VLA-JEPA: Enhancing Vision-Language-Action Model with Latent World Model
作者: Jingwen Sun, Wenyao Zhang, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, Zhibo Chen
分类: cs.RO, cs.CV
发布日期: 2026-02-10
💡 一句话要点
VLA-JEPA:利用潜在世界模型增强视觉-语言-动作模型,提升泛化性和鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 预训练 潜在世界模型 机器人操作 泛化能力
📋 核心要点
- 现有VLA预训练方法易受像素级干扰,导致策略学习关注与动作无关的视觉变化,泛化性受限。
- VLA-JEPA通过无泄露状态预测,利用未来帧的潜在表示作为监督信号,引导模型学习动作相关的状态转移。
- 实验表明,VLA-JEPA在多个模拟和真实机器人操作任务中,显著提升了策略的泛化性和鲁棒性。
📝 摘要(中文)
本文提出了一种名为VLA-JEPA的JEPA风格预训练框架,旨在解决视觉-语言-动作(VLA)策略在互联网规模视频上的预训练问题。现有的潜在动作目标容易学习到错误的关联,过度依赖像素变化而非动作相关的状态转移,从而容易受到外观偏差、无关运动和信息泄露的影响。VLA-JEPA通过“无泄露状态预测”来规避这些问题:目标编码器从未来帧生成潜在表示,而学生网络仅观察当前帧。未来信息仅作为监督目标,而非输入。通过在潜在空间而非像素空间中进行预测,VLA-JEPA学习到的动态抽象对相机运动和不相关的背景变化具有鲁棒性。该方法提供了一个简单的两阶段流程——JEPA预训练后进行动作头微调——避免了现有潜在动作流程的多阶段复杂性。在LIBERO、LIBERO-Plus、SimplerEnv和真实世界操作任务上的实验表明,VLA-JEPA在泛化性和鲁棒性方面均优于现有方法。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在互联网规模视频上进行预训练时,面临着一个关键问题:它们容易学习到与动作无关的像素级变化,例如光照变化、背景干扰等,而不是学习到真正与动作相关的状态转移。这导致模型在新的环境中泛化能力较差,容易受到外观偏差、无关运动和信息泄露的影响。现有方法通常需要复杂的多阶段训练流程来缓解这些问题,但效果有限。
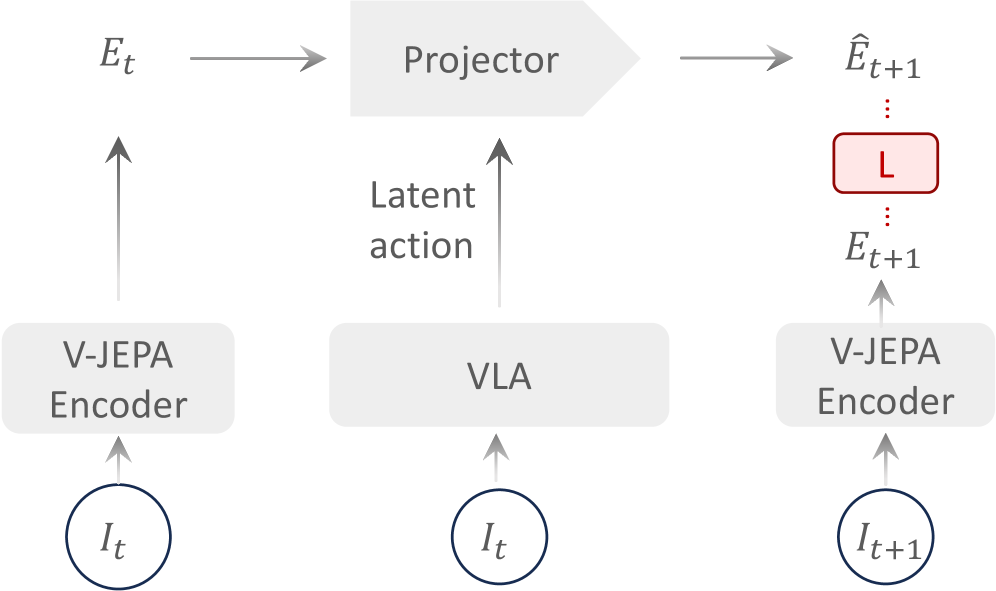
核心思路:VLA-JEPA的核心思路是“无泄露状态预测”。它通过让模型预测未来状态的潜在表示,而不是直接预测像素,来避免模型过度依赖像素级信息。关键在于,模型只能观察当前帧,而未来帧的信息仅作为监督信号,防止信息泄露。这样,模型就被迫学习更加抽象和鲁棒的动态表示,从而提高泛化能力。
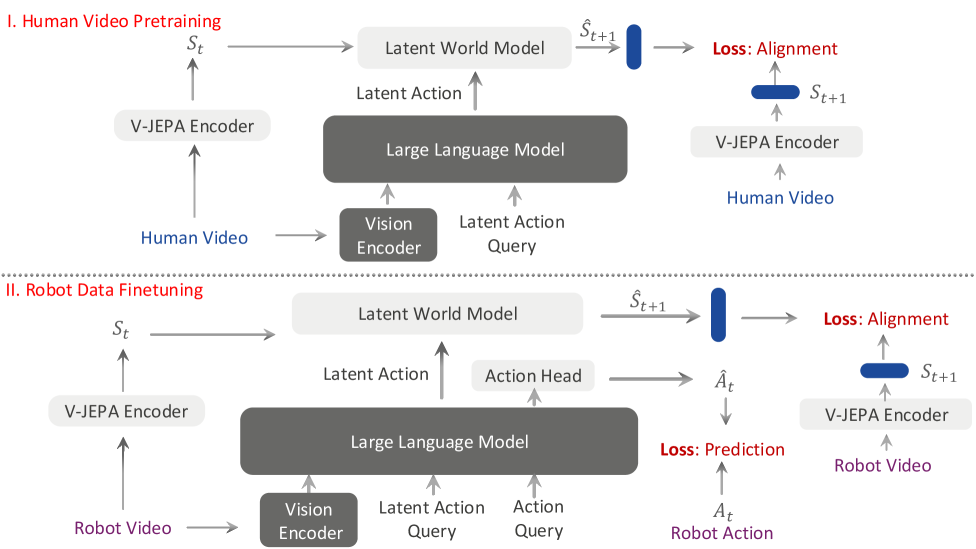
技术框架:VLA-JEPA采用一个两阶段的训练流程。第一阶段是JEPA预训练,该阶段使用对比学习的目标,训练一个编码器来预测未来状态的潜在表示。具体来说,模型包含一个目标编码器和一个学生编码器。目标编码器接收未来帧作为输入,生成潜在表示作为目标。学生编码器接收当前帧作为输入,并预测目标编码器的输出。第二阶段是动作头微调,在该阶段,将预训练的编码器与一个动作头连接,并在特定任务上进行微调。
关键创新:VLA-JEPA最重要的创新点在于其“无泄露状态预测”的设计。与现有方法不同,VLA-JEPA避免了直接预测像素,而是预测未来状态的潜在表示。同时,它严格限制了模型对未来信息的访问,只允许其作为监督信号,从而防止信息泄露。这种设计使得模型能够学习到更加抽象和鲁棒的动态表示,从而提高泛化能力。
