UniVTAC: A Unified Simulation Platform for Visuo-Tactile Manipulation Data Generation, Learning, and Benchmarking
作者: Baijun Chen, Weijie Wan, Tianxing Chen, Xianda Guo, Congsheng Xu, Yuanyang Qi, Haojie Zhang, Longyan Wu, Tianling Xu, Zixuan Li, Yizhe Wu, Rui Li, Xiaokang Yang, Ping Luo, Wei Sui, Yao Mu
分类: cs.RO
发布日期: 2026-02-10
备注: Website: https://univtac.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
UniVTAC:用于视觉-触觉操作数据生成、学习和评估的统一仿真平台
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-触觉融合 机器人操作 仿真平台 数据合成 触觉感知 深度学习 表征学习
📋 核心要点
- 视觉语言动作策略在机器人操作领域取得了快速进展,但对于富含接触的操作,仅依靠视觉难以保证鲁棒性,视觉-触觉感知至关重要。
- UniVTAC平台旨在通过仿真合成大规模、可靠的触觉数据,并提供统一的评估基准,从而克服真实世界触觉数据获取的成本和挑战。
- 实验表明,UniVTAC编码器能有效提升视觉-触觉操作任务的成功率,在仿真和真实机器人实验中分别提升了17.1%和25%。
📝 摘要(中文)
本文提出了UniVTAC,一个基于仿真的视觉-触觉数据合成平台,支持三种常用的视觉-触觉传感器,并能够以可扩展和可控的方式生成信息丰富的接触交互数据。基于此平台,我们引入了UniVTAC编码器,该编码器通过大规模仿真合成数据和精心设计的监督信号进行训练,为下游操作任务提供以触觉为中心的视觉-触觉表征。此外,我们还提出了UniVTAC基准,它包含八个具有代表性的视觉-触觉操作任务,用于评估触觉驱动的策略。实验结果表明,集成UniVTAC编码器在UniVTAC基准上平均成功率提高了17.1%,而真实世界的机器人实验进一步证明了任务成功率提高了25%。
🔬 方法详解
问题定义:现有机器人操作任务,尤其是在需要精细接触交互的任务中,单纯依赖视觉信息存在局限性。真实世界中获取大规模、高质量的触觉数据成本高昂且具有挑战性。此外,缺乏统一的评估平台阻碍了视觉-触觉策略的学习和系统分析。
核心思路:UniVTAC的核心思路是构建一个基于仿真的视觉-触觉数据合成平台,通过可控的参数设置和多样化的场景设计,生成大规模、信息丰富的触觉数据。利用这些数据训练视觉-触觉编码器,从而提升机器人操作策略的性能。
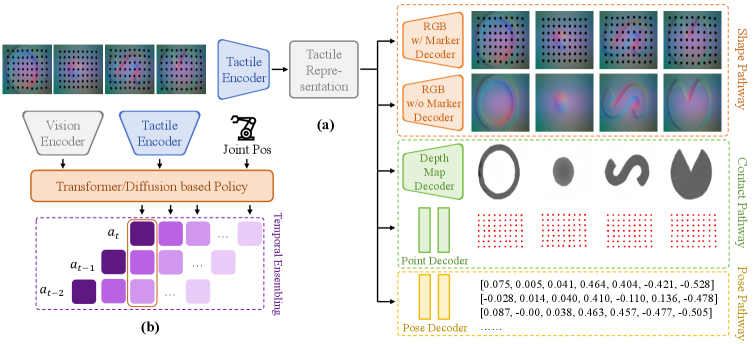
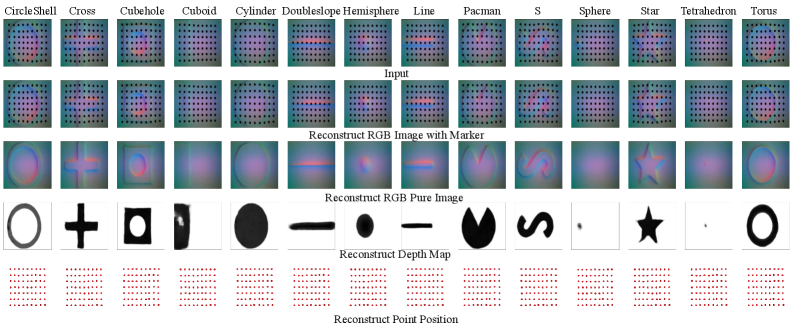
技术框架:UniVTAC平台包含三个主要组成部分:1) 视觉-触觉数据生成模块,支持多种常用传感器,并能控制接触交互过程;2) UniVTAC编码器,利用合成数据进行预训练,提取触觉中心化的视觉-触觉表征;3) UniVTAC基准,包含八个具有代表性的视觉-触觉操作任务,用于评估策略性能。整体流程为:在仿真环境中生成数据 -> 训练UniVTAC编码器 -> 将编码器集成到下游操作策略中 -> 在UniVTAC基准上评估性能。
关键创新:UniVTAC的关键创新在于构建了一个统一的仿真平台,能够以可控的方式生成大规模的视觉-触觉数据,并提供了一个统一的评估基准。此外,UniVTAC编码器通过在合成数据上进行预训练,能够有效提取触觉相关的特征,从而提升下游任务的性能。与现有方法相比,UniVTAC更注重触觉信息的利用,并提供了一个完整的解决方案,包括数据生成、模型训练和性能评估。
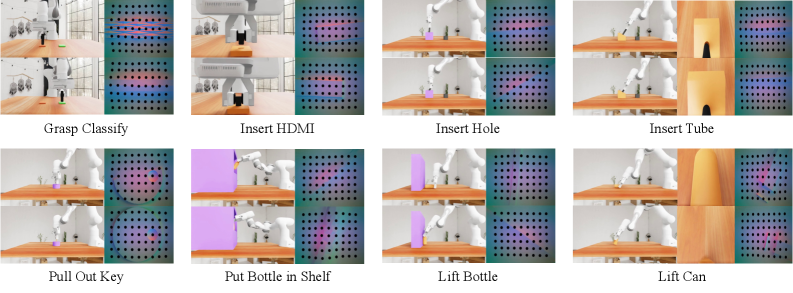
