Say, Dream, and Act: Learning Video World Models for Instruction-Driven Robot Manipulation
作者: Songen Gu, Yunuo Cai, Tianyu Wang, Simo Wu, Yanwei Fu
分类: cs.RO
发布日期: 2026-02-11
💡 一句话要点
提出基于视频世界模型的指令驱动机器人操作框架,提升预测精度和操作性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 视频世界模型 指令驱动 对抗蒸馏 视频预测 具身智能 空间推理
📋 核心要点
- 现有机器人操作系统缺乏对环境响应动作的预测能力,导致操作错误和效率低下。
- 该论文提出一种基于视频世界模型的框架,通过预测未来视频帧来指导机器人操作。
- 实验表明,该方法能生成时空一致的视频预测,显著提升机器人在具身一致性、空间指代和任务完成方面的性能。
📝 摘要(中文)
机器人操作需要预测环境如何响应动作,但现有系统缺乏这种预测能力,导致错误和效率低下。视觉-语言模型(VLMs)提供高层指导,但不能显式预测未来状态,而现有的世界模型要么预测短时程,要么产生空间不一致的帧。为了解决这些挑战,我们提出了一个快速和预测性的视频条件动作框架。我们的方法首先选择并调整一个鲁棒的视频生成模型,以确保可靠的未来预测,然后应用对抗蒸馏进行快速、少步视频生成,最后训练一个动作模型,利用生成的视频和真实观察来纠正空间误差。大量实验表明,我们的方法产生时间连贯、空间精确的视频预测,直接支持精确操作,在具身一致性、空间指代能力和任务完成方面,比现有基线有显著提高。代码和模型将会发布。
🔬 方法详解
问题定义:现有机器人操作方法难以准确预测环境对动作的响应,导致操作失败。视觉-语言模型虽然能提供高层指导,但无法预测未来状态。现有的世界模型要么只能预测短时程,要么生成的视频帧在空间上不一致,无法有效指导机器人操作。
核心思路:该论文的核心思路是构建一个能够生成高质量、长时程视频预测的世界模型,并利用该模型来指导机器人动作。通过预测未来状态,机器人可以更好地规划和执行动作,从而提高操作的成功率和效率。
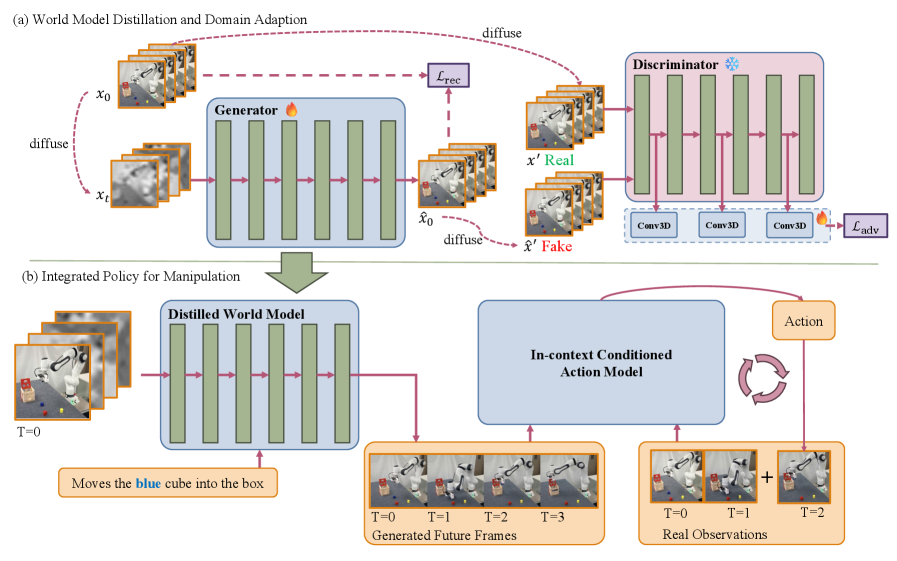
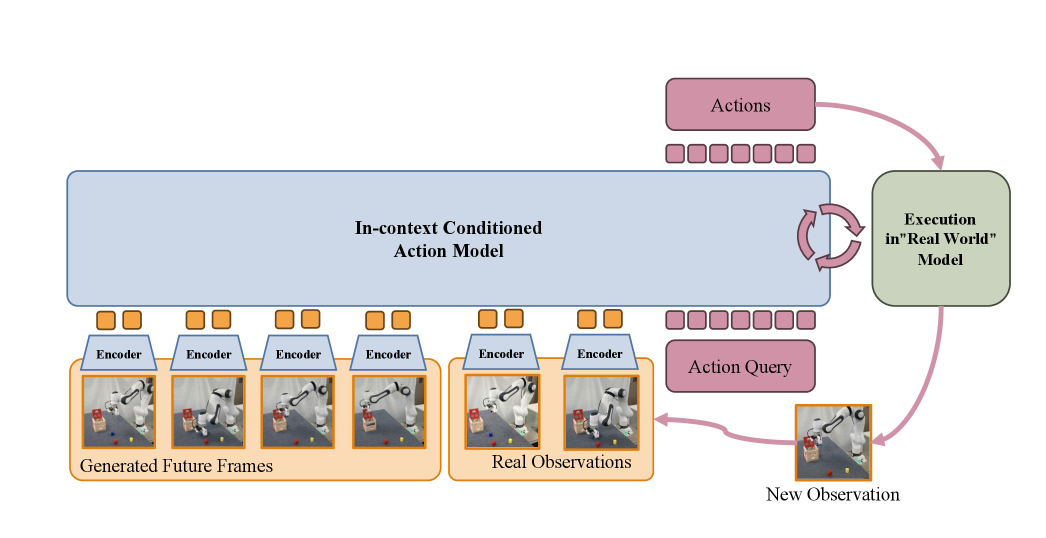
技术框架:该框架包含三个主要阶段:1) 视频生成模型选择与适配:选择一个鲁棒的视频生成模型,并针对特定任务进行调整,以确保生成可靠的未来预测。2) 对抗蒸馏:利用对抗蒸馏技术,加速视频生成过程,实现快速、少步的视频生成。3) 动作模型训练:训练一个动作模型,该模型同时利用生成的视频和真实观察来纠正空间误差,从而提高操作的精度。
关键创新:该论文的关键创新在于将视频生成模型与机器人操作相结合,构建了一个能够进行长时程、空间一致性预测的世界模型。通过对抗蒸馏加速视频生成,并利用生成的视频和真实观察来训练动作模型,从而显著提高了机器人操作的性能。
