RADAR: Benchmarking Vision-Language-Action Generalization via Real-World Dynamics, Spatial-Physical Intelligence, and Autonomous Evaluation
作者: Yuhao Chen, Zhihao Zhan, Xiaoxin Lin, Zijian Song, Hao Liu, Qinhan Lyu, Yubo Zu, Xiao Chen, Zhiyuan Liu, Tao Pu, Tianshui Chen, Keze Wang, Liang Lin, Guangrun Wang
分类: cs.RO
发布日期: 2026-02-11
备注: 12 pages, 11 figures, 3 tables
💡 一句话要点
RADAR:通过真实世界动力学、空间物理智能和自主评估,对视觉-语言-动作泛化能力进行基准测试。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 具身智能 真实世界动力学 空间推理 自主评估 基准测试 泛化能力 机器人
📋 核心要点
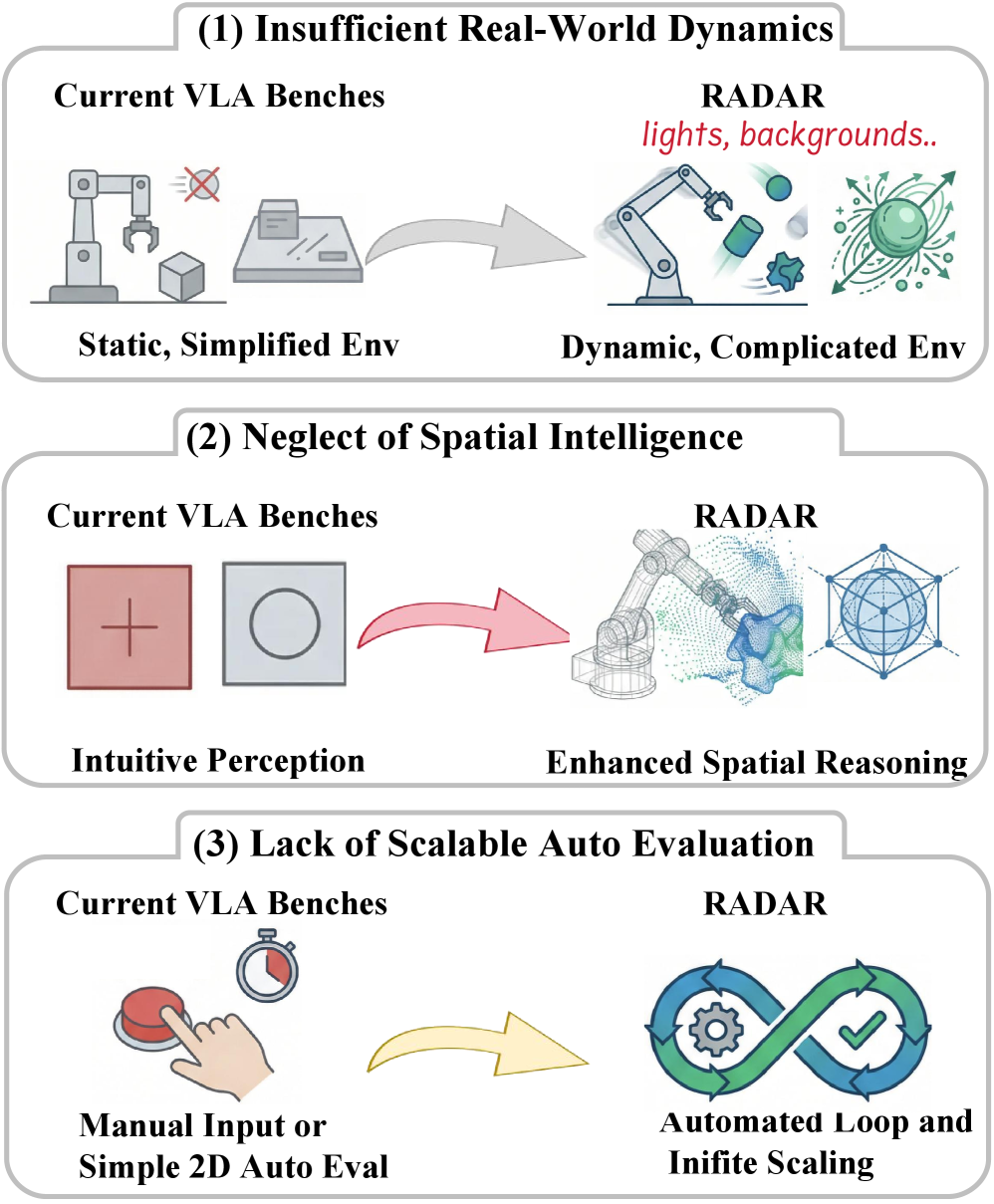
- 现有VLA模型评估主要依赖模拟环境,忽略了真实世界动力学、空间物理智能等关键因素,导致泛化能力评估不准确。
- RADAR基准通过引入真实的物理动力学、空间推理任务和全自主3D评估流程,系统地评估VLA模型在真实环境中的泛化能力。
- 实验表明,现有VLA模型在RADAR基准上表现出严重的脆弱性,尤其是在存在传感器噪声和需要空间推理时,性能显著下降。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在具身智能领域取得了显著进展,但其评估仍主要局限于模拟环境或高度受限的真实环境。这种不匹配造成了巨大的现实差距,强大的基准性能往往掩盖了在多样物理环境中较差的泛化能力。本文指出了当前基准测试实践中阻碍公平可靠模型比较的三个系统性缺陷:(1)现有基准未能模拟真实世界动力学,忽略了动态对象配置、机器人初始状态、光照变化和传感器噪声等关键因素。(2)当前协议忽略了空间-物理智能,将评估简化为死记硬背的操作任务,而没有探究几何推理。(3)该领域缺乏可扩展的完全自主评估,而是依赖于忽略3D空间结构的简单2D指标或成本高昂、有偏见且不可扩展的人工参与系统。为了解决这些局限性,我们引入了RADAR(Real-world Autonomous Dynamics And Reasoning),这是一个旨在系统评估VLA模型在真实条件下泛化能力的基准。RADAR集成了三个核心组件:(1)一套基于原则的物理动力学;(2)专门用于显式测试空间推理和物理理解的任务;(3)一个基于3D指标的完全自主评估流程,无需人工监督。我们应用RADAR来评估多个最先进的VLA模型,并揭示了其表面能力之下的严重脆弱性。在适度的物理动力学下,性能急剧下降,在传感器噪声下,3D IoU的预期从0.261下降到0.068。此外,模型表现出有限的空间推理能力。这些发现使RADAR成为可靠和可泛化的VLA模型真实世界评估的必要基准。
🔬 方法详解
问题定义:现有VLA模型的评估主要依赖于模拟环境或受限的真实环境,无法充分评估模型在复杂、动态的真实世界中的泛化能力。现有基准测试忽略了真实世界动力学(如动态物体配置、光照变化、传感器噪声)和空间物理智能(几何推理能力),并且依赖人工评估,成本高昂且存在偏差。
核心思路:RADAR的核心思路是构建一个更贴近真实世界的VLA模型评估基准,通过引入真实的物理动力学、专门设计的空间推理任务和全自主的3D评估流程,来系统地评估模型在真实环境中的泛化能力。这样可以更准确地反映模型在实际应用中的性能。
技术框架:RADAR基准包含三个核心组件:1) 物理动力学模拟:模拟真实世界中的各种物理现象,如物体碰撞、摩擦、重力等,以及传感器噪声和光照变化。2) 空间推理任务:设计需要模型进行空间推理和物理理解的任务,例如,根据指令移动物体到指定位置,或者预测物体在特定操作后的状态。3) 全自主评估流程:使用3D指标(如3D IoU)来评估模型的性能,无需人工干预,从而实现可扩展的评估。
关键创新:RADAR的关键创新在于其全面性和真实性。它不仅考虑了物理动力学,还引入了空间推理任务,并采用全自主的3D评估流程。这使得RADAR能够更准确地评估VLA模型在真实世界中的泛化能力,并发现现有模型在这些方面的不足。与现有方法相比,RADAR更注重模型的实际应用价值。
关键设计:RADAR中的物理动力学模拟使用了物理引擎来模拟真实世界的物理现象。空间推理任务的设计需要仔细考虑任务的难度和多样性,以确保能够充分评估模型的空间推理能力。全自主评估流程的关键在于选择合适的3D指标,并设计有效的算法来计算这些指标。例如,可以使用3D IoU来评估模型对物体位置和形状的预测精度。
🖼️ 关键图片


📊 实验亮点
