From Representational Complementarity to Dual Systems: Synergizing VLM and Vision-Only Backbones for End-to-End Driving
作者: Sining Ang, Yuguang Yang, Chenxu Dang, Canyu Chen, Cheng Chi, Haiyan Liu, Xuanyao Mao, Jason Bao, Xuliang, Bingchuan Sun, Yan Wang
分类: cs.RO, cs.CV
发布日期: 2026-02-11
备注: 22 pages (10 pages main text + 12 pages appendix), 18 figures
💡 一句话要点
HybridDriveVLA:融合VLM与纯视觉骨干网络,提升端到端驾驶性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端到端驾驶 视觉语言模型 表征互补性 模型融合 自动驾驶 长尾场景 Transformer规划器
📋 核心要点
- 现有端到端驾驶方法依赖单一视觉或视觉-语言模型,忽略了不同模型在不同场景下的互补优势。
- 提出HybridDriveVLA,融合视觉和视觉-语言模型,通过学习评分器选择最佳轨迹,充分利用各自优势。
- 实验表明,HybridDriveVLA显著提升了驾驶性能(PDMS),并提出了DualDriveVLA加速推理。
📝 摘要(中文)
本文研究了在端到端(E2E)驾驶中,使用语言增强的视觉-语言-动作(VLA)模型与纯视觉骨干网络之间的差异。通过在RecogDrive中实例化一个完整的VLM和纯视觉骨干网络,并在相同的扩散Transformer规划器下进行评估,从三个研究问题(RQ)入手。RQ1表明,VLM可以在纯视觉骨干网络的基础上引入额外的特征子空间。RQ2揭示,这种独特的子空间导致在一些长尾场景中出现不同的行为:VLM倾向于更激进,而ViT更保守,各自在约2-3%的测试场景中表现更优。通过一个oracle选择器,选择VLM和ViT分支中更好的轨迹,可以获得93.58 PDMS的上限。RQ3提出HybridDriveVLA,同时运行ViT和VLM分支,并使用一个学习到的评分器来选择它们的终点轨迹,将PDMS提高到92.10。最后,DualDriveVLA实现了一种实用的快-慢策略:默认运行ViT,仅当评分器的置信度低于阈值时才调用VLM;在15%的场景中调用VLM即可达到91.00 PDMS,同时将吞吐量提高3.2倍。代码即将发布。
🔬 方法详解
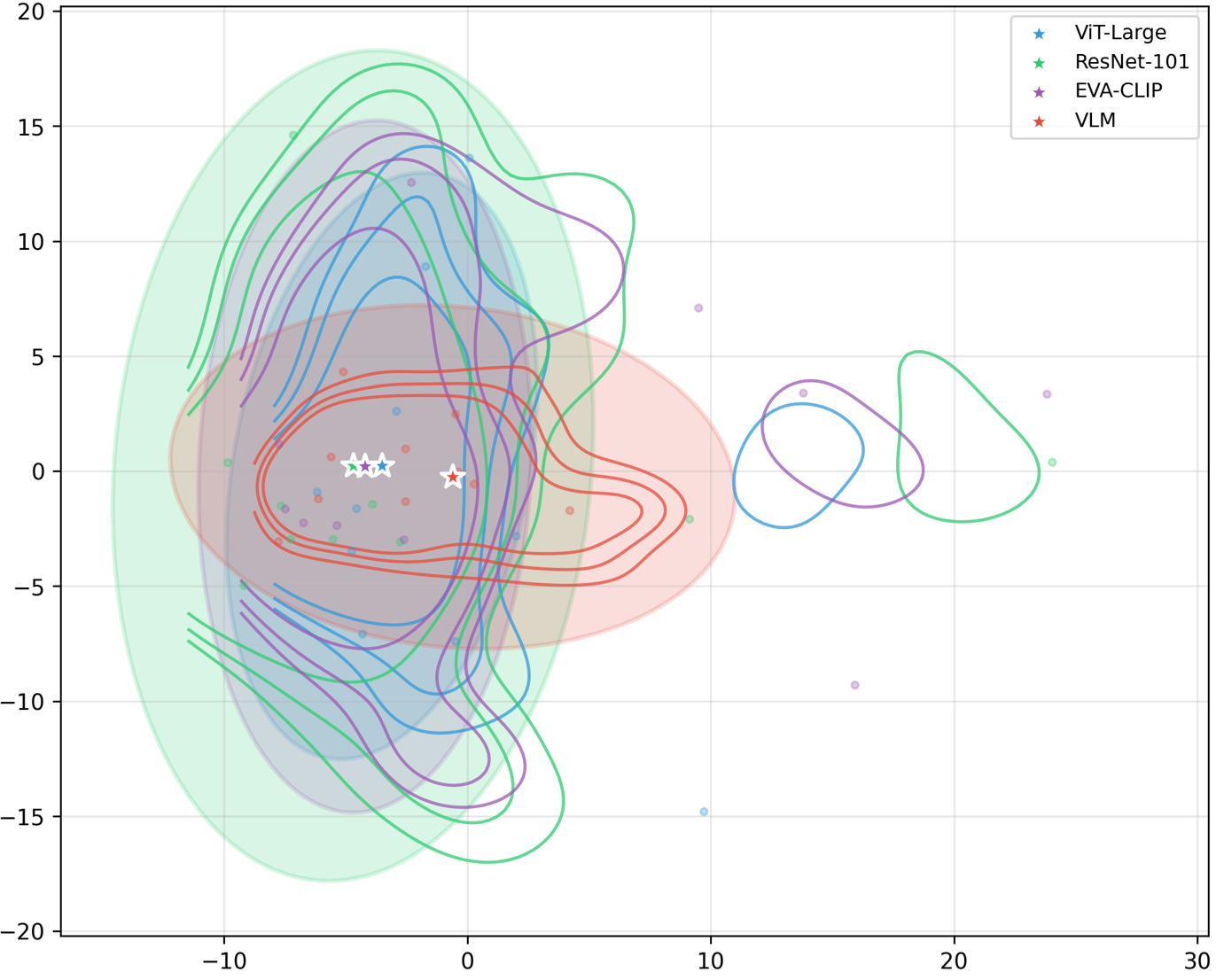
