AutoFly: Vision-Language-Action Model for UAV Autonomous Navigation in the Wild
作者: Xiaolou Sun, Wufei Si, Wenhui Ni, Yuntian Li, Dongming Wu, Fei Xie, Runwei Guan, He-Yang Xu, Henghui Ding, Yuan Wu, Yutao Yue, Yongming Huang, Hui Xiong
分类: cs.RO
发布日期: 2026-02-10
备注: Acceped by ICLR 2026
💡 一句话要点
AutoFly:面向野外无人机自主导航的视觉-语言-动作模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机自主导航 视觉-语言导航 深度估计 端到端学习 自主行为建模
📋 核心要点
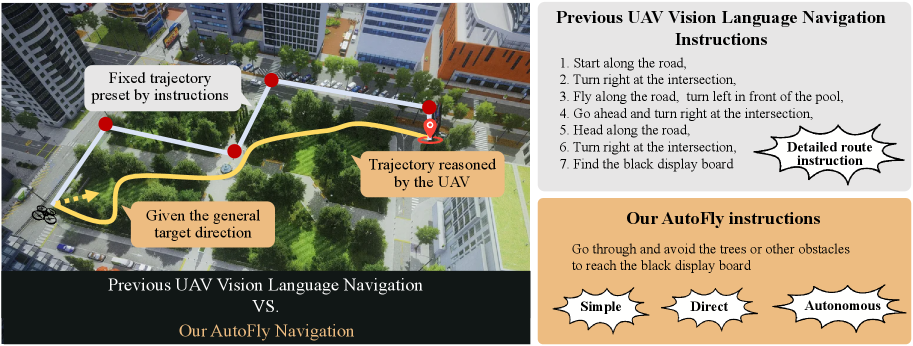
- 现有无人机视觉-语言导航依赖详细指令,难以应对真实野外环境粗粒度指令下的自主导航挑战。
- AutoFly提出端到端视觉-语言-动作模型,结合伪深度编码器和渐进式训练,提升空间推理和策略对齐。
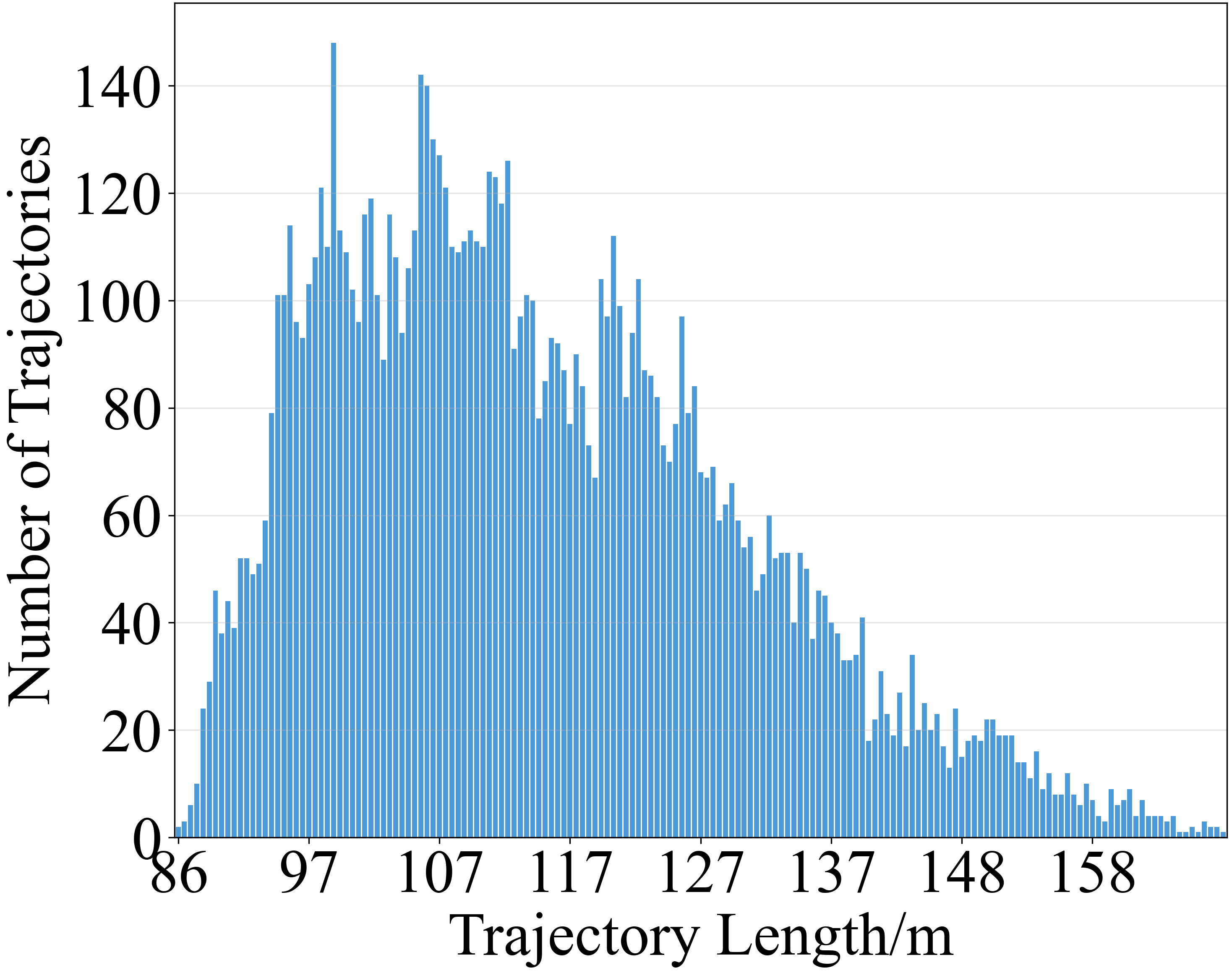
- 构建新的自主导航数据集,强调自主决策和真实数据,实验表明AutoFly成功率提升3.9%。
📝 摘要(中文)
视觉-语言导航(VLN)要求智能体通过解释语言指令和视觉观察来导航环境,是具身智能的基石任务。目前无人机(UAV)的VLN研究依赖于详细的预先指定的指令来引导无人机沿着预定的路线飞行。然而,现实世界的户外探索通常发生在未知的环境中,无法提供详细的导航指令,只能提供粗略的位置或方向指导,这需要无人机自主地进行连续规划和避障。为了弥合这一差距,我们提出了AutoFly,一个用于自主无人机导航的端到端视觉-语言-动作(VLA)模型。AutoFly结合了一个伪深度编码器,该编码器从RGB输入中导出深度感知特征以增强空间推理,并结合渐进式两阶段训练策略,有效地将视觉、深度和语言表示与动作策略对齐。此外,现有的VLN数据集对于现实世界的自主导航存在根本性的局限性,因为它们过度依赖于显式的指令跟随,而不是自主决策和缺乏足够的真实世界数据。为了解决这些问题,我们构建了一个新的自主导航数据集,该数据集通过以下方式将范式从指令跟随转变为自主行为建模:(1)强调连续避障、自主规划和识别工作流程的轨迹收集;(2)全面的真实世界数据集成。实验结果表明,与最先进的VLA基线相比,AutoFly的成功率提高了3.9%,并且在模拟和真实环境中都具有一致的性能。
🔬 方法详解
问题定义:现有无人机视觉-语言导航(VLN)方法依赖于详细的、预先指定的指令,这在模拟环境中表现良好。然而,在真实的野外环境中,通常只能获得粗略的位置或方向指导,缺乏详细的导航指令。因此,无人机需要具备自主规划和避障的能力,而现有方法难以满足这种需求。现有数据集也侧重于指令跟随,缺乏对自主行为的建模和真实世界数据的支持。
