Co-jump: Cooperative Jumping with Quadrupedal Robots via Multi-Agent Reinforcement Learning
作者: Shihao Dong, Yeke Chen, Zeren Luo, Jiahui Zhang, Bowen Xu, Jinghan Lin, Yimin Han, Ji Ma, Zhiyou Yu, Yudong Zhao, Peng Lu
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-02-11
备注: 14 pages, 7 figures
💡 一句话要点
提出Co-jump框架,通过多智能体强化学习实现四足机器人协同跳跃
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 多智能体强化学习 四足机器人 协同跳跃 MAPPO 课程学习 机器人控制 无通信协作
📋 核心要点
- 单智能体足式运动受限于物理驱动极限,难以完成高难度动作,需要探索多智能体协作。
- 提出Co-jump框架,利用MAPPO和渐进课程学习,实现无显式通信的四足机器人协同跳跃。
- 实验表明,该方法在仿真和真实机器人上均表现出鲁棒性,跳跃高度提升显著。
📝 摘要(中文)
本文提出Co-jump,一种协同跳跃方法,旨在使两个四足机器人同步执行超出其单体能力的跳跃。该方法在去中心化环境中处理高冲击接触动力学,无需显式通信或预定义的运动原语即可实现同步。Co-jump框架利用多智能体近端策略优化(MAPPO),并结合渐进课程策略,有效克服了机械耦合系统中固有的稀疏奖励探索挑战。实验结果表明,该方法在仿真中表现出鲁棒性,并成功迁移到物理硬件,能够执行多方向跳跃到高达1.5米的平台上。其中一个机器人实现了1.1米的足端抬升,比独立四足机器人的0.45米跳跃高度提高了144%,展示了卓越的垂直性能。值得注意的是,这种精确的协调仅通过本体感受反馈实现,为受限环境中无通信的协作运动奠定了基础。
🔬 方法详解
问题定义:现有单智能体四足机器人受限于自身物理驱动能力的限制,难以完成高难度的跳跃动作。在多智能体协作场景下,如何实现多个机器人之间的有效协同,克服个体能力限制,完成更高难度的任务是一个挑战。尤其是在缺乏显式通信的情况下,如何保证机器人之间的同步和协调是一个关键问题。
核心思路:论文的核心思路是利用多智能体强化学习,让两个四足机器人通过自主学习的方式,在没有显式通信的情况下,学会协同跳跃。通过精心设计的奖励函数和课程学习策略,引导机器人探索有效的协同策略,从而实现超越单体能力的跳跃。这种方法避免了人工设计运动原语的复杂性,并具有更好的适应性和鲁棒性。
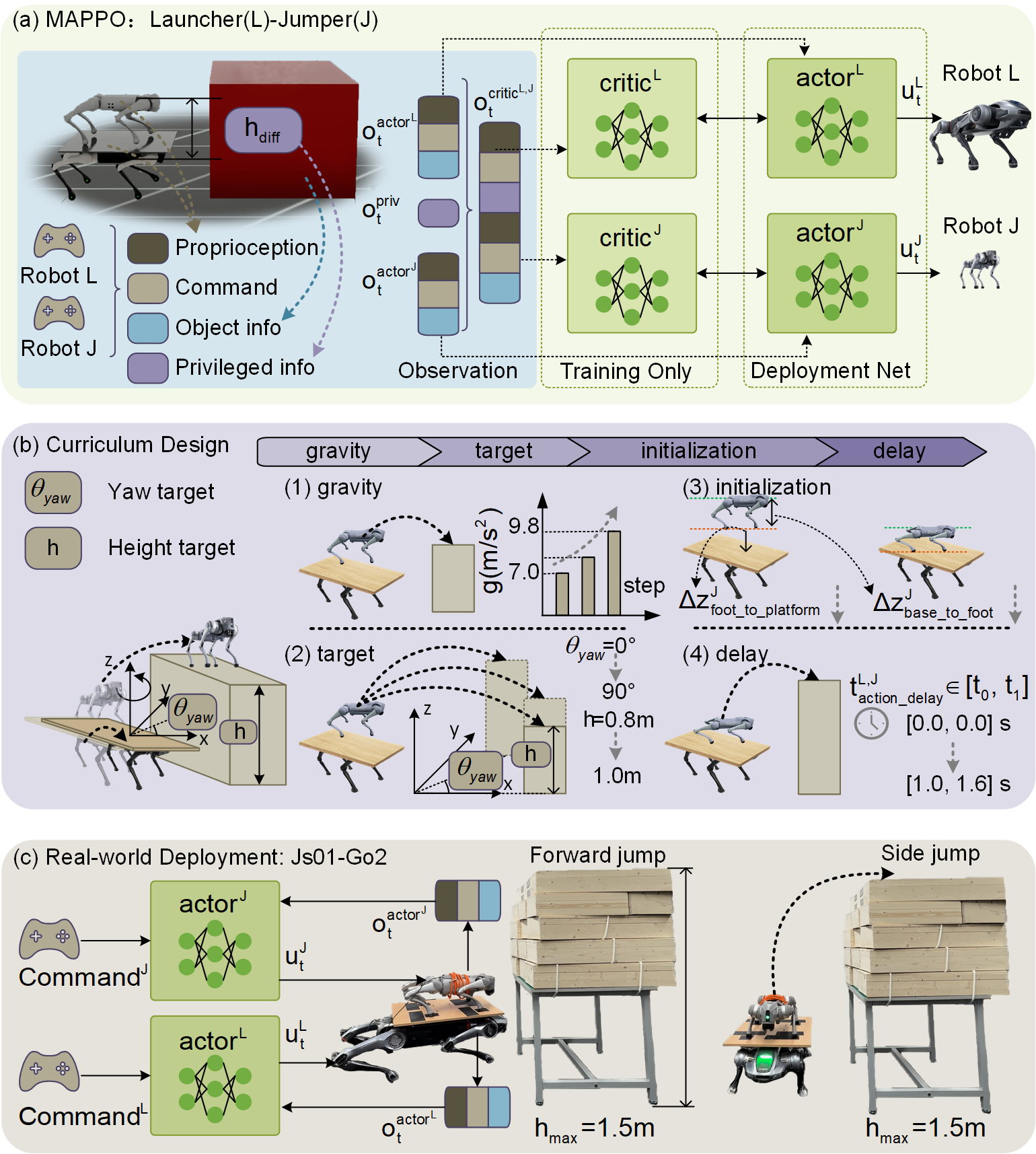
技术框架:Co-jump框架主要包含以下几个模块:1)环境建模:构建包含两个四足机器人的仿真环境,模拟真实的物理交互。2)多智能体强化学习:采用MAPPO算法作为核心学习算法,每个机器人作为一个独立的智能体,通过与环境交互学习策略。3)奖励函数设计:设计稀疏奖励函数,鼓励机器人完成跳跃任务,并惩罚不协调的行为。4)课程学习策略:采用渐进式课程学习策略,从简单的任务开始,逐步增加任务难度,帮助机器人更好地探索和学习。
关键创新:该论文的关键创新在于:1)提出了一种基于多智能体强化学习的四足机器人协同跳跃方法,无需显式通信即可实现高效的协同。2)设计了一种渐进式课程学习策略,有效克服了稀疏奖励带来的探索难题。3)实现了从仿真到真实机器人的成功迁移,验证了该方法的鲁棒性和实用性。
