Diverse Skill Discovery for Quadruped Robots via Unsupervised Learning
作者: Ruopeng Cui, Yifei Bi, Haojie Luo, Wei Li
分类: cs.RO
发布日期: 2026-02-10
💡 一句话要点
提出正交混合专家与多判别器框架,提升四足机器人无监督技能发现的多样性与效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 无监督学习 技能发现 正交混合专家 多判别器 强化学习 运动控制
📋 核心要点
- 现有无监督技能发现方法依赖单一策略,忽略了技能间的结构差异,导致学习效率低,且易受奖励黑客攻击。
- 提出正交混合专家(OMoE)架构,避免行为表示坍缩,并设计多判别器框架,在不同观察空间操作,缓解奖励黑客。
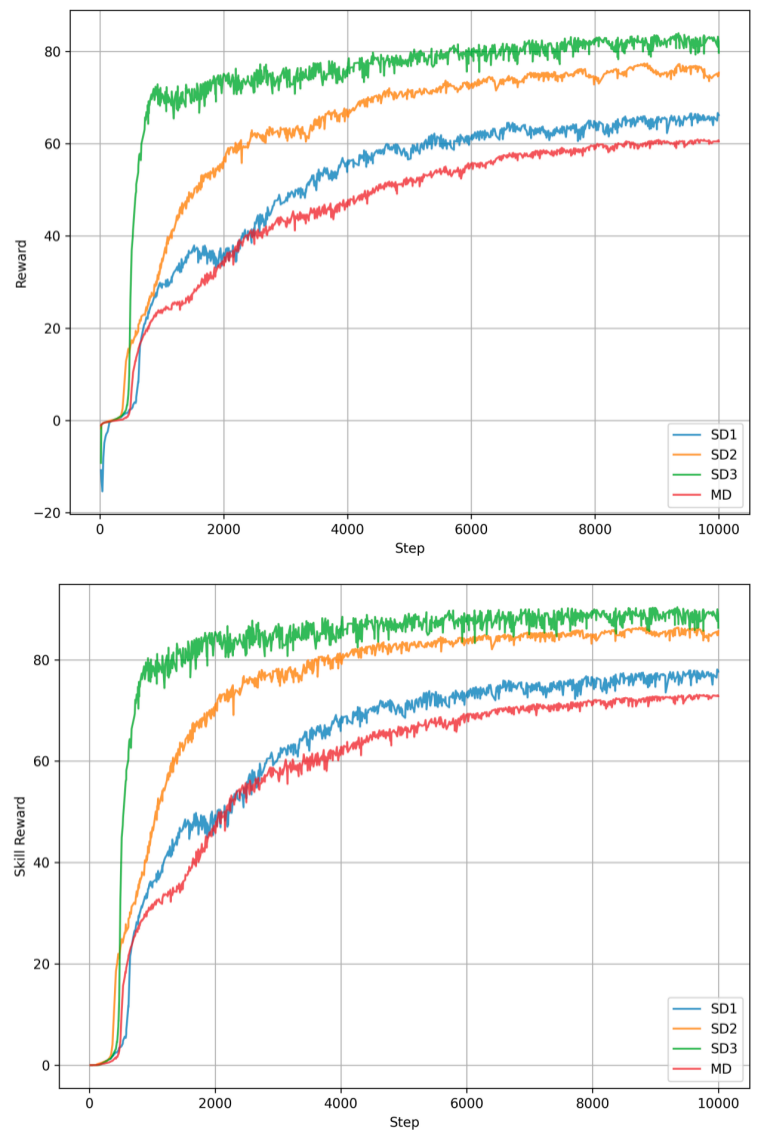
- 在宇树A1四足机器人上的实验表明,该框架提高了训练效率,状态空间覆盖率比基线提高了18.3%。
📝 摘要(中文)
强化学习需要专家精心设计的奖励函数来引导目标行为,而模仿学习则依赖于昂贵的特定任务数据。相比之下,无监督技能发现可以通过内在动机驱动学习各种有用的技能,从而潜在地减轻这些负担。然而,现有方法存在两个主要限制:它们通常依赖于单一策略来掌握多种行为,而没有对行为之间的共享结构或区别进行建模,导致学习效率低下;此外,它们容易受到奖励黑客的影响,奖励信号迅速增加和收敛,而学习到的技能表现出不足的实际多样性。本文提出了一种正交混合专家(OMoE)架构,防止多样化的行为坍缩为重叠的表示,使单个策略能够掌握广泛的运动技能。此外,我们设计了一个多判别器框架,其中不同的判别器在不同的观察空间上运行,有效地缓解了奖励黑客问题。我们在12自由度的宇树A1四足机器人上评估了我们的方法,展示了一组多样化的运动技能。实验表明,所提出的框架提高了训练效率,并与基线相比,状态空间覆盖率扩大了18.3%。
🔬 方法详解
问题定义:现有的无监督技能发现方法在四足机器人上存在两个主要问题。一是学习效率低下,因为它们通常使用单一策略来掌握各种行为,而没有对这些行为之间的共享结构或区别进行建模。二是容易受到奖励黑客的影响,即奖励信号迅速增加和收敛,但学习到的技能并没有表现出足够的实际多样性。这意味着机器人可能学会了“作弊”的方式来获得高奖励,而不是真正掌握了不同的运动技能。
核心思路:本文的核心思路是通过引入正交混合专家(OMoE)架构和多判别器框架来解决上述问题。OMoE架构旨在防止不同的行为坍缩为重叠的表示,从而使单个策略能够掌握更广泛的运动技能。多判别器框架则通过在不同的观察空间上操作不同的判别器来缓解奖励黑客问题,迫使机器人学习真正多样化的技能。
