NavDreamer: Video Models as Zero-Shot 3D Navigators
作者: Xijie Huang, Weiqi Gai, Tianyue Wu, Congyu Wang, Zhiyang Liu, Xin Zhou, Yuze Wu, Fei Gao
分类: cs.RO
发布日期: 2026-02-10
备注: Work in the progress. 22 pages, 15 figures
💡 一句话要点
NavDreamer:利用视频模型实现零样本3D导航
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D导航 视频模型 零样本学习 视觉语言模型 机器人 轨迹规划 逆动力学
📋 核心要点
- 现有视觉-语言-动作模型在导航任务中面临数据稀缺和泛化性差的挑战。
- NavDreamer利用生成视频模型作为通用接口,将语言指令转化为导航轨迹,实现零样本泛化。
- 实验表明,NavDreamer在多种导航任务中表现出强大的泛化能力,尤其适合基于视频的规划。
📝 摘要(中文)
现有的视觉-语言-动作模型在导航方面面临严峻的限制:数据稀缺、多样性不足,且数据收集劳动密集;静态表示无法捕捉时间动态和物理规律。我们提出了NavDreamer,一个基于视频的3D导航框架,它利用生成视频模型作为语言指令和导航轨迹之间的通用接口。我们的主要假设是,视频编码时空信息和物理动态的能力,结合互联网规模的可获取性,能够实现强大的零样本导航泛化。为了减轻生成预测的随机性,我们引入了一种基于采样的优化方法,该方法利用VLM进行轨迹评分和选择。采用逆动力学模型从生成的视频计划中解码可执行的航点以进行导航。为了系统地评估这种范式在多个视频模型骨干网络中的表现,我们引入了一个全面的基准,涵盖了物体导航、精确导航、空间定位、语言控制和场景推理。大量的实验证明了在新的物体和未见环境中的鲁棒泛化能力,消融研究表明导航的高级决策特性使其特别适合基于视频的规划。
🔬 方法详解
问题定义:现有视觉-语言-动作模型在3D导航任务中面临数据收集困难、成本高昂的问题,并且难以捕捉环境中的时序动态和物理规律,导致泛化能力不足。这些模型通常依赖于静态的场景表示,无法有效地进行长期规划和决策。
核心思路:NavDreamer的核心思路是利用生成视频模型来桥接语言指令和导航轨迹。视频模型能够编码丰富的时空信息和物理动态,并且可以从互联网上获取大规模数据,从而实现更好的零样本泛化能力。通过生成未来场景的视频,模型可以预测导航过程中的状态变化,并据此规划最优轨迹。
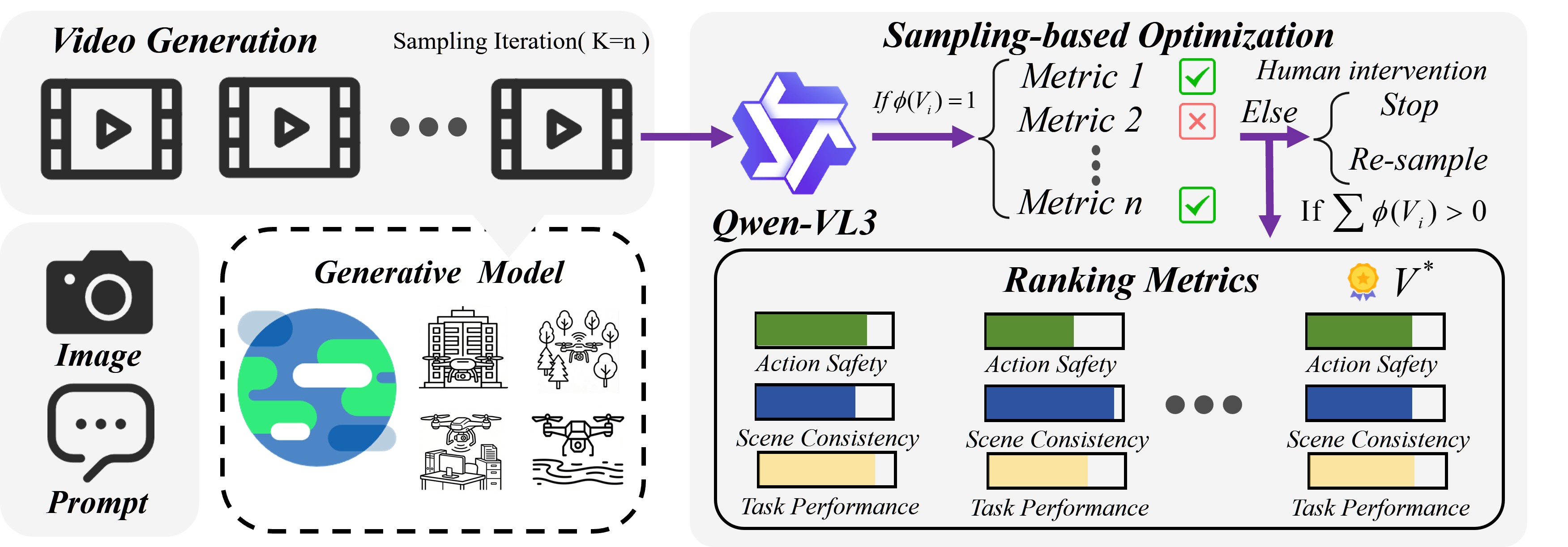
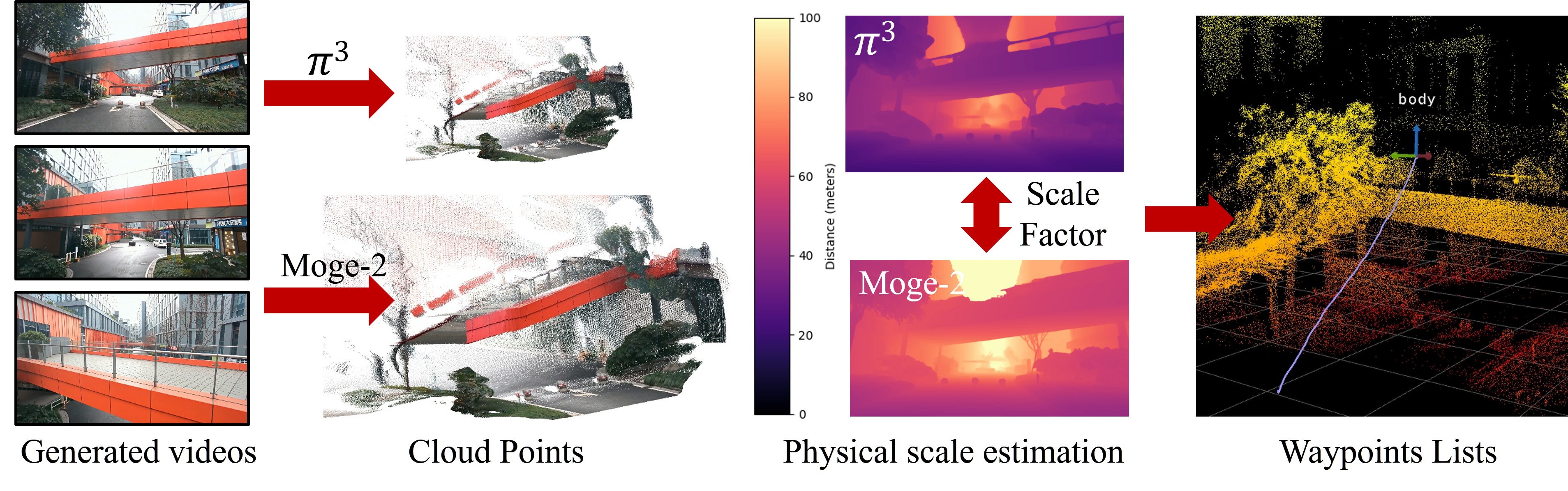
技术框架:NavDreamer框架主要包含三个模块:视频生成模型、轨迹优化模块和逆动力学模型。首先,给定语言指令,视频生成模型预测未来场景的视频序列。然后,轨迹优化模块利用视觉-语言模型(VLM)对生成的视频轨迹进行评分和选择,以缓解生成过程中的随机性。最后,逆动力学模型将选定的视频轨迹解码为可执行的航点,用于控制导航代理的运动。
关键创新:NavDreamer的关键创新在于将生成视频模型引入到3D导航任务中,并将其作为语言指令和导航轨迹之间的通用接口。这种方法能够有效地利用视频数据中蕴含的时空信息和物理动态,从而实现强大的零样本泛化能力。此外,基于采样的轨迹优化方法和逆动力学模型的应用也为导航任务提供了新的思路。
