RoboInter: A Holistic Intermediate Representation Suite Towards Robotic Manipulation
作者: Hao Li, Ziqin Wang, Zi-han Ding, Shuai Yang, Yilun Chen, Yang Tian, Xiaolin Hu, Tai Wang, Dahua Lin, Feng Zhao, Si Liu, Jiangmiao Pang
分类: cs.RO
发布日期: 2026-02-10
备注: Published to ICLR 2026, 69 pages, 40 figures
💡 一句话要点
RoboInter:面向机器人操作的整体中间表示套件,提升VLA模型泛化性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作 中间表示 数据集 具身推理 VQA 先规划后执行
📋 核心要点
- 现有机器人操作数据集标注成本高、特定于机器人且缺乏多样性,限制了视觉-语言-动作(VLA)模型的泛化能力。
- RoboInter套件通过提供大规模、高质量的中间表示标注数据,以及相应的基准和模型,弥合了高层规划和低层执行之间的差距。
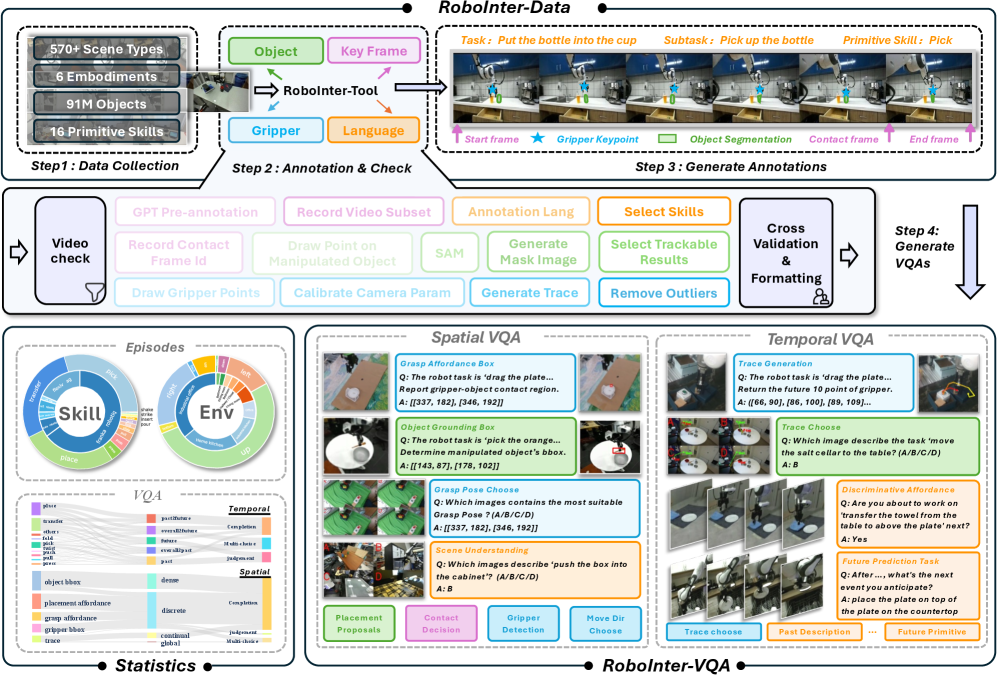
- RoboInter包含RoboInter-Tool、RoboInter-Data、RoboInter-VQA和RoboInter-VLA,为机器人操作学习提供全面支持。
📝 摘要(中文)
大型视觉语言模型(VLMs)的进步激发了人们对机器人操作的视觉-语言-动作(VLA)系统的兴趣。然而,现有的操作数据集的标注成本高昂,高度依赖具体机器人,并且覆盖范围和多样性不足,从而阻碍了VLA模型的泛化。最近的方法试图通过“先规划后执行”的范式来缓解这些限制,即首先生成高层规划(例如,子任务、轨迹),然后将其转换为低层动作,但它们严重依赖于额外的中间监督,而现有数据集中普遍缺乏这种监督。为了弥合这一差距,我们推出了RoboInter操作套件,这是一个统一的资源,包括用于操作的中间表示的数据、基准和模型。它包含RoboInter-Tool,一个轻量级GUI,可以半自动标注各种表示;以及RoboInter-Data,一个大规模数据集,包含跨571个不同场景的超过23万个episode,它提供了超过10个类别的中间表示的密集逐帧标注,在规模和标注质量上大大超过了之前的工作。在此基础上,RoboInter-VQA引入了9个空间和20个时间具身VQA类别,以系统地评估和增强VLM的具身推理能力。同时,RoboInter-VLA提供了一个集成的“先规划后执行”框架,支持模块化和端到端的VLA变体,通过中间监督将高层规划与低层执行连接起来。总而言之,RoboInter为通过细粒度和多样化的中间表示推进鲁棒和可泛化的机器人学习奠定了坚实的基础。
🔬 方法详解
问题定义:现有机器人操作数据集存在标注成本高、机器人特定性强、数据多样性不足等问题,导致VLA模型难以泛化到新的场景和任务。此外,现有方法依赖于额外的中间监督信息,而这些信息在现有数据集中往往缺失。
核心思路:RoboInter的核心思路是通过构建一个包含丰富中间表示标注的大规模数据集,以及相应的基准和工具,来促进VLA模型在高层规划和低层执行之间的学习。通过提供细粒度的中间监督,模型可以更好地理解任务目标,并生成更有效的操作策略。
技术框架:RoboInter套件包含四个主要组成部分:RoboInter-Tool(用于半自动标注中间表示的GUI工具)、RoboInter-Data(包含超过23万个episode的大规模数据集)、RoboInter-VQA(用于评估具身推理能力的VQA基准)和RoboInter-VLA(集成的“先规划后执行”框架)。RoboInter-VLA支持模块化和端到端的VLA变体,通过中间监督连接高层规划和低层执行。
关键创新:RoboInter的关键创新在于其对中间表示的全面性和规模。它提供了超过10个类别的中间表示的密集逐帧标注,包括子任务、轨迹、空间关系等,大大超过了之前的工作。此外,RoboInter还引入了新的VQA基准,用于评估VLM的具身推理能力。
关键设计:RoboInter-Tool采用轻量级GUI设计,方便用户进行半自动标注。RoboInter-Data数据集包含571个不同场景的23万个episode,保证了数据的多样性。RoboInter-VQA定义了9个空间和20个时间具身VQA类别,全面评估VLM的推理能力。RoboInter-VLA框架支持多种VLA模型,并提供中间监督,引导模型学习更有效的操作策略。
🖼️ 关键图片


📊 实验亮点