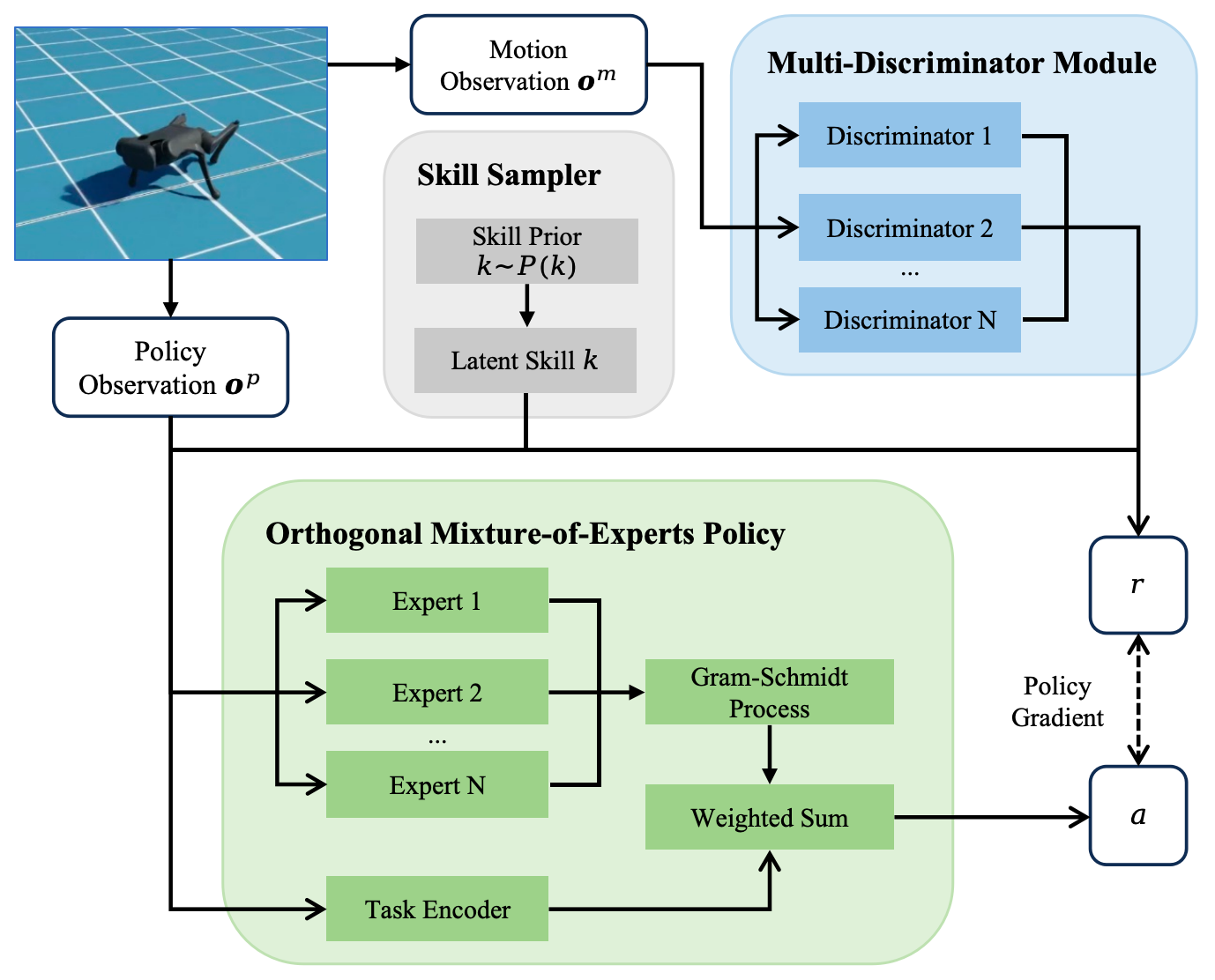
技术框架:该方法的技术框架主要包括两个关键组件:正交混合专家(OMoE)策略网络和多判别器奖励函数。OMoE策略网络由多个专家网络组成,每个专家网络负责学习一种特定的技能。通过正交约束,确保不同的专家网络学习到的技能具有差异性。多判别器奖励函数由多个判别器组成,每个判别器在不同的观察空间上评估机器人的行为。通过这种方式,可以有效地防止奖励黑客,并鼓励机器人学习真正多样化的技能。
关键创新:该论文的关键创新在于提出了正交混合专家(OMoE)架构和多判别器框架。OMoE架构通过正交约束来保证不同专家网络学习到的技能具有差异性,从而提高了技能的多样性。多判别器框架通过在不同的观察空间上操作不同的判别器来缓解奖励黑客问题,从而提高了学习的稳定性和可靠性。与现有方法相比,该方法能够学习到更广泛、更真实的运动技能。
关键设计:OMoE架构的关键设计在于正交约束,它通过最小化不同专家网络输出之间的相关性来保证技能的差异性。多判别器框架的关键设计在于选择合适的观察空间,例如关节角度、足端位置等,以及设计合适的判别器网络结构,例如卷积神经网络、循环神经网络等。损失函数包括策略梯度损失、正交约束损失和判别器损失。具体参数设置需要根据实际任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的框架显著提高了四足机器人的训练效率和技能多样性。与基线方法相比,该方法的状态空间覆盖率提高了18.3%,表明机器人能够探索更广泛的状态空间,学习到更多样化的运动技能。此外,该方法还能够有效地缓解奖励黑客问题,保证学习到的技能具有实际意义。
🎯 应用场景
该研究成果可应用于各种四足机器人应用场景,例如搜救、巡检、物流等。通过学习多样化的运动技能,四足机器人可以更好地适应复杂环境,完成各种任务。此外,该方法还可以推广到其他类型的机器人,例如人形机器人、轮式机器人等,从而提高机器人的自主性和适应性。
📄 摘要(原文)
Reinforcement learning necessitates meticulous reward shaping by specialists to elicit target behaviors, while imitation learning relies on costly task-specific data. In contrast, unsupervised skill discovery can potentially reduce these burdens by learning a diverse repertoire of useful skills driven by intrinsic motivation. However, existing methods exhibit two key limitations: they typically rely on a single policy to master a versatile repertoire of behaviors without modeling the shared structure or distinctions among them, which results in low learning efficiency; moreover, they are susceptible to reward hacking, where the reward signal increases and converges rapidly while the learned skills display insufficient actual diversity. In this work, we introduce an Orthogonal Mixture-of-Experts (OMoE) architecture that prevents diverse behaviors from collapsing into overlapping representations, enabling a single policy to master a wide spectrum of locomotion skills. In addition, we design a multi-discriminator framework in which different discriminators operate on distinct observation spaces, effectively mitigating reward hacking. We evaluated our method on the 12-DOF Unitree A1 quadruped robot, demonstrating a diverse set of locomotion skills. Our experiments demonstrate that the proposed framework boosts training efficiency and yields an 18.3\% expansion in state-space coverage compared to the baseline.