Instruct2Act: From Human Instruction to Actions Sequencing and Execution via Robot Action Network for Robotic Manipulation
作者: Archit Sharma, Dharmendra Sharma, John Rebeiro, Peeyush Thakur, Narendra Dhar, Laxmidhar Behera
分类: cs.RO, cs.AI
发布日期: 2026-02-10
💡 一句话要点
Instruct2Act:通过机器人动作网络实现从人类指令到机器人操作的动作序列生成与执行
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 自然语言指令 动作序列生成 轨迹规划 深度学习 视觉引导 BiLSTM 多头注意力
📋 核心要点
- 现有机器人难以理解和执行自然语言指令,尤其是在计算资源和感知能力有限的现实环境中。
- Instruct2Act提出了一种轻量级、端到端的解决方案,将自然语言指令解析为可执行的机器人动作序列,并生成精确的控制轨迹。
- 实验结果表明,该方法在多个操作任务中取得了90%的成功率,且推理速度快,可在资源受限的设备上实时运行。
📝 摘要(中文)
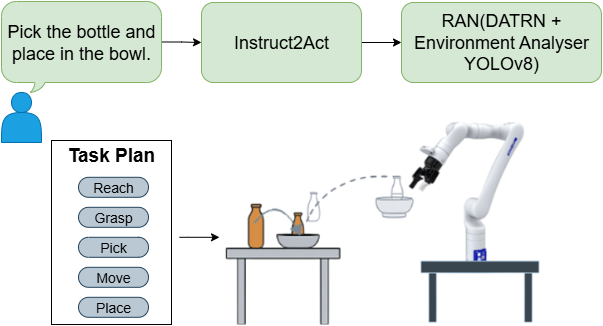
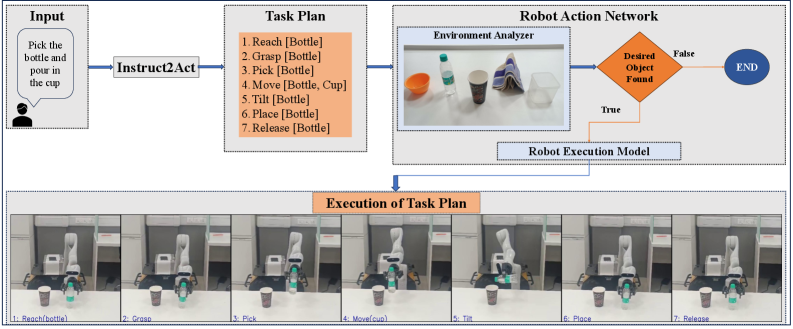
由于计算和感知的限制,机器人通常难以在现实环境中遵循自由形式的人类指令。本文提出了一种轻量级的、完全在设备上运行的流程,将自然语言命令转换为可靠的机械操作。该方法分为两个阶段:(i)指令到动作模块(Instruct2Act),这是一个紧凑的BiLSTM,带有多头注意力自编码器,用于将指令解析为原子动作的有序序列(例如,到达、抓取、移动、放置);(ii)机器人动作网络(RAN),它使用动态自适应轨迹径向网络(DATRN)以及基于视觉的环境分析器(YOLOv8)来为每个子动作生成精确的控制轨迹。整个系统在配置一般的设备上运行,无需云服务。在自定义数据集上,Instruct2Act实现了91.5%的子动作预测准确率,同时保持了较小的模型体积。在四个任务(拾取放置、拾取倾倒、擦拭和拾取给予)上的真实机器人评估产生了90%的总体成功率;子动作推理在<3.8秒内完成,端到端执行时间在30-60秒之间,具体取决于任务的复杂性。这些结果表明,细粒度的指令到动作解析,结合基于DATRN的轨迹生成和视觉引导的定位,为资源受限的单摄像头环境中确定性的实时操作提供了一条可行的途径。
🔬 方法详解
问题定义:现有机器人操作方法难以直接理解和执行人类的自然语言指令,尤其是在计算资源有限的场景下。现有的方法通常依赖于复杂的云服务或需要大量的数据进行训练,难以在实际应用中部署。此外,感知噪声和环境变化也会影响机器人操作的可靠性。
核心思路:Instruct2Act的核心思路是将自然语言指令分解为一系列原子动作,然后利用机器人动作网络(RAN)生成每个动作的精确控制轨迹。通过细粒度的指令解析和视觉引导的定位,该方法能够在资源受限的环境中实现确定性的实时操作。
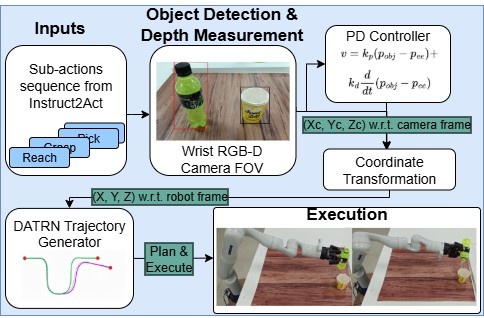
技术框架:Instruct2Act包含两个主要模块:指令到动作模块(Instruct2Act)和机器人动作网络(RAN)。Instruct2Act模块使用BiLSTM和多头注意力自编码器将自然语言指令解析为原子动作序列。RAN模块使用动态自适应轨迹径向网络(DATRN)和YOLOv8进行环境分析,并为每个子动作生成精确的控制轨迹。整个系统在本地设备上运行,无需云服务。
关键创新:该方法的主要创新点在于:(1) 提出了一种轻量级的、完全在设备上运行的指令到动作解析流程;(2) 结合了BiLSTM和多头注意力自编码器,实现了对自然语言指令的细粒度解析;(3) 利用DATRN和YOLOv8实现了视觉引导的精确轨迹生成。与现有方法相比,Instruct2Act能够在资源受限的环境中实现更可靠、更实时的机器人操作。