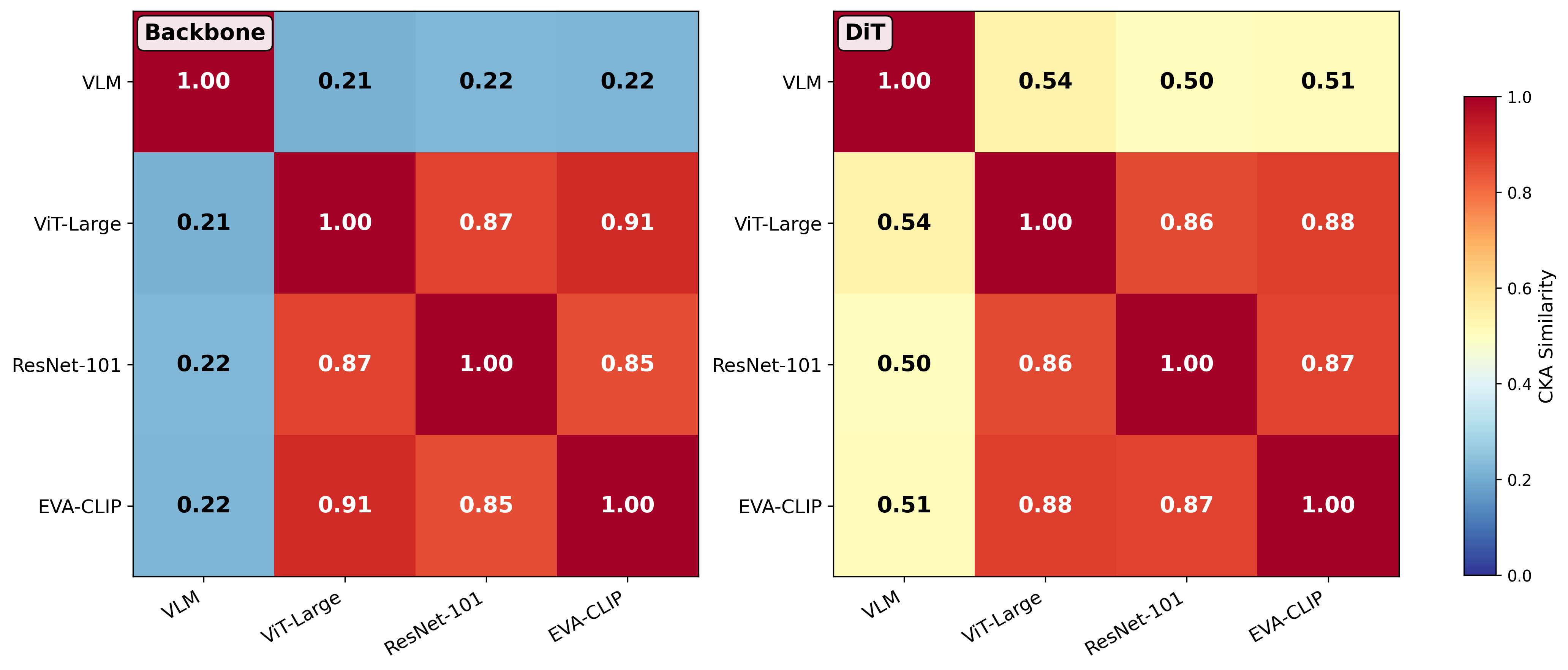
问题定义:现有端到端驾驶方法通常只采用单一类型的骨干网络,例如纯视觉的ViT或视觉-语言模型(VLM)。然而,不同的骨干网络在不同的驾驶场景下可能表现出不同的优势。例如,VLM可能在理解复杂指令或处理长尾场景时更有效,而ViT可能在常见场景中更高效。因此,如何有效地结合不同骨干网络的优势,提升整体驾驶性能,是一个亟待解决的问题。
核心思路:本文的核心思路是利用不同骨干网络之间的表征互补性。具体来说,VLM和ViT在不同的特征子空间中学习驾驶策略,导致它们在不同的场景下表现出不同的行为。通过学习一个评分器来选择VLM和ViT生成的最佳轨迹,可以充分利用它们的互补优势,从而提升整体驾驶性能。
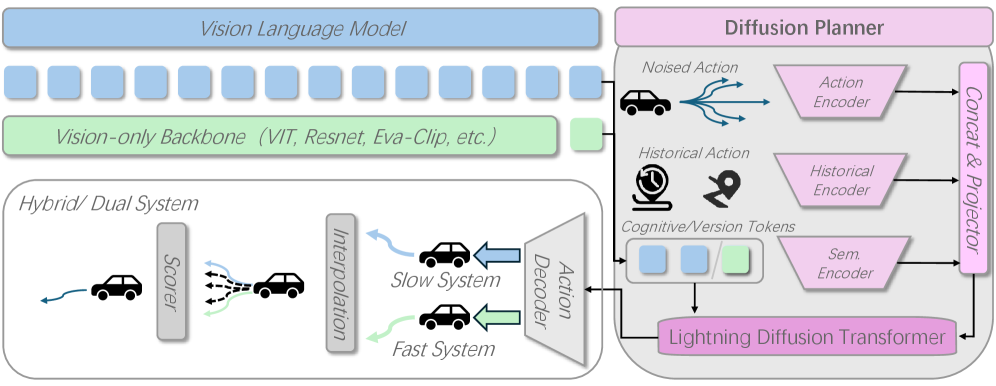
技术框架:HybridDriveVLA包含两个主要分支:ViT分支和VLM分支。两个分支并行运行,分别生成各自的驾驶轨迹。然后,一个学习到的评分器对两个分支生成的轨迹进行评分,并选择得分最高的轨迹作为最终的驾驶决策。DualDriveVLA在此基础上进一步优化,采用快-慢策略:默认情况下运行ViT分支,只有当评分器的置信度低于某个阈值时,才调用VLM分支。
关键创新:本文的关键创新在于提出了HybridDriveVLA,它能够有效地融合VLM和ViT的优势,从而提升端到端驾驶性能。此外,DualDriveVLA通过快-慢策略,在保证性能的同时,显著提高了推理速度。
关键设计:评分器是一个小型神经网络,输入是ViT和VLM分支生成的轨迹特征,输出是每个轨迹的得分。评分器的训练目标是最大化选择正确轨迹的概率。DualDriveVLA中的置信度阈值是一个超参数,需要根据实际情况进行调整。扩散Transformer规划器使用与原文一致的设置,具体参数未知。
🖼️ 关键图片
📊 实验亮点
HybridDriveVLA在RecogDrive数据集上取得了显著的性能提升,PDMS达到92.10,相比于单独使用ViT或VLM,性能有明显提高。DualDriveVLA在仅调用15%的VLM场景下,PDMS达到91.00,同时吞吐量提高了3.2倍,实现了性能和效率的平衡。
🎯 应用场景
该研究成果可应用于自动驾驶、辅助驾驶等领域,尤其是在需要处理复杂场景和长尾情况的应用中。通过融合不同类型的感知模型,可以提高自动驾驶系统的鲁棒性和安全性,并降低对高精度地图的依赖。未来,该方法可以扩展到其他类型的传感器和模型,进一步提升自动驾驶系统的性能。
📄 摘要(原文)
Vision-Language-Action (VLA) driving augments end-to-end (E2E) planning with language-enabled backbones, yet it remains unclear what changes beyond the usual accuracy--cost trade-off. We revisit this question with 3--RQ analysis in RecogDrive by instantiating the system with a full VLM and vision-only backbones, all under an identical diffusion Transformer planner. RQ1: At the backbone level, the VLM can introduce additional subspaces upon the vision-only backbones. RQ2: This unique subspace leads to a different behavioral in some long-tail scenario: the VLM tends to be more aggressive whereas ViT is more conservative, and each decisively wins on about 2--3% of test scenarios; With an oracle that selects, per scenario, the better trajectory between the VLM and ViT branches, we obtain an upper bound of 93.58 PDMS. RQ3: To fully harness this observation, we propose HybridDriveVLA, which runs both ViT and VLM branches and selects between their endpoint trajectories using a learned scorer, improving PDMS to 92.10. Finally, DualDriveVLA implements a practical fast--slow policy: it runs ViT by default and invokes the VLM only when the scorer's confidence falls below a threshold; calling the VLM on 15% of scenarios achieves 91.00 PDMS while improving throughput by 3.2x. Code will be released.