Robo3R: Enhancing Robotic Manipulation with Accurate Feed-Forward 3D Reconstruction
作者: Sizhe Yang, Linning Xu, Hao Li, Juncheng Mu, Jia Zeng, Dahua Lin, Jiangmiao Pang
分类: cs.RO
发布日期: 2026-02-10
💡 一句话要点
Robo3R:通过精确的前馈3D重建增强机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 3D重建 深度学习 点云 相机姿态估计 sim-to-real 模仿学习
📋 核心要点
- 现有深度传感器易受噪声和材料影响,重建模型缺乏操作所需的精度和尺度一致性。
- Robo3R通过前馈方式,从RGB图像和机器人状态预测精确的、度量尺度的场景几何信息,并进行全局优化。
- Robo3R在多个下游任务中表现优异,包括模仿学习、sim-to-real迁移等,验证了其有效性。
📝 摘要(中文)
3D空间感知是通用机器人操作的基础,但获得可靠、高质量的3D几何信息仍然具有挑战性。深度传感器存在噪声和材料敏感性问题,而现有的重建模型缺乏物理交互所需的精度和尺度一致性。我们提出了Robo3R,一个前馈的、可用于操作的3D重建模型,它可以从RGB图像和机器人状态实时预测精确的、度量尺度的场景几何信息。Robo3R联合推断尺度不变的局部几何信息和相对相机姿态,并通过学习到的全局相似变换将它们统一到规范的机器人坐标系中。为了满足操作的精度要求,Robo3R采用了一个masked point head来生成清晰、细粒度的点云,并采用基于关键点的Perspective-n-Point (PnP)公式来细化相机外参和全局对齐。Robo3R在Robo3R-4M(一个包含四百万个高保真标注帧的大规模合成数据集)上进行训练,始终优于最先进的重建方法和深度传感器。在包括模仿学习、sim-to-real迁移、抓取合成和无碰撞运动规划等下游任务中,我们观察到性能的持续提升,表明这种替代的3D感知模块在机器人操作中的潜力。
🔬 方法详解
问题定义:现有的3D重建方法在机器人操作场景中面临精度和尺度一致性的挑战。深度传感器受环境因素影响,而传统重建模型难以满足机器人操作对精确3D几何信息的需求。因此,需要一种能够从RGB图像和机器人状态中实时、精确地重建场景几何信息的模型。
核心思路:Robo3R的核心思路是利用前馈网络直接从RGB图像和机器人状态预测场景的3D几何信息,并采用联合优化策略来提高重建精度和尺度一致性。通过学习全局相似变换,将局部几何信息统一到规范的机器人坐标系中,从而实现操作所需的精确感知。
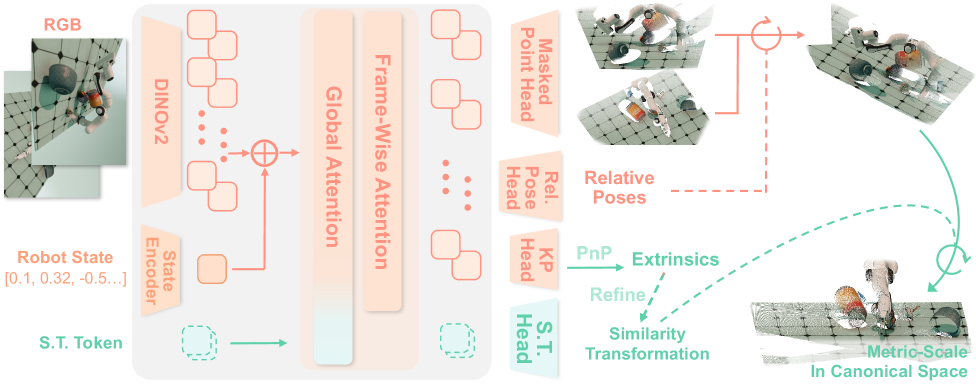
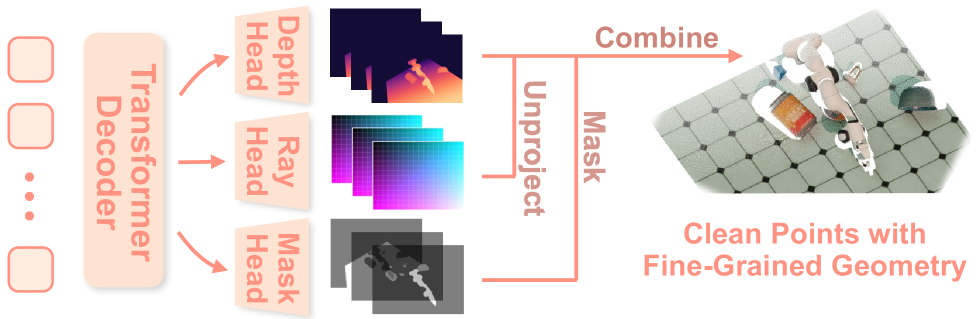
技术框架:Robo3R的整体框架包括以下几个主要模块:1) 特征提取模块,用于从RGB图像中提取视觉特征;2) 局部几何推断模块,用于预测尺度不变的局部几何信息;3) 相机姿态估计模块,用于估计相机相对于机器人坐标系的姿态;4) 全局对齐模块,用于学习全局相似变换,将局部几何信息统一到机器人坐标系中;5) 点云生成模块,用于生成最终的3D点云表示。
关键创新:Robo3R的关键创新在于:1) 提出了一种前馈的3D重建模型,能够实时预测精确的场景几何信息;2) 采用masked point head生成清晰、细粒度的点云;3) 利用基于关键点的PnP公式细化相机外参和全局对齐,从而提高重建精度和尺度一致性。与现有方法相比,Robo3R能够更好地满足机器人操作对3D感知的需求。
关键设计:Robo3R的关键设计包括:1) 使用Masked Point Head,通过mask机制过滤掉噪声点,生成更清晰的点云;2) 采用基于关键点的PnP算法,利用图像中的关键点信息优化相机姿态,提高全局对齐精度;3) 设计了专门的损失函数,用于约束局部几何信息、相机姿态和全局相似变换,从而实现联合优化。