关键设计:轨迹优化模块采用基于采样的优化方法,通过VLM对生成的多个视频轨迹进行评分,并选择得分最高的轨迹。逆动力学模型的设计需要根据具体的机器人平台进行调整,以确保能够准确地将视频轨迹转换为可执行的航点。损失函数的设计需要考虑视频生成的质量、轨迹的平滑性和与语言指令的一致性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,NavDreamer在物体导航、精确导航、空间定位、语言控制和场景推理等多个任务上都取得了显著的成果。该方法在新的物体和未见环境中表现出强大的泛化能力,证明了基于视频的规划在导航任务中的有效性。消融研究进一步验证了导航的高级决策特性使其特别适合基于视频的规划。
🎯 应用场景
NavDreamer具有广泛的应用前景,例如在家庭服务机器人、自动驾驶、虚拟现实等领域。它可以帮助机器人在未知环境中自主导航,完成各种任务,例如物体搜索、环境探索等。该研究为开发更智能、更通用的导航系统提供了新的思路,并有望推动机器人技术的进一步发展。
📄 摘要(原文)
Previous Vision-Language-Action models face critical limitations in navigation: scarce, diverse data from labor-intensive collection and static representations that fail to capture temporal dynamics and physical laws. We propose NavDreamer, a video-based framework for 3D navigation that leverages generative video models as a universal interface between language instructions and navigation trajectories. Our main hypothesis is that video's ability to encode spatiotemporal information and physical dynamics, combined with internet-scale availability, enables strong zero-shot generalization in navigation. To mitigate the stochasticity of generative predictions, we introduce a sampling-based optimization method that utilizes a VLM for trajectory scoring and selection. An inverse dynamics model is employed to decode executable waypoints from generated video plans for navigation. To systematically evaluate this paradigm in several video model backbones, we introduce a comprehensive benchmark covering object navigation, precise navigation, spatial grounding, language control, and scene reasoning. Extensive experiments demonstrate robust generalization across novel objects and unseen environments, with ablation studies revealing that navigation's high-level decision-making nature makes it particularly suited for video-based planning.