关键设计:Instruct2Act模块使用BiLSTM进行序列编码,并使用多头注意力机制来关注指令中的关键信息。DATRN网络使用径向基函数来逼近最优轨迹,并通过动态调整基函数的位置和宽度来适应不同的环境和任务。YOLOv8用于检测环境中的物体,并为轨迹生成提供视觉引导。损失函数包括动作预测损失和轨迹优化损失,用于训练Instruct2Act和RAN模块。
🖼️ 关键图片
📊 实验亮点
Instruct2Act在自定义数据集上实现了91.5%的子动作预测准确率。在四个真实机器人任务(拾取放置、拾取倾倒、擦拭和拾取给予)上的评估中,总体成功率达到90%。子动作推理时间小于3.8秒,端到端执行时间在30-60秒之间,表明该方法具有良好的实时性和可靠性。
🎯 应用场景
Instruct2Act技术可应用于家庭服务机器人、工业自动化、医疗辅助等领域。该技术能够使机器人更好地理解和执行人类指令,从而提高机器人的智能化水平和服务能力。在资源受限的环境中,Instruct2Act的轻量级设计使其具有更广泛的应用前景,例如在移动机器人和嵌入式系统中部署。
📄 摘要(原文)
Robots often struggle to follow free-form human instructions in real-world settings due to computational and sensing limitations. We address this gap with a lightweight, fully on-device pipeline that converts natural-language commands into reliable manipulation. Our approach has two stages: (i) the instruction to actions module (Instruct2Act), a compact BiLSTM with a multi-head-attention autoencoder that parses an instruction into an ordered sequence of atomic actions (e.g., reach, grasp, move, place); and (ii) the robot action network (RAN), which uses the dynamic adaptive trajectory radial network (DATRN) together with a vision-based environment analyzer (YOLOv8) to generate precise control trajectories for each sub-action. The entire system runs on a modest system with no cloud services. On our custom proprietary dataset, Instruct2Act attains 91.5% sub-actions prediction accuracy while retaining a small footprint. Real-robot evaluations across four tasks (pick-place, pick-pour, wipe, and pick-give) yield an overall 90% success; sub-action inference completes in < 3.8s, with end-to-end executions in 30-60s depending on task complexity. These results demonstrate that fine-grained instruction-to-action parsing, coupled with DATRN-based trajectory generation and vision-guided grounding, provides a practical path to deterministic, real-time manipulation in resource-constrained, single-camera settings.