关键设计:UniVTAC平台支持三种常用的视觉-触觉传感器(具体传感器类型未知)。数据生成过程中,通过控制物体属性、机器人运动轨迹等参数,生成多样化的接触交互数据。UniVTAC编码器的具体网络结构未知,但其训练目标是提取触觉中心化的视觉-触觉表征。UniVTAC基准包含八个具有代表性的视觉-触觉操作任务(具体任务内容未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,集成UniVTAC编码器后,在UniVTAC基准测试中,平均成功率提高了17.1%。更重要的是,在真实世界的机器人实验中,任务成功率也提高了25%。这些结果表明,UniVTAC平台和编码器能够有效提升视觉-触觉操作策略的性能,并具有良好的泛化能力。
🎯 应用场景
UniVTAC平台和编码器可广泛应用于机器人操作领域,尤其是在需要精细接触交互的任务中,如装配、抓取、操作工具等。该研究成果有助于降低触觉数据获取的成本,加速触觉驱动的机器人学习研究,并推动机器人技术在工业自动化、医疗康复等领域的应用。
📄 摘要(原文)
Robotic manipulation has seen rapid progress with vision-language-action (VLA) policies. However, visuo-tactile perception is critical for contact-rich manipulation, as tasks such as insertion are difficult to complete robustly using vision alone. At the same time, acquiring large-scale and reliable tactile data in the physical world remains costly and challenging, and the lack of a unified evaluation platform further limits policy learning and systematic analysis. To address these challenges, we propose UniVTAC, a simulation-based visuo-tactile data synthesis platform that supports three commonly used visuo-tactile sensors and enables scalable and controllable generation of informative contact interactions. Based on this platform, we introduce the UniVTAC Encoder, a visuo-tactile encoder trained on large-scale simulation-synthesized data with designed supervisory signals, providing tactile-centric visuo-tactile representations for downstream manipulation tasks. In addition, we present the UniVTAC Benchmark, which consists of eight representative visuo-tactile manipulation tasks for evaluating tactile-driven policies. Experimental results show that integrating the UniVTAC Encoder improves average success rates by 17.1% on the UniVTAC Benchmark, while real-world robotic experiments further demonstrate a 25% improvement in task success. Our webpage is available at https://univtac.github.io/.