在RADAR基准上,现有VLA模型表现出明显的性能下降。例如,在引入传感器噪声后,模型的3D IoU从0.261大幅下降到0.068,表明模型对噪声非常敏感。此外,模型在空间推理任务上的表现也远低于预期,表明模型在理解和推理空间关系方面存在不足。这些结果表明,现有VLA模型在真实世界中的泛化能力仍然有限,需要进一步改进。
🎯 应用场景
RADAR基准的提出,能够推动VLA模型在机器人、自动驾驶、智能家居等领域的应用。通过更真实、更全面的评估,可以促进VLA模型在复杂环境下的泛化能力,从而提高机器人在实际场景中的自主性和可靠性。此外,RADAR还可以用于评估不同VLA模型的优劣,指导模型的设计和优化。
📄 摘要(原文)
VLA models have achieved remarkable progress in embodied intelligence; however, their evaluation remains largely confined to simulations or highly constrained real-world settings. This mismatch creates a substantial reality gap, where strong benchmark performance often masks poor generalization in diverse physical environments. We identify three systemic shortcomings in current benchmarking practices that hinder fair and reliable model comparison. (1) Existing benchmarks fail to model real-world dynamics, overlooking critical factors such as dynamic object configurations, robot initial states, lighting changes, and sensor noise. (2) Current protocols neglect spatial--physical intelligence, reducing evaluation to rote manipulation tasks that do not probe geometric reasoning. (3) The field lacks scalable fully autonomous evaluation, instead relying on simplistic 2D metrics that miss 3D spatial structure or on human-in-the-loop systems that are costly, biased, and unscalable. To address these limitations, we introduce RADAR (Real-world Autonomous Dynamics And Reasoning), a benchmark designed to systematically evaluate VLA generalization under realistic conditions. RADAR integrates three core components: (1) a principled suite of physical dynamics; (2) dedicated tasks that explicitly test spatial reasoning and physical understanding; and (3) a fully autonomous evaluation pipeline based on 3D metrics, eliminating the need for human supervision. We apply RADAR to audit multiple state-of-the-art VLA models and uncover severe fragility beneath their apparent competence. Performance drops precipitously under modest physical dynamics, with the expectation of 3D IoU declining from 0.261 to 0.068 under sensor noise. Moreover, models exhibit limited spatial reasoning capability. These findings position RADAR as a necessary bench toward reliable and generalizable real-world evaluation of VLA models.