关键设计:VLA-JEPA的关键设计包括:1) 使用Transformer网络作为编码器,以捕捉长程依赖关系;2) 使用对比学习损失函数,鼓励学生编码器预测与目标编码器相似的潜在表示;3) 采用随机数据增强技术,增加模型的鲁棒性;4) 使用AdamW优化器进行训练,并采用学习率衰减策略。
🖼️ 关键图片

📊 实验亮点
VLA-JEPA在LIBERO、LIBERO-Plus、SimplerEnv和真实世界操作任务上进行了评估,结果表明其性能优于现有方法。例如,在LIBERO-Plus数据集上,VLA-JEPA的成功率比基线方法提高了10%以上。此外,VLA-JEPA在真实世界操作任务中也表现出良好的鲁棒性,能够成功完成复杂的操作任务。
🎯 应用场景
VLA-JEPA具有广泛的应用前景,可应用于机器人操作、自动驾驶、游戏AI等领域。通过预训练,模型可以学习到通用的视觉-语言-动作知识,从而在新的任务和环境中快速适应。该研究有助于推动通用人工智能的发展,使机器人能够更好地理解和执行人类指令,并在复杂环境中自主完成任务。
📄 摘要(原文)
Pretraining Vision-Language-Action (VLA) policies on internet-scale video is appealing, yet current latent-action objectives often learn the wrong thing: they remain anchored to pixel variation rather than action-relevant state transitions, making them vulnerable to appearance bias, nuisance motion, and information leakage. We introduce VLA-JEPA, a JEPA-style pretraining framework that sidesteps these pitfalls by design. The key idea is \emph{leakage-free state prediction}: a target encoder produces latent representations from future frames, while the student pathway sees only the current observation -- future information is used solely as supervision targets, never as input. By predicting in latent space rather than pixel space, VLA-JEPA learns dynamics abstractions that are robust to camera motion and irrelevant background changes. This yields a simple two-stage recipe -- JEPA pretraining followed by action-head fine-tuning -- without the multi-stage complexity of prior latent-action pipelines. Experiments on LIBERO, LIBERO-Plus, SimplerEnv and real-world manipulation tasks show that VLA-JEPA achieves consistent gains in generalization and robustness over existing methods.