行为。此外,论文还推导了RealNVP策略的KL散度界限和PAC风格的样本效率结果,为NF-HIQL的理论性能提供了保证。
关键设计:NF-HIQL使用RealNVP作为Normalizing Flow的具体实现。RealNVP是一种易于计算对数似然和进行采样的Normalizing Flow。损失函数包括IQL损失和正则化项,用于约束策略的复杂性。网络结构采用多层感知机(MLP),并根据任务的复杂性进行调整。关键参数包括学习率、批量大小和正则化系数。
🖼️ 关键图片
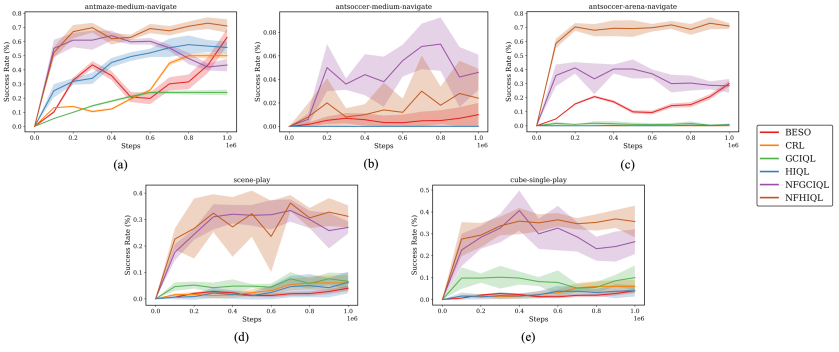

📊 实验亮点
实验结果表明,NF-HIQL在多个长时程任务中显著优于现有的分层强化学习方法。例如,在OGBench的运动、运球和多步操作任务中,NF-HIQL在数据效率和最终性能方面都取得了显著提升。与基线方法相比,NF-HIQL在有限数据下表现出更强的鲁棒性,验证了其在数据稀缺场景下的优势。
🎯 应用场景
NF-HIQL具有广泛的应用前景,例如机器人操作、自动驾驶和游戏AI等领域。在机器人操作中,可以利用NF-HIQL来训练机器人完成复杂的装配任务。在自动驾驶中,可以利用NF-HIQL来规划车辆的行驶路线。在游戏AI中,可以利用NF-HIQL来训练AI角色进行复杂的策略决策。该研究有望推动强化学习在实际应用中的发展。
📄 摘要(原文)
Hierarchical goal-conditioned reinforcement learning (H-GCRL) provides a powerful framework for tackling complex, long-horizon tasks by decomposing them into structured subgoals. However, its practical adoption is hindered by poor data efficiency and limited policy expressivity, especially in offline or data-scarce regimes. In this work, Normalizing flow-based hierarchical implicit Q-learning (NF-HIQL), a novel framework that replaces unimodal gaussian policies with expressive normalizing flow policies at both the high- and low-levels of the hierarchy is introduced. This design enables tractable log-likelihood computation, efficient sampling, and the ability to model rich multimodal behaviors. New theoretical guarantees are derived, including explicit KL-divergence bounds for Real-valued non-volume preserving (RealNVP) policies and PAC-style sample efficiency results, showing that NF-HIQL preserves stability while improving generalization. Empirically, NF-HIQL is evaluted across diverse long-horizon tasks in locomotion, ball-dribbling, and multi-step manipulation from OGBench. NF-HIQL consistently outperforms prior goal-conditioned and hierarchical baselines, demonstrating superior robustness under limited data and highlighting the potential of flow-based architectures for scalable, data-efficient hierarchical reinforcement learning.