RISE: Self-Improving Robot Policy with Compositional World Model
作者: Jiazhi Yang, Kunyang Lin, Jinwei Li, Wencong Zhang, Tianwei Lin, Longyan Wu, Zhizhong Su, Hao Zhao, Ya-Qin Zhang, Li Chen, Ping Luo, Xiangyu Yue, Hongyang Li
分类: cs.RO
发布日期: 2026-02-11
备注: Project page: https://opendrivelab.com/kai0-rl/
💡 一句话要点
RISE:基于可组合世界模型的自提升机器人策略,解决复杂操作任务中的鲁棒性问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人强化学习 世界模型 视觉语言动作模型 组合模型 自提升策略
📋 核心要点
- 视觉-语言-动作(VLA)模型在复杂操作任务中仍然脆弱,小的执行偏差可能导致失败,是当前面临的核心问题。
- RISE通过构建可组合世界模型,在想象空间中进行强化学习,避免了物理世界交互的成本和风险,从而提升策略的鲁棒性。
- 实验表明,RISE在动态砖块排序、背包打包和箱子关闭等任务中,性能显著优于现有技术,实现了大幅度的性能提升。
📝 摘要(中文)
本文提出RISE,一个通过想象进行机器人强化学习的可扩展框架。其核心是一个可组合世界模型,该模型(i)通过可控的动力学模型预测多视角未来,以及(ii)使用进度价值模型评估想象的结果,从而为策略改进产生信息丰富的优势函数。这种组合式设计允许状态和价值由最适合但不同的架构和目标进行定制。这些组件被集成到一个闭环自提升管道中,该管道持续生成想象的rollout,估计优势函数,并在想象空间中更新策略,而无需昂贵的物理交互。在三个具有挑战性的真实世界任务中,RISE相对于现有技术产生了显著的改进,在动态砖块排序中性能绝对提升超过+35%,背包打包提升+45%,箱子关闭提升+35%。
🔬 方法详解
问题定义:现有视觉-语言-动作模型在接触密集和动态操作任务中表现出脆弱性,即使是微小的执行偏差也可能导致任务失败。传统的强化学习方法虽然可以提高鲁棒性,但直接在真实物理世界中进行on-policy强化学习面临安全风险、硬件成本高昂以及环境重置困难等问题。
核心思路:RISE的核心思路是通过构建一个可组合的世界模型,在想象的环境中进行强化学习。该世界模型能够预测未来的状态,并评估不同动作序列的价值,从而为策略改进提供指导。通过在想象空间中进行学习,可以避免与真实环境的直接交互,从而降低成本和风险。
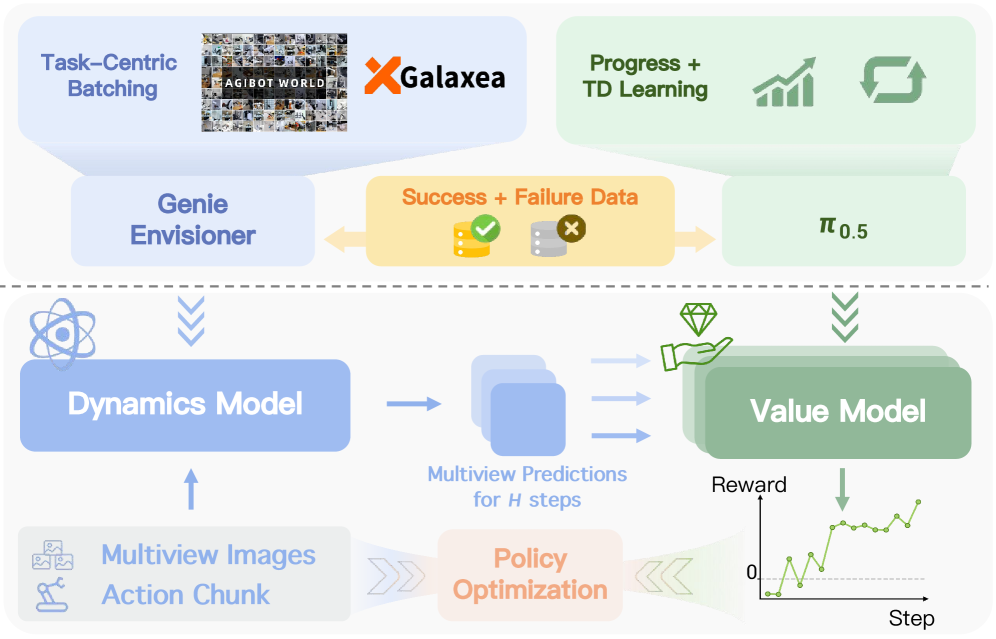
技术框架:RISE框架包含以下主要模块:1) 可控动力学模型:用于预测多视角下的未来状态。2) 进度价值模型:用于评估想象结果的价值,为策略改进提供优势函数。3) 策略网络:用于生成动作。整个框架采用闭环自提升的流程,不断生成想象的rollout,估计优势函数,并在想象空间中更新策略。
关键创新:RISE的关键创新在于其可组合的世界模型设计。该模型将状态预测和价值评估解耦,允许使用不同的架构和目标函数来分别优化这两个模块。这种解耦设计使得模型能够更好地捕捉复杂环境的动态特性,并更准确地评估动作的价值。此外,在想象环境中进行强化学习,避免了真实环境交互的成本和风险。
关键设计:可控动力学模型采用多视角预测,以更全面地捕捉环境状态。进度价值模型的设计旨在提供信息丰富的优势函数,引导策略向更有利的方向改进。策略网络的设计需要与动力学模型和价值模型相匹配,以实现有效的策略学习。具体的网络结构、损失函数和参数设置需要根据具体任务进行调整。
🖼️ 关键图片