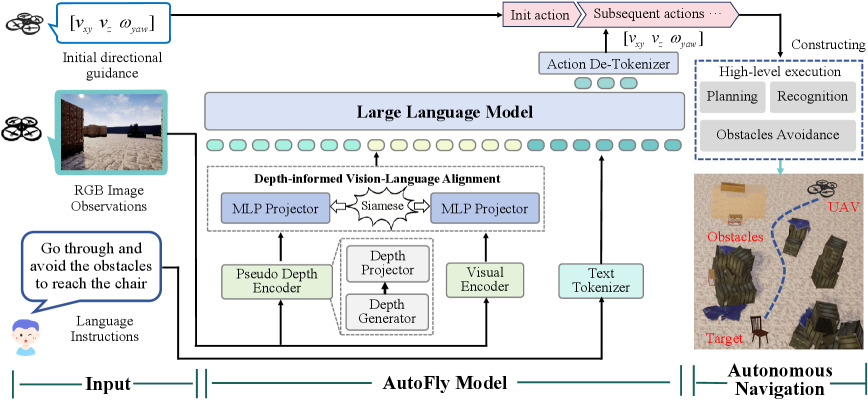
核心思路:AutoFly的核心思路是构建一个端到端的视觉-语言-动作(VLA)模型,使无人机能够直接从视觉输入和粗粒度的语言指令中学习自主导航策略。通过引入伪深度编码器增强空间推理能力,并采用渐进式两阶段训练策略来对齐视觉、深度和语言表示与动作策略。同时,构建新的数据集来弥补现有数据集的不足,从而更好地模拟真实世界的自主导航场景。
技术框架:AutoFly的整体框架包含以下几个主要模块:1) 视觉编码器:使用卷积神经网络(CNN)提取视觉特征。2) 伪深度编码器:从RGB图像中估计深度信息,并提取深度特征,以增强空间推理能力。3) 语言编码器:使用循环神经网络(RNN)或Transformer对语言指令进行编码。4) 融合模块:将视觉特征、深度特征和语言特征进行融合,得到多模态表示。5) 动作预测模块:根据多模态表示预测无人机的动作,例如前进、左转、右转等。整个流程是端到端可训练的。
关键创新:AutoFly的关键创新点在于:1) 提出了伪深度编码器,从RGB图像中提取深度信息,增强了无人机的空间推理能力。2) 采用了渐进式两阶段训练策略,有效地对齐了视觉、深度和语言表示与动作策略。3) 构建了一个新的自主导航数据集,该数据集更侧重于自主行为建模和真实世界数据,更符合实际应用场景。与现有方法相比,AutoFly更注重自主决策,而不是简单的指令跟随。
关键设计:伪深度编码器使用了预训练的深度估计模型,例如DPT (Dense Prediction Transformers)。渐进式两阶段训练策略包括:第一阶段,使用模拟数据进行预训练,学习基本的导航策略;第二阶段,使用真实世界数据进行微调,提高模型的泛化能力。损失函数包括动作预测的交叉熵损失和深度估计的均方误差损失。网络结构方面,视觉编码器可以使用ResNet等常用网络,语言编码器可以使用LSTM或Transformer。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AutoFly在自主导航任务中取得了显著的性能提升。与最先进的VLA基线相比,AutoFly的成功率提高了3.9%,并且在模拟和真实环境中都表现出一致的性能。这验证了AutoFly在复杂环境下的自主导航能力。
🎯 应用场景
AutoFly可应用于多种无人机自主导航场景,如灾害救援、环境监测、农业巡检、物流配送等。该研究有助于提升无人机在复杂未知环境下的自主作业能力,降低对人工干预的依赖,提高作业效率和安全性,具有广阔的应用前景。
📄 摘要(原文)
Vision-language navigation (VLN) requires intelligent agents to navigate environments by interpreting linguistic instructions alongside visual observations, serving as a cornerstone task in Embodied AI. Current VLN research for unmanned aerial vehicles (UAVs) relies on detailed, pre-specified instructions to guide the UAV along predetermined routes. However, real-world outdoor exploration typically occurs in unknown environments where detailed navigation instructions are unavailable. Instead, only coarse-grained positional or directional guidance can be provided, requiring UAVs to autonomously navigate through continuous planning and obstacle avoidance. To bridge this gap, we propose AutoFly, an end-to-end Vision-Language-Action (VLA) model for autonomous UAV navigation. AutoFly incorporates a pseudo-depth encoder that derives depth-aware features from RGB inputs to enhance spatial reasoning, coupled with a progressive two-stage training strategy that effectively aligns visual, depth, and linguistic representations with action policies. Moreover, existing VLN datasets have fundamental limitations for real-world autonomous navigation, stemming from their heavy reliance on explicit instruction-following over autonomous decision-making and insufficient real-world data. To address these issues, we construct a novel autonomous navigation dataset that shifts the paradigm from instruction-following to autonomous behavior modeling through: (1) trajectory collection emphasizing continuous obstacle avoidance, autonomous planning, and recognition workflows; (2) comprehensive real-world data integration. