ST4VLA: Spatially Guided Training for Vision-Language-Action Models
作者: Jinhui Ye, Fangjing Wang, Ning Gao, Junqiu Yu, Yangkun Zhu, Bin Wang, Jinyu Zhang, Weiyang Jin, Yanwei Fu, Feng Zheng, Yilun Chen, Jiangmiao Pang
分类: cs.RO
发布日期: 2026-02-10
备注: Spatially Training for VLA, Accepted by ICLR 2026
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ST4VLA:利用空间引导训练提升视觉-语言-动作模型在具身任务中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 具身智能 空间引导训练 机器人学习 空间先验
📋 核心要点
- 现有视觉-语言模型在具身任务中,难以将高级指令转化为低级运动动作,导致性能下降。
- ST4VLA通过空间引导训练,将动作学习与视觉-语言模型中的空间先验对齐,提升模型性能。
- 实验表明,ST4VLA在多个机器人任务中显著优于现有方法,并具有更强的泛化性和鲁棒性。
📝 摘要(中文)
大型视觉-语言模型(VLM)在多模态理解方面表现出色,但当扩展到具身任务时,需要将指令转换为低级运动动作,其性能会下降。本文提出了ST4VLA,一个双系统视觉-语言-动作框架,它利用空间引导训练来对齐动作学习与VLM中的空间先验。ST4VLA包括两个阶段:(i)空间 grounding 预训练,通过来自网络规模和机器人特定数据的可扩展的点、框和轨迹预测,使VLM具备可转移的先验知识;(ii)空间引导的动作后训练,通过空间提示鼓励模型产生更丰富的空间先验来指导动作生成。这种设计在策略学习期间保留了空间 grounding,并促进了空间和动作目标之间的一致优化。实验结果表明,ST4VLA相对于原始VLA取得了显著的改进,在Google Robot上的性能从66.1提高到84.6,在WidowX Robot上的性能从54.7提高到73.2,在SimplerEnv上建立了新的最先进结果。它还展示了对未见过的对象和释义指令的更强的泛化能力,以及在真实世界环境中对长时程扰动的鲁棒性。这些结果表明,可扩展的空间引导训练是鲁棒、可泛化的机器人学习的一个有希望的方向。
🔬 方法详解
问题定义:现有视觉-语言模型(VLM)在处理具身任务时,面临着将高级语言指令转化为低级机器人动作的难题。直接将VLM应用于机器人控制通常效果不佳,因为VLM缺乏对机器人环境和动作空间的理解,难以进行有效的动作规划和执行。现有方法往往忽略了VLM中蕴含的空间信息,或者无法有效地将空间信息与动作学习相结合。
核心思路:ST4VLA的核心思路是利用空间引导训练,将动作学习与VLM中的空间先验知识对齐。通过显式地学习空间关系,模型可以更好地理解环境,并生成更合理的动作序列。该方法的核心在于利用空间信息作为桥梁,连接视觉-语言理解和动作生成,从而提升模型在具身任务中的性能。
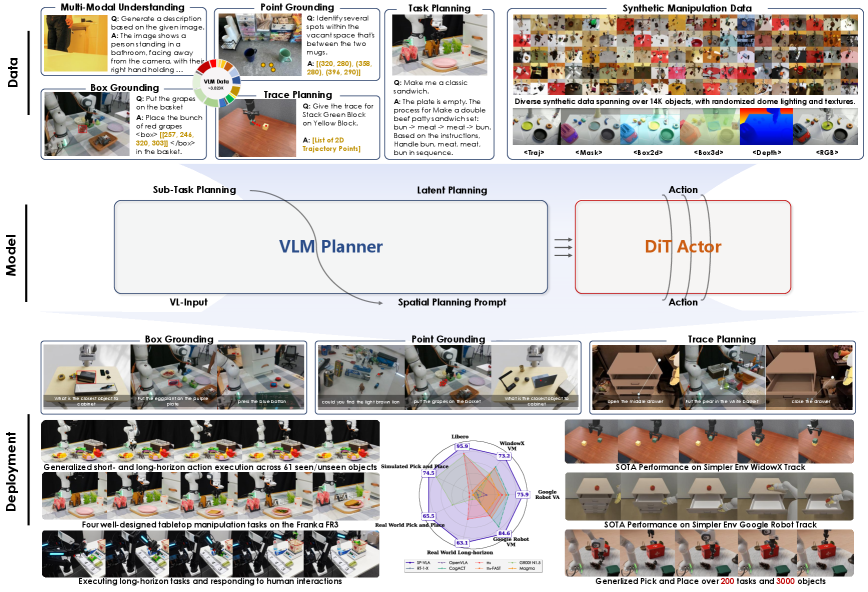
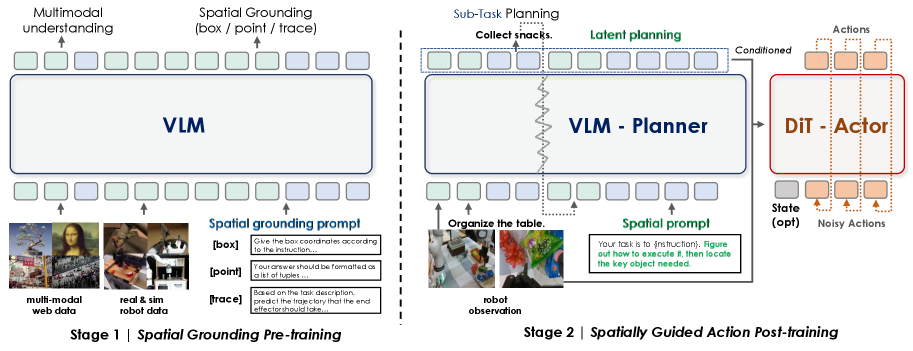
技术框架:ST4VLA是一个双系统框架,包含两个主要阶段:1) 空间 grounding 预训练:利用大规模数据集(包括网络数据和机器人特定数据)进行预训练,使VLM具备预测点、框和轨迹的能力,从而获得可转移的空间先验知识。2) 空间引导的动作后训练:在预训练的基础上,利用空间提示,鼓励模型生成更丰富的空间先验,并将其用于指导动作生成。这两个阶段相互配合,共同提升模型在具身任务中的性能。
关键创新:ST4VLA的关键创新在于提出了空间引导训练策略,将空间信息显式地融入到动作学习过程中。与现有方法相比,ST4VLA能够更有效地利用VLM中蕴含的空间先验知识,从而提升模型在具身任务中的性能。此外,ST4VLA的双系统框架能够实现空间 grounding 和动作学习的解耦,从而更好地进行模型优化和泛化。
关键设计:在空间 grounding 预训练阶段,使用了对比学习损失来学习空间表示。在空间引导的动作后训练阶段,使用了空间提示来引导模型生成动作。具体的网络结构和损失函数细节在论文中有详细描述。此外,论文还探索了不同的空间提示方式,并分析了它们对模型性能的影响。
