EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration
作者: Modi Shi, Shijia Peng, Jin Chen, Haoran Jiang, Yinghui Li, Di Huang, Ping Luo, Hongyang Li, Li Chen
分类: cs.RO
发布日期: 2026-02-10
备注: Project page: https://opendrivelab.com/EgoHumanoid
💡 一句话要点
EgoHumanoid:利用无机器人的人类自我中心演示,实现野外环境的人形机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人形机器人 移动操作 自我中心视觉 模仿学习 领域自适应
📋 核心要点
- 人形机器人移动操作任务数据需求大,现有机器人遥操作成本高,难以扩展到多样化的真实环境。
- EgoHumanoid框架利用大量人类自我中心演示数据,结合少量机器人数据进行联合训练,学习视觉-语言-动作策略。
- 实验表明,该方法在真实环境中显著优于仅使用机器人数据的基线方法,性能提升达51%,尤其是在未见过的环境中。
📝 摘要(中文)
本文提出EgoHumanoid,这是一个首创的框架,它结合了丰富的自我中心人类演示数据和少量机器人数据,共同训练视觉-语言-动作策略,使人形机器人能够在各种真实环境中执行移动操作任务。为了弥合人类和机器人之间的具身差距,包括物理形态和视角的差异,我们引入了一个从硬件设计到数据处理的系统对齐流程。开发了一个用于可扩展人类数据收集的便携式系统,并建立了实用的收集协议以提高可迁移性。我们的人类到人形机器人对齐流程的核心在于两个关键组件:视角对齐,减少了由相机高度和视角变化引起的视觉领域差异;动作对齐,将人类运动映射到统一的、运动学上可行的人形机器人控制动作空间。大量的真实世界实验表明,结合无机器人的自我中心数据,显著优于仅使用机器人数据的基线方法,性能提升达51%,尤其是在未见过的环境中。我们的分析进一步揭示了哪些行为能够有效转移,以及扩展人类数据的潜力。
🔬 方法详解
问题定义:现有的人形机器人移动操作任务依赖于大量的机器人数据,而机器人遥操作成本高昂,难以扩展到真实世界的多样化环境。人类演示数据虽然丰富且易于获取,但存在与机器人形态和视角上的差异,直接应用效果不佳。
核心思路:利用人类的自我中心视角演示数据,结合少量机器人数据,通过对齐人类和机器人的视角和动作空间,弥合具身差距,从而训练出能够在真实环境中执行移动操作任务的人形机器人策略。这样既能利用人类数据的丰富性和多样性,又能克服人类和机器人之间的差异。
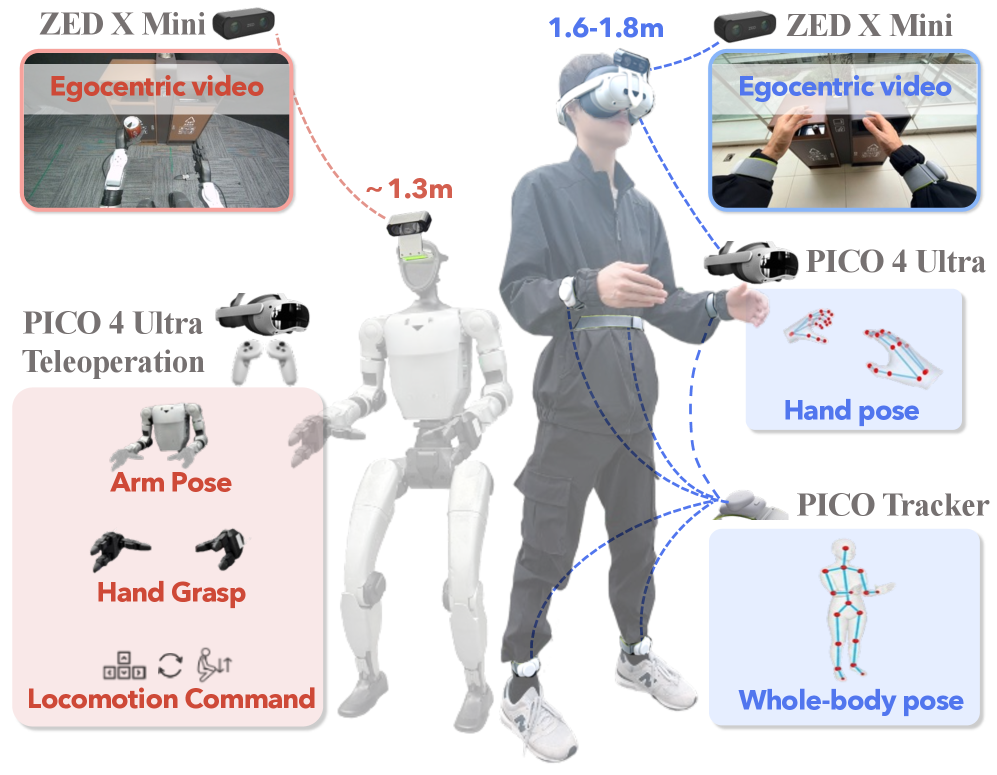
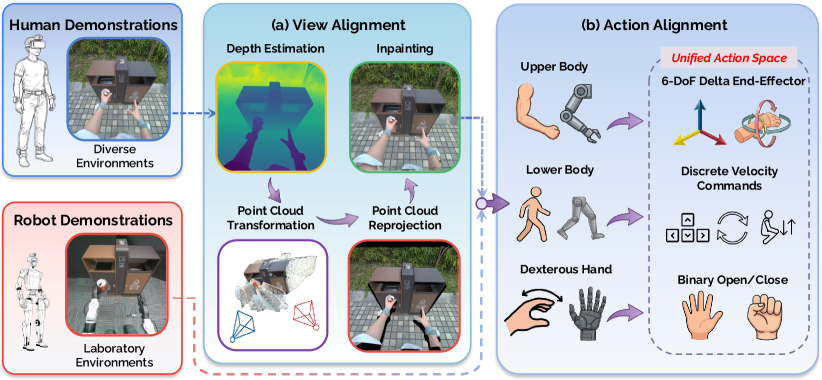
技术框架:EgoHumanoid框架包含数据收集、数据处理和策略训练三个主要阶段。首先,通过便携式系统收集大量人类自我中心演示数据。然后,通过视角对齐和动作对齐两个关键模块,将人类数据转换为机器人可用的形式。最后,结合少量机器人数据,共同训练视觉-语言-动作策略。
关键创新:该论文的关键创新在于提出了一套完整的人类到人形机器人的对齐流程,包括硬件设计、数据收集协议、视角对齐和动作对齐等。通过这些对齐方法,有效地弥合了人类和机器人之间的具身差距,使得人类数据能够被用于训练人形机器人。
关键设计:视角对齐通过调整相机高度和视角来减少视觉领域差异。动作对齐将人类运动映射到统一的、运动学上可行的人形机器人控制动作空间。具体实现细节未知,论文可能使用了例如逆运动学、重定向等技术。损失函数和网络结构等细节在摘要中未提及,具体实现未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,结合无机器人的自我中心数据,显著优于仅使用机器人数据的基线方法,性能提升达51%,尤其是在未见过的环境中。这表明了人类数据在人形机器人移动操作任务中的巨大潜力,以及该论文提出的对齐方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要人形机器人进行移动操作的场景,例如家庭服务、物流配送、灾难救援等。通过利用人类演示数据,可以降低机器人训练成本,提高机器人在复杂环境中的适应性和泛化能力。未来,该技术有望推动人形机器人在现实世界中的广泛应用。
📄 摘要(原文)
Human demonstrations offer rich environmental diversity and scale naturally, making them an appealing alternative to robot teleoperation. While this paradigm has advanced robot-arm manipulation, its potential for the more challenging, data-hungry problem of humanoid loco-manipulation remains largely unexplored. We present EgoHumanoid, the first framework to co-train a vision-language-action policy using abundant egocentric human demonstrations together with a limited amount of robot data, enabling humanoids to perform loco-manipulation across diverse real-world environments. To bridge the embodiment gap between humans and robots, including discrepancies in physical morphology and viewpoint, we introduce a systematic alignment pipeline spanning from hardware design to data processing. A portable system for scalable human data collection is developed, and we establish practical collection protocols to improve transferability. At the core of our human-to-humanoid alignment pipeline lies two key components. The view alignment reduces visual domain discrepancies caused by camera height and perspective variation. The action alignment maps human motions into a unified, kinematically feasible action space for humanoid control. Extensive real-world experiments demonstrate that incorporating robot-free egocentric data significantly outperforms robot-only baselines by 51\%, particularly in unseen environments. Our analysis further reveals which behaviors transfer effectively and the potential for scaling human data.