🖼️ 关键图片

📊 实验亮点
Robo3R在多个下游任务中取得了显著的性能提升。例如,在模仿学习任务中,Robo3R的性能优于现有方法和深度传感器。在sim-to-real迁移任务中,Robo3R能够更好地适应真实环境的变化,实现更稳定的机器人操作。实验结果表明,Robo3R是一种有效的3D感知模块,能够显著提升机器人操作的性能。
🎯 应用场景
Robo3R在机器人操作领域具有广泛的应用前景,可用于提升机器人在模仿学习、sim-to-real迁移、抓取合成和无碰撞运动规划等任务中的性能。该技术可以应用于工业自动化、家庭服务机器人、医疗机器人等领域,实现更智能、更高效的机器人操作。
📄 摘要(原文)
3D spatial perception is fundamental to generalizable robotic manipulation, yet obtaining reliable, high-quality 3D geometry remains challenging. Depth sensors suffer from noise and material sensitivity, while existing reconstruction models lack the precision and metric consistency required for physical interaction. We introduce Robo3R, a feed-forward, manipulation-ready 3D reconstruction model that predicts accurate, metric-scale scene geometry directly from RGB images and robot states in real time. Robo3R jointly infers scale-invariant local geometry and relative camera poses, which are unified into the scene representation in the canonical robot frame via a learned global similarity transformation. To meet the precision demands of manipulation, Robo3R employs a masked point head for sharp, fine-grained point clouds, and a keypoint-based Perspective-n-Point (PnP) formulation to refine camera extrinsics and global alignment. Trained on Robo3R-4M, a curated large-scale synthetic dataset with four million high-fidelity annotated frames, Robo3R consistently outperforms state-of-the-art reconstruction methods and depth sensors. Across downstream tasks including imitation learning, sim-to-real transfer, grasp synthesis, and collision-free motion planning, we observe consistent gains in performance, suggesting the promise of this alternative 3D sensing module for robotic manipulation.