Learning Agile Quadrotor Flight in the Real World
作者: Yunfan Ren, Zhiyuan Zhu, Jiaxu Xing, Davide Scaramuzza
分类: cs.RO
发布日期: 2026-02-10
💡 一句话要点
提出自适应框架,解决四旋翼在真实世界中敏捷飞行的难题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 四旋翼 敏捷飞行 在线学习 自适应控制 强化学习
📋 核心要点
- 现有基于学习的四旋翼控制依赖大量仿真,Sim2Real迁移困难,且难以应对真实世界的不确定性。
- 提出自适应框架,通过自适应时间缩放(ATS)探索物理极限,并使用在线残差学习增强标称模型。
- 实验表明,该方法能使四旋翼在100秒内将速度从1.9m/s提升至7.3m/s,实现敏捷飞行。
📝 摘要(中文)
基于学习的控制器在四旋翼敏捷飞行中表现出色,但通常依赖于大量的仿真训练,需要精确的系统辨识才能实现有效的Sim2Real迁移。即使有精确的建模,固定的策略仍然容易受到外部空气动力学扰动到内部硬件退化等分布外场景的影响。为了确保在这些不断变化的不确定性下的安全性,此类控制器被迫以保守的安全裕度运行,从而限制了它们在受控环境之外的灵活性。虽然在线自适应提供了一种潜在的补救措施,但由于数据稀缺和安全风险,安全地探索物理极限仍然是一个关键瓶颈。为了弥合这一差距,我们提出了一个自适应框架,该框架无需精确的系统辨识或离线Sim2Real迁移。我们引入了自适应时间缩放(ATS)来主动探索平台物理极限,并采用在线残差学习来增强一个简单的标称模型。基于学习到的混合模型,我们进一步提出了真实世界锚定的短时反向传播(RASH-BPTT),以实现高效和鲁棒的飞行中策略更新。大量的实验表明,我们的四旋翼可靠地执行接近执行器饱和极限的敏捷机动。该系统在约100秒的飞行时间内,将保守的基线策略的峰值速度从1.9米/秒提高到7.3米/秒。这些发现强调,真实世界的自适应不仅可以补偿建模误差,而且是一种在激进飞行状态下持续提高性能的实用机制。
🔬 方法详解
问题定义:现有基于学习的四旋翼控制方法,在真实环境中难以保证敏捷性和鲁棒性。主要痛点在于:一是依赖于精确的系统辨识,难以实现有效的Sim2Real迁移;二是固定策略难以适应真实世界中未知的扰动和硬件变化;三是在线自适应面临数据稀缺和安全风险,难以安全地探索物理极限。
核心思路:论文的核心思路是通过在线自适应的方式,使四旋翼能够自主学习并适应真实环境中的不确定性,从而在无需精确系统辨识的情况下,实现敏捷且鲁棒的飞行控制。核心在于主动探索物理极限,并利用在线学习不断优化控制策略。
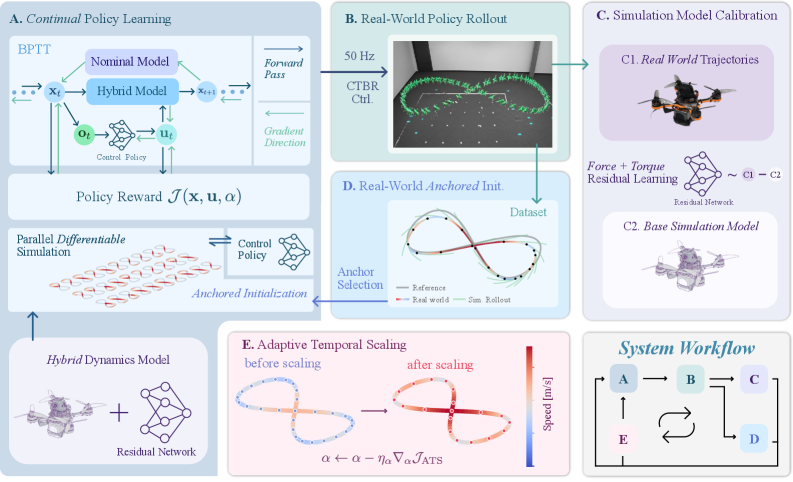
技术框架:整体框架包含以下几个主要模块:1) 自适应时间缩放(ATS):用于主动探索四旋翼的物理极限,通过调整时间尺度来安全地尝试更激进的控制动作。2) 在线残差学习:利用在线收集的数据,学习一个残差模型来补偿标称模型的误差,从而提高模型的精度。3) 真实世界锚定的短时反向传播(RASH-BPTT):基于学习到的混合模型,使用短时反向传播算法进行策略优化,并利用真实世界的数据作为锚点,提高策略的鲁棒性。
关键创新:论文的关键创新在于将自适应时间缩放(ATS)与在线残差学习相结合,并提出了真实世界锚定的短时反向传播(RASH-BPTT)算法。ATS能够安全地探索物理极限,在线残差学习能够不断提高模型精度,RASH-BPTT能够实现高效且鲁棒的策略优化。与现有方法相比,该方法无需精确的系统辨识,能够更好地适应真实环境中的不确定性。
关键设计:ATS通过调整控制指令的时间尺度来探索物理极限,具体实现方式未知。在线残差学习使用神经网络来学习残差模型,损失函数的设计未知。RASH-BPTT使用短时反向传播算法进行策略优化,具体实现细节未知。论文中没有明确说明网络结构和参数设置。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够使四旋翼在真实环境中实现敏捷飞行,在约100秒的飞行时间内,将保守的基线策略的峰值速度从1.9米/秒提高到7.3米/秒。这表明该方法能够有效地探索物理极限,并利用在线学习不断优化控制策略,从而显著提高四旋翼的飞行性能。
🎯 应用场景
该研究成果可应用于无人机自主导航、物流配送、搜救等领域。通过在线自适应学习,无人机能够更好地适应复杂多变的真实环境,提高飞行效率和安全性。未来,该技术有望推动无人机在更多领域的应用,例如农业植保、电力巡检、桥梁检测等。
📄 摘要(原文)
Learning-based controllers have achieved impressive performance in agile quadrotor flight but typically rely on massive training in simulation, necessitating accurate system identification for effective Sim2Real transfer. However, even with precise modeling, fixed policies remain susceptible to out-of-distribution scenarios, ranging from external aerodynamic disturbances to internal hardware degradation. To ensure safety under these evolving uncertainties, such controllers are forced to operate with conservative safety margins, inherently constraining their agility outside of controlled settings. While online adaptation offers a potential remedy, safely exploring physical limits remains a critical bottleneck due to data scarcity and safety risks. To bridge this gap, we propose a self-adaptive framework that eliminates the need for precise system identification or offline Sim2Real transfer. We introduce Adaptive Temporal Scaling (ATS) to actively explore platform physical limits, and employ online residual learning to augment a simple nominal model. {Based on the learned hybrid model, we further propose Real-world Anchored Short-horizon Backpropagation Through Time (RASH-BPTT) to achieve efficient and robust in-flight policy updates. Extensive experiments demonstrate that our quadrotor reliably executes agile maneuvers near actuator saturation limits. The system evolves a conservative base policy with a peak speed of 1.9 m/s to 7.3 m/s within approximately 100 seconds of flight time. These findings underscore that real-world adaptation serves not merely to compensate for modeling errors, but as a practical mechanism for sustained performance improvement in aggressive flight regimes.