LocoVLM: Grounding Vision and Language for Adapting Versatile Legged Locomotion Policies
作者: I Made Aswin Nahrendra, Seunghyun Lee, Dongkyu Lee, Hyun Myung
分类: cs.RO
发布日期: 2026-02-11
备注: Project page: https://locovlm.github.io
💡 一句话要点
LocoVLM:通过视觉语言 grounding 实现通用足式机器人运动策略自适应
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 足式机器人 运动控制 视觉语言模型 大型语言模型 技能自适应
📋 核心要点
- 现有的足式机器人运动学习主要依赖环境的几何表示,限制了机器人对人类指令等高级语义的响应能力。
- 本文提出LocoVLM,利用预训练的视觉语言模型提取环境语义,并将其与指令相结合,实现足式机器人的运动技能自适应。
- 实验表明,该方法能够实现高达87%的指令跟随准确率,无需在线查询云端基础模型,实现了实时的运动自适应。
📝 摘要(中文)
本文提出了一种新颖的方法,将基础模型的高级常识推理融入到足式机器人运动自适应过程中。该方法利用预训练的大型语言模型合成一个针对足式机器人的、以指令为基础的技能数据库。同时,利用预训练的视觉语言模型提取高级环境语义,并将其 grounding 到技能数据库中,从而为机器人提供实时的技能建议。为了实现通用的技能控制,训练了一个风格条件策略,该策略能够生成多样且鲁棒的运动技能,并高度忠实于指定的风格。据我们所知,这是第一个展示使用环境语义和指令进行高级推理,从而实时自适应足式机器人运动的工作,在指令跟随方面的准确率高达 87%,且无需在线查询云端基础模型。
🔬 方法详解
问题定义:现有足式机器人运动学习方法主要依赖于环境的几何信息,缺乏对高级语义信息的理解和利用,导致机器人难以响应人类指令,限制了其在复杂环境中的应用。现有方法无法有效利用视觉信息和语言指令来指导运动控制。
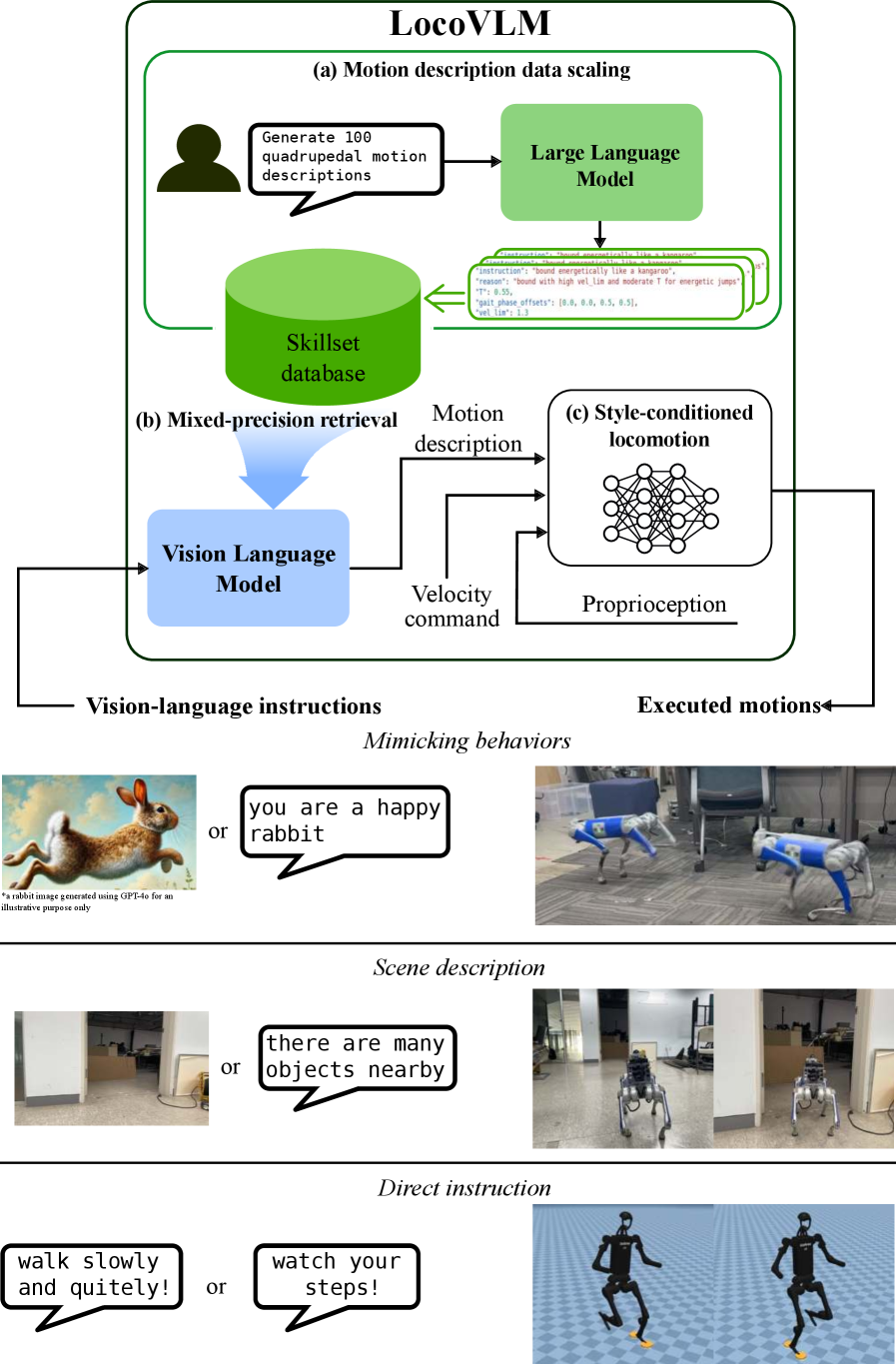
核心思路:本文的核心思路是将预训练的视觉语言模型(VLM)和大型语言模型(LLM)的知识迁移到足式机器人运动控制中。通过VLM提取环境中的高级语义信息,并利用LLM生成指令相关的技能数据库,从而实现基于视觉和语言信息的运动技能自适应。
技术框架:LocoVLM框架主要包含三个模块:1) 基于LLM的指令驱动的技能数据库生成模块;2) 基于VLM的环境语义提取与grounding模块;3) 风格条件运动策略学习模块。首先,利用LLM生成与各种指令相关的运动技能描述,构建技能数据库。然后,利用VLM提取环境中的视觉语义信息,并将其与技能数据库中的技能描述进行匹配,为机器人提供实时的技能建议。最后,训练一个风格条件策略,根据VLM提供的技能建议,生成相应的运动控制指令。
关键创新:该方法的主要创新在于将预训练的VLM和LLM的知识迁移到足式机器人运动控制中,实现了基于视觉和语言信息的运动技能自适应。与现有方法相比,该方法能够更好地理解环境语义和人类指令,从而生成更自然、更符合人类意图的运动行为。此外,该方法无需在线查询云端基础模型,降低了计算成本和延迟。
