RoboSubtaskNet: Temporal Sub-task Segmentation for Human-to-Robot Skill Transfer in Real-World Environments
作者: Dharmendra Sharma, Archit Sharma, John Reberio, Vaibhav Kesharwani, Peeyush Thakur, Narendra Kumar Dhar, Laxmidhar Behera
分类: cs.RO, cs.AI
发布日期: 2026-02-10
💡 一句话要点
提出RoboSubtaskNet,用于真实环境中人机协作技能迁移的子任务分割
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 人机协作 子任务分割 时序建模 机器人控制 深度学习
📋 核心要点
- 现有方法难以在长视频中精确定位和分类机器人可执行的细粒度子任务,这阻碍了安全有效的人机协作。
- RoboSubtaskNet通过注意力增强的I3D特征提取和改进的MS-TCN架构,有效捕捉短时程转换,并利用复合损失函数优化分割结果。
- 实验表明,RoboSubtaskNet在多个数据集上优于现有方法,并在真实机器人平台上验证了其感知到执行的完整流程。
📝 摘要(中文)
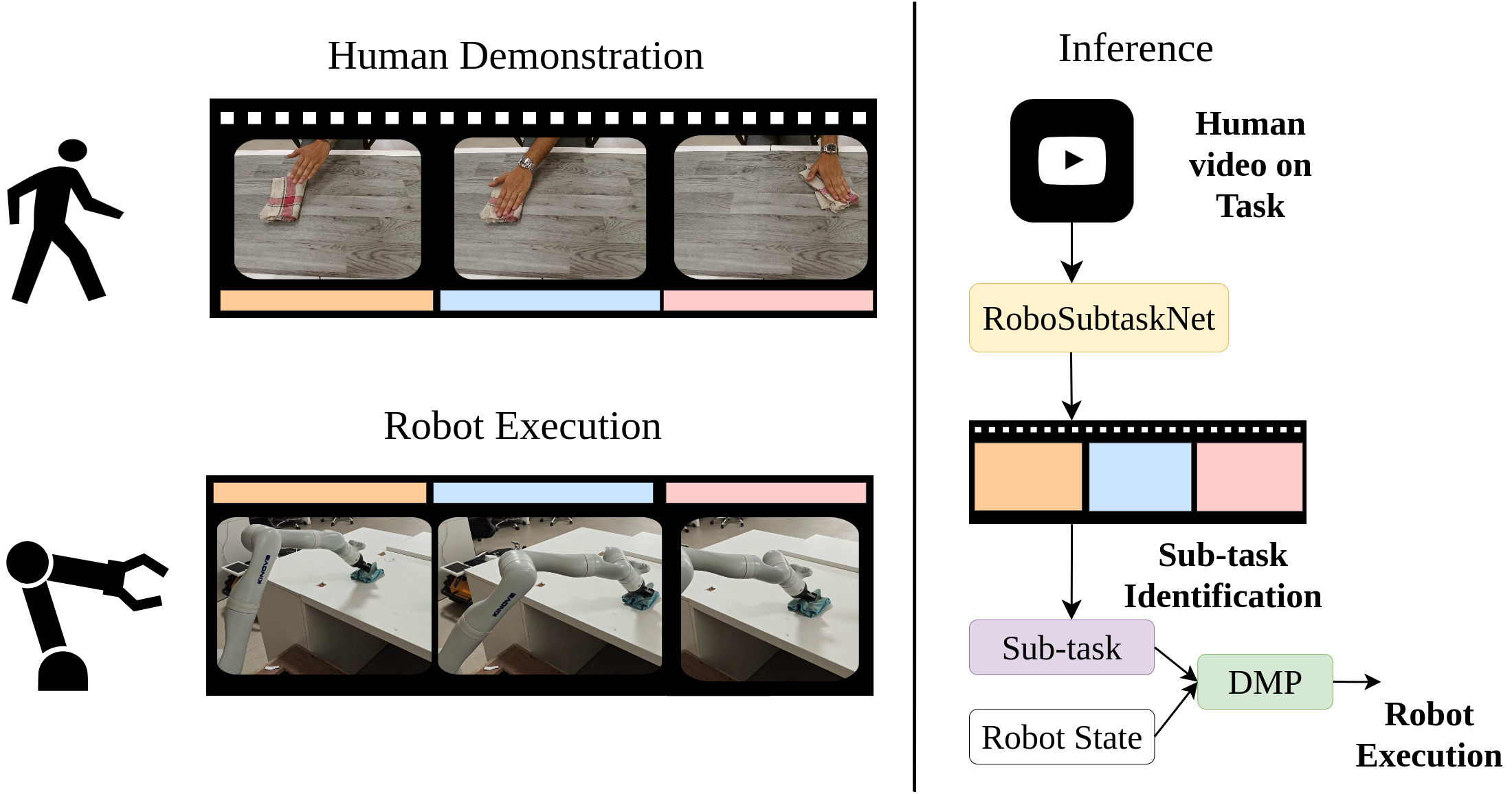
本文提出RoboSubtaskNet,一个多阶段的人机子任务分割框架,旨在解决长视频中细粒度子任务的定位与分类问题,这对于安全的人机协作至关重要。该框架结合了注意力增强的I3D特征(RGB和光流)与改进的MS-TCN,后者采用斐波那契扩张策略以更好地捕捉短时程转换,如reach-pick-place。网络使用复合目标函数进行训练,包括交叉熵和时间正则化项(截断MSE和转换感知项),以减少过度分割并鼓励有效的子任务进展。为了缩小视觉基准和控制之间的差距,本文引入了RoboSubtask数据集,该数据集包含医疗和工业演示,并在子任务级别进行标注,专为确定性映射到机械臂原语而设计。实验表明,RoboSubtaskNet在GTEA和RoboSubtask基准上优于MS-TCN和MS-TCN++,同时在长时程Breakfast基准上保持竞争力。此外,还在7自由度Kinova Gen3机械臂上验证了完整的感知到执行的流程,在物理试验中实现了可靠的端到端行为(总体任务成功率约为91.25%)。
🔬 方法详解
问题定义:论文旨在解决人机协作场景中,如何从长视频中准确分割和识别机器人可执行的子任务。现有方法在处理长视频、捕捉短时程动作转换以及保证分割结果的合理性方面存在不足,导致无法直接应用于机器人控制。
核心思路:论文的核心思路是结合注意力机制增强的I3D特征提取能力和改进的MS-TCN时序建模能力,同时引入时间正则化项来约束分割结果,从而实现更准确、更稳定的子任务分割。通过构建专门的RoboSubtask数据集,弥合了视觉基准和机器人控制之间的差距。
技术框架:RoboSubtaskNet框架主要包含三个阶段:1) 特征提取阶段,使用注意力机制增强的I3D网络提取RGB和光流特征;2) 时序建模阶段,使用改进的MS-TCN网络进行子任务分割,该网络采用斐波那契扩张卷积以捕捉不同时间尺度的信息;3) 优化阶段,使用复合损失函数对网络进行训练,该损失函数包含交叉熵损失和时间正则化项。
关键创新:论文的关键创新在于以下几点:1) 提出了注意力增强的I3D特征提取方法,提高了特征的区分性;2) 改进了MS-TCN网络,采用斐波那契扩张卷积,更好地捕捉短时程动作转换;3) 引入了时间正则化项,约束分割结果,减少过度分割;4) 构建了RoboSubtask数据集,弥合了视觉基准和机器人控制之间的差距。
关键设计:在MS-TCN中,斐波那契扩张卷积的使用是关键设计之一,它允许网络在不同时间尺度上捕捉信息,从而更好地识别短时程动作转换。时间正则化项包括截断MSE损失和转换感知项,前者用于约束分割结果的平滑性,后者用于鼓励有效的子任务进展。复合损失函数的权重需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
RoboSubtaskNet在GTEA数据集上取得了F1 @ 50 = 79.5%,Edit = 88.6%,Acc = 78.9%的性能;在Breakfast数据集上取得了F1 @ 50 = 30.4%,Edit = 52.0%,Acc = 53.5%的性能;在RoboSubtask数据集上取得了F1 @ 50 = 94.2%,Edit = 95.6%,Acc = 92.2%的性能。此外,在7自由度Kinova Gen3机械臂上的实验表明,该方法能够实现可靠的端到端行为,总体任务成功率约为91.25%。