🖼️ 关键图片
📊 实验亮点
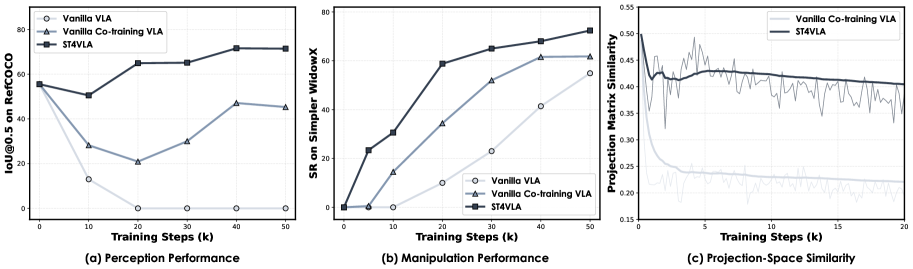
ST4VLA在SimplerEnv的Google Robot和WidowX Robot任务上取得了显著的性能提升,分别从66.1提高到84.6,以及从54.7提高到73.2,建立了新的state-of-the-art结果。此外,ST4VLA还展示了对未见过的对象和释义指令的更强的泛化能力,以及在真实世界环境中对长时程扰动的鲁棒性,验证了该方法的有效性和优越性。
🎯 应用场景
ST4VLA具有广泛的应用前景,可应用于各种机器人任务,如家庭服务机器人、工业机器人、自动驾驶等。该研究有助于提升机器人的智能化水平,使其能够更好地理解人类指令,并在复杂环境中执行任务。未来,该技术有望应用于更广泛的领域,如虚拟现实、增强现实等,为用户提供更智能、更便捷的交互体验。
📄 摘要(原文)
Large vision-language models (VLMs) excel at multimodal understanding but fall short when extended to embodied tasks, where instructions must be transformed into low-level motor actions. We introduce ST4VLA, a dual-system Vision-Language-Action framework that leverages Spatial Guided Training to align action learning with spatial priors in VLMs. ST4VLA includes two stages: (i) spatial grounding pre-training, which equips the VLM with transferable priors via scalable point, box, and trajectory prediction from both web-scale and robot-specific data, and (ii) spatially guided action post-training, which encourages the model to produce richer spatial priors to guide action generation via spatial prompting. This design preserves spatial grounding during policy learning and promotes consistent optimization across spatial and action objectives. Empirically, ST4VLA achieves substantial improvements over vanilla VLA, with performance increasing from 66.1 -> 84.6 on Google Robot and from 54.7 -> 73.2 on WidowX Robot, establishing new state-of-the-art results on SimplerEnv. It also demonstrates stronger generalization to unseen objects and paraphrased instructions, as well as robustness to long-horizon perturbations in real-world settings. These results highlight scalable spatially guided training as a promising direction for robust, generalizable robot learning. Source code, data and models are released at https://internrobotics.github.io/internvla-m1.github.io/