RoboInter-Data数据集包含超过23万个episode,覆盖571个不同场景,并提供了超过10个类别的中间表示的密集逐帧标注,在规模和标注质量上显著优于现有数据集。RoboInter-VQA引入了新的空间和时间具身VQA类别,为评估VLM的具身推理能力提供了新的基准。
🎯 应用场景
RoboInter可应用于各种机器人操作任务,例如家庭服务机器人、工业自动化机器人和医疗机器人。通过利用RoboInter提供的数据和工具,可以训练出更鲁棒、更通用的VLA模型,从而提高机器人在复杂环境中的操作能力,并降低开发成本。
📄 摘要(原文)
Advances in large vision-language models (VLMs) have stimulated growing interest in vision-language-action (VLA) systems for robot manipulation. However, existing manipulation datasets remain costly to curate, highly embodiment-specific, and insufficient in coverage and diversity, thereby hindering the generalization of VLA models. Recent approaches attempt to mitigate these limitations via a plan-then-execute paradigm, where high-level plans (e.g., subtasks, trace) are first generated and subsequently translated into low-level actions, but they critically rely on extra intermediate supervision, which is largely absent from existing datasets. To bridge this gap, we introduce the RoboInter Manipulation Suite, a unified resource including data, benchmarks, and models of intermediate representations for manipulation. It comprises RoboInter-Tool, a lightweight GUI that enables semi-automatic annotation of diverse representations, and RoboInter-Data, a large-scale dataset containing over 230k episodes across 571 diverse scenes, which provides dense per-frame annotations over more than 10 categories of intermediate representations, substantially exceeding prior work in scale and annotation quality. Building upon this foundation, RoboInter-VQA introduces 9 spatial and 20 temporal embodied VQA categories to systematically benchmark and enhance the embodied reasoning capabilities of VLMs. Meanwhile, RoboInter-VLA offers an integrated plan-then-execute framework, supporting modular and end-to-end VLA variants that bridge high-level planning with low-level execution via intermediate supervision. In total, RoboInter establishes a practical foundation for advancing robust and generalizable robotic learning via fine-grained and diverse intermediate representations.