关键设计:在视频生成模型选择方面,论文可能采用了预训练的生成模型,如基于Transformer或GAN的模型,并针对机器人操作任务进行了微调。对抗蒸馏可能采用了GAN的训练方式,通过生成器生成视频,判别器判断视频的真伪。动作模型可能采用了强化学习或模仿学习的方法,利用生成的视频作为奖励信号或指导信号。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在具身一致性、空间指代能力和任务完成方面,均显著优于现有基线方法。具体性能数据(例如成功率、操作时间等)和提升幅度将在论文中详细展示。该方法生成的视频预测具有时间连贯性和空间精确性,能够直接支持精确操作。
🎯 应用场景
该研究成果可应用于各种需要精确操作的机器人任务,如工业自动化、医疗手术、家庭服务等。通过预测环境变化,机器人可以更好地适应复杂环境,完成更具挑战性的任务。未来,该技术有望推动机器人智能化水平的提升,使其能够更好地服务于人类。
📄 摘要(原文)
Robotic manipulation requires anticipating how the environment evolves in response to actions, yet most existing systems lack this predictive capability, often resulting in errors and inefficiency. While Vision-Language Models (VLMs) provide high-level guidance, they cannot explicitly forecast future states, and existing world models either predict only short horizons or produce spatially inconsistent frames. To address these challenges, we propose a framework for fast and predictive video-conditioned action. Our approach first selects and adapts a robust video generation model to ensure reliable future predictions, then applies adversarial distillation for fast, few-step video generation, and finally trains an action model that leverages both generated videos and real observations to correct spatial errors. Extensive experiments show that our method produces temporally coherent, spatially accurate video predictions that directly support precise manipulation, achieving significant improvements in embodiment consistency, spatial referring ability, and task completion over existing baselines. Codes & Models will be released.