关键设计:在MAPPO算法中,每个机器人使用独立的Actor-Critic网络。Actor网络输出动作策略,Critic网络评估当前状态的价值。奖励函数主要包含跳跃高度奖励、同步奖励和惩罚项。跳跃高度奖励鼓励机器人跳得更高,同步奖励鼓励机器人保持同步,惩罚项惩罚不协调的行为。课程学习策略从简单的原地跳跃开始,逐步增加跳跃高度和距离,最终实现高难度的协同跳跃。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Co-jump框架在仿真和真实机器人上均表现出良好的性能。在真实机器人实验中,一个机器人实现了1.1米的足端抬升,比独立四足机器人的0.45米跳跃高度提高了144%,验证了该方法在提升跳跃高度方面的显著效果。此外,该方法仅通过本体感受反馈实现精确协调,无需显式通信,降低了系统复杂性,提高了鲁棒性。
🎯 应用场景
该研究成果可应用于复杂地形下的机器人搜救、物资运输等领域。通过多机器人协同,可以克服单机器人能力限制,提高任务完成效率和安全性。未来,该技术有望扩展到更多类型的机器人和更复杂的协作任务中,例如多机器人协同搬运、协同装配等,具有广阔的应用前景。
📄 摘要(原文)
While single-agent legged locomotion has witnessed remarkable progress, individual robots remain fundamentally constrained by physical actuation limits. To transcend these boundaries, we introduce Co-jump, a cooperative task where two quadrupedal robots synchronize to execute jumps far beyond their solo capabilities. We tackle the high-impulse contact dynamics of this task under a decentralized setting, achieving synchronization without explicit communication or pre-specified motion primitives. Our framework leverages Multi-Agent Proximal Policy Optimization (MAPPO) enhanced by a progressive curriculum strategy, which effectively overcomes the sparse-reward exploration challenges inherent in mechanically coupled systems. We demonstrate robust performance in simulation and successful transfer to physical hardware, executing multi-directional jumps onto platforms up to 1.5 m in height. Specifically, one of the robots achieves a foot-end elevation of 1.1 m, which represents a 144% improvement over the 0.45 m jump height of a standalone quadrupedal robot, demonstrating superior vertical performance. Notably, this precise coordination is achieved solely through proprioceptive feedback, establishing a foundation for communication-free collaborative locomotion in constrained environments.