关键设计:在技能数据库生成方面,利用LLM生成与各种指令相关的运动技能描述,包括运动类型、速度、方向等。在环境语义提取方面,利用预训练的VLM提取环境中的物体、场景等信息,并将其转化为语义向量。在风格条件策略学习方面,采用Actor-Critic框架,将VLM提供的技能建议作为风格条件输入到Actor网络中,指导运动控制指令的生成。损失函数包括运动模仿损失、风格一致性损失等,以保证生成的运动技能既能模仿技能数据库中的运动轨迹,又能与VLM提供的技能建议保持一致。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LocoVLM能够实现高达87%的指令跟随准确率,显著优于传统的基于几何信息的运动控制方法。此外,该方法能够在复杂环境中生成鲁棒的运动技能,并能够根据环境语义和人类指令进行实时自适应。与需要在线查询云端基础模型的方法相比,LocoVLM具有更低的计算成本和延迟。
🎯 应用场景
该研究成果可应用于搜救、巡检、物流等领域。例如,在搜救场景中,机器人可以根据视觉信息识别障碍物和受困人员,并根据救援人员的指令,自主规划运动路径,执行救援任务。在物流场景中,机器人可以根据货物信息和配送指令,自主完成货物的搬运和配送。
📄 摘要(原文)
Recent advances in legged locomotion learning are still dominated by the utilization of geometric representations of the environment, limiting the robot's capability to respond to higher-level semantics such as human instructions. To address this limitation, we propose a novel approach that integrates high-level commonsense reasoning from foundation models into the process of legged locomotion adaptation. Specifically, our method utilizes a pre-trained large language model to synthesize an instruction-grounded skill database tailored for legged robots. A pre-trained vision-language model is employed to extract high-level environmental semantics and ground them within the skill database, enabling real-time skill advisories for the robot. To facilitate versatile skill control, we train a style-conditioned policy capable of generating diverse and robust locomotion skills with high fidelity to specified styles. To the best of our knowledge, this is the first work to demonstrate real-time adaptation of legged locomotion using high-level reasoning from environmental semantics and instructions with instruction-following accuracy of up to 87% without the need for online query to on-the-cloud foundation models.