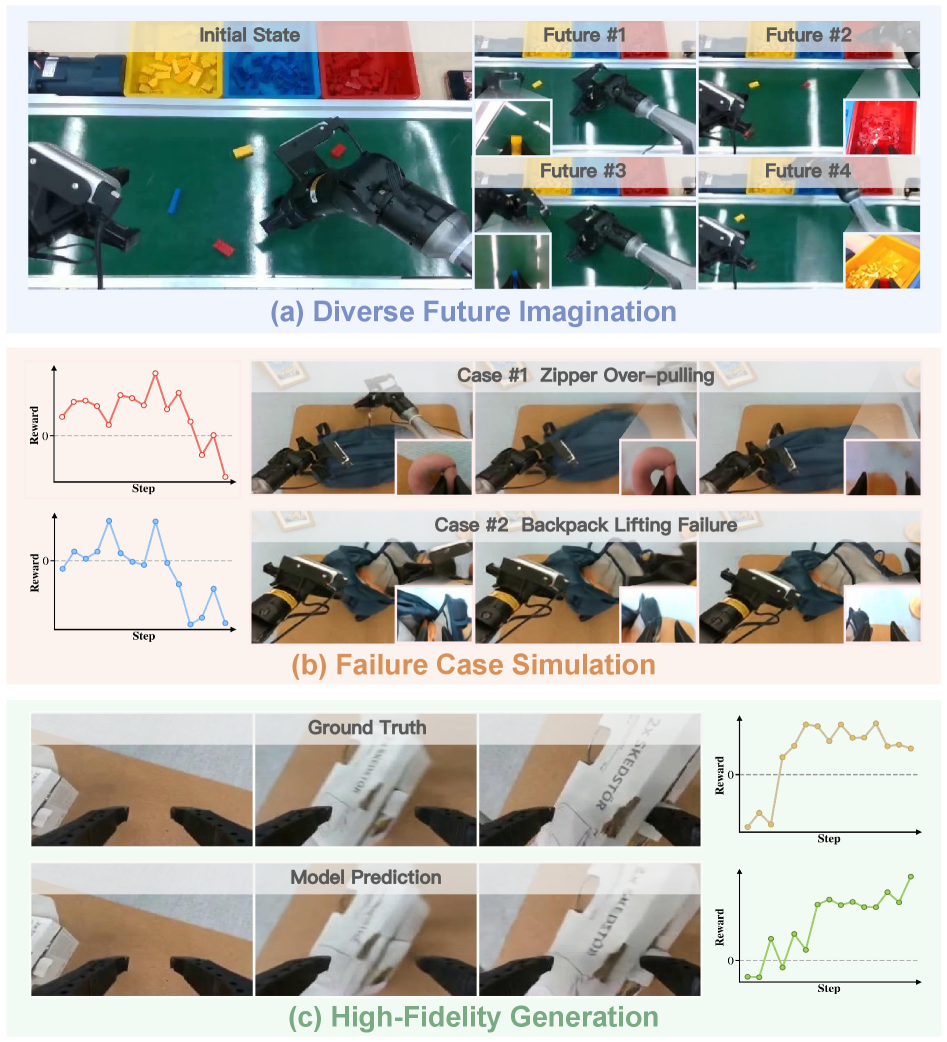
📊 实验亮点
RISE在三个具有挑战性的真实世界任务中取得了显著的性能提升。在动态砖块排序任务中,RISE的性能绝对提升超过35%;在背包打包任务中,性能提升45%;在箱子关闭任务中,性能提升35%。这些结果表明,RISE框架能够有效地提高机器人在复杂操作任务中的性能。
🎯 应用场景
RISE框架具有广泛的应用前景,可应用于各种需要机器人进行复杂操作的场景,例如智能制造、物流仓储、家庭服务等。通过在虚拟环境中进行训练,可以显著降低机器人部署的成本和风险,并提高机器人的鲁棒性和适应性。该研究有望推动机器人技术在实际应用中的普及。
📄 摘要(原文)
Despite the sustained scaling on model capacity and data acquisition, Vision-Language-Action (VLA) models remain brittle in contact-rich and dynamic manipulation tasks, where minor execution deviations can compound into failures. While reinforcement learning (RL) offers a principled path to robustness, on-policy RL in the physical world is constrained by safety risk, hardware cost, and environment reset. To bridge this gap, we present RISE, a scalable framework of robotic reinforcement learning via imagination. At its core is a Compositional World Model that (i) predicts multi-view future via a controllable dynamics model, and (ii) evaluates imagined outcomes with a progress value model, producing informative advantages for the policy improvement. Such compositional design allows state and value to be tailored by best-suited yet distinct architectures and objectives. These components are integrated into a closed-loop self-improving pipeline that continuously generates imaginary rollouts, estimates advantages, and updates the policy in imaginary space without costly physical interaction. Across three challenging real-world tasks, RISE yields significant improvement over prior art, with more than +35% absolute performance increase in dynamic brick sorting, +45% for backpack packing, and +35% for box closing, respectively.