🎯 应用场景
该研究成果可应用于各种人机协作场景,如医疗辅助机器人、工业装配机器人、家庭服务机器人等。通过准确理解人类的动作意图,机器人可以更好地与人类协同工作,提高工作效率和安全性。未来,该技术有望进一步推广到更复杂的任务和环境中,实现更智能、更灵活的人机协作。
📄 摘要(原文)
Temporally locating and classifying fine-grained sub-task segments in long, untrimmed videos is crucial to safe human-robot collaboration. Unlike generic activity recognition, collaborative manipulation requires sub-task labels that are directly robot-executable. We present RoboSubtaskNet, a multi-stage human-to-robot sub-task segmentation framework that couples attention-enhanced I3D features (RGB plus optical flow) with a modified MS-TCN employing a Fibonacci dilation schedule to capture better short-horizon transitions such as reach-pick-place. The network is trained with a composite objective comprising cross-entropy and temporal regularizers (truncated MSE and a transition-aware term) to reduce over-segmentation and to encourage valid sub-task progressions. To close the gap between vision benchmarks and control, we introduce RoboSubtask, a dataset of healthcare and industrial demonstrations annotated at the sub-task level and designed for deterministic mapping to manipulator primitives. Empirically, RoboSubtaskNet outperforms MS-TCN and MS-TCN++ on GTEA and our RoboSubtask benchmark (boundary-sensitive and sequence metrics), while remaining competitive on the long-horizon Breakfast benchmark. Specifically, RoboSubtaskNet attains F1 @ 50 = 79.5%, Edit = 88.6%, Acc = 78.9% on GTEA; F1 @ 50 = 30.4%, Edit = 52.0%, Acc = 53.5% on Breakfast; and F1 @ 50 = 94.2%, Edit = 95.6%, Acc = 92.2% on RoboSubtask. We further validate the full perception-to-execution pipeline on a 7-DoF Kinova Gen3 manipulator, achieving reliable end-to-end behavior in physical trials (overall task success approx 91.25%). These results demonstrate a practical path from sub-task level video understanding to deployed robotic manipulation in real-world settings.