LAP: Language-Action Pre-Training Enables Zero-shot Cross-Embodiment Transfer
作者: Lihan Zha, Asher J. Hancock, Mingtong Zhang, Tenny Yin, Yixuan Huang, Dhruv Shah, Allen Z. Ren, Anirudha Majumdar
分类: cs.RO, cs.AI
发布日期: 2026-02-11
备注: Project website: https://lap-vla.github.io
💡 一句话要点
LAP:语言-动作预训练实现零样本跨具身迁移
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 视觉-语言模型 零样本学习 跨具身迁移 预训练 自然语言处理 动作表示
📋 核心要点
- 现有VLA模型在跨机器人具身泛化能力不足,需要大量针对特定具身的微调。
- LAP通过语言描述低级机器人动作,对齐动作监督与视觉-语言模型的输入输出分布。
- LAP-3B在多个新机器人和操作任务上实现了超过50%的零样本成功率,显著优于现有VLA。
📝 摘要(中文)
机器人领域的一个长期目标是实现通用策略,使其能够在新的机器人具身上进行零样本部署,而无需针对每个具身进行适配。尽管进行了大规模的多具身预训练,现有的视觉-语言-动作模型(VLA)仍然与其训练具身紧密耦合,通常需要昂贵的微调。我们引入了语言-动作预训练(LAP),这是一种简单的方案,直接用自然语言表示低级机器人动作,使动作监督与预训练的视觉-语言模型的输入-输出分布对齐。LAP不需要学习到的分词器,不需要昂贵的标注,也不需要特定于具身的架构设计。基于LAP,我们提出了LAP-3B,据我们所知,这是第一个在没有任何特定于具身的微调的情况下,实现对先前未见过的机器人具身进行实质性零样本迁移的VLA。在多个新的机器人和操作任务中,LAP-3B实现了超过50%的平均零样本成功率,比最强的现有VLA提高了约2倍。我们进一步表明,LAP能够实现高效的适配和良好的扩展性,同时将动作预测和VQA统一在共享的语言-动作格式中,从而通过协同训练产生额外的收益。
🔬 方法详解
问题定义:现有视觉-语言-动作模型(VLA)在经过大规模多具身预训练后,仍然难以泛化到新的、未见过的机器人具身上。它们通常需要针对每个新的机器人具身进行昂贵的微调,这限制了它们在实际应用中的灵活性和可扩展性。核心痛点在于动作表示与视觉-语言模型的输入输出分布不匹配,导致模型难以理解和执行跨具身的通用指令。
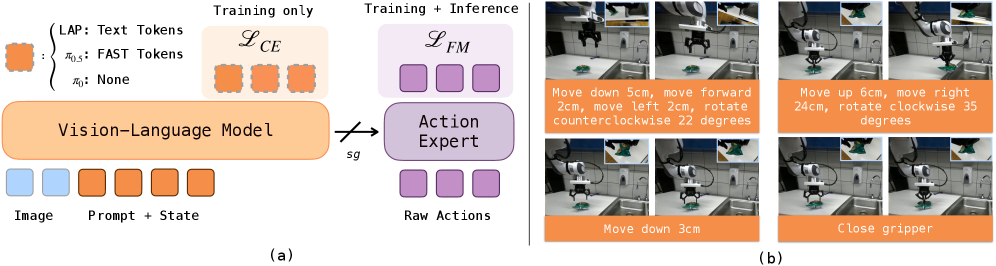
核心思路:LAP的核心思路是将低级机器人动作直接用自然语言表示,从而将动作监督与预训练的视觉-语言模型的输入-输出分布对齐。通过这种方式,模型可以利用预训练的语言知识来理解和生成动作,从而实现更好的跨具身泛化能力。这种设计避免了学习特定于具身的分词器或架构,降低了模型对训练数据的依赖。
技术框架:LAP方法主要包括以下几个步骤:首先,收集包含视觉信息、语言指令和机器人动作的数据集。然后,将机器人动作转换为自然语言描述。接下来,使用预训练的视觉-语言模型(例如,基于Transformer的模型)对数据进行训练,目标是根据视觉输入和语言指令预测相应的语言描述的动作。最后,将训练好的模型部署到新的机器人具身上,进行零样本的动作执行。
关键创新:LAP最重要的技术创新在于使用自然语言来表示低级机器人动作。这与现有方法使用离散动作空间或连续动作向量不同,它允许模型利用预训练的语言知识来理解和生成动作,从而实现更好的跨具身泛化能力。此外,LAP不需要学习特定于具身的分词器或架构,降低了模型的复杂性和训练成本。
关键设计:LAP的关键设计包括:1) 使用简单的自然语言描述来表示机器人动作,例如“move forward”、“turn left”等。2) 使用预训练的视觉-语言模型作为基础架构,例如CLIP或类似的模型。3) 使用交叉熵损失函数来训练模型,目标是根据视觉输入和语言指令预测正确的语言描述的动作。4) 通过数据增强和协同训练来提高模型的鲁棒性和泛化能力。模型大小为3B参数(LAP-3B)。
🖼️ 关键图片


📊 实验亮点
LAP-3B在多个新的机器人和操作任务中实现了超过50%的平均零样本成功率,相比于现有最强的VLA模型,性能提升了约2倍。实验结果表明,LAP能够有效地实现跨具身迁移,并且具有良好的扩展性。此外,LAP还能够将动作预测和VQA统一在共享的语言-动作格式中,通过协同训练进一步提升性能。
🎯 应用场景
LAP具有广泛的应用前景,可用于开发通用的机器人控制系统,使机器人能够在各种环境中执行任务,而无需针对每个环境进行专门的编程。例如,它可以应用于家庭服务机器人、工业自动化机器人、医疗辅助机器人等领域,提高机器人的智能化水平和适应能力。此外,LAP还可以促进人机交互,使人们能够更自然地通过语言指令来控制机器人。
📄 摘要(原文)
A long-standing goal in robotics is a generalist policy that can be deployed zero-shot on new robot embodiments without per-embodiment adaptation. Despite large-scale multi-embodiment pre-training, existing Vision-Language-Action models (VLAs) remain tightly coupled to their training embodiments and typically require costly fine-tuning. We introduce Language-Action Pre-training (LAP), a simple recipe that represents low-level robot actions directly in natural language, aligning action supervision with the pre-trained vision-language model's input-output distribution. LAP requires no learned tokenizer, no costly annotation, and no embodiment-specific architectural design. Based on LAP, we present LAP-3B, which to the best of our knowledge is the first VLA to achieve substantial zero-shot transfer to previously unseen robot embodiments without any embodiment-specific fine-tuning. Across multiple novel robots and manipulation tasks, LAP-3B attains over 50% average zero-shot success, delivering roughly a 2x improvement over the strongest prior VLAs. We further show that LAP enables efficient adaptation and favorable scaling, while unifying action prediction and VQA in a shared language-action format that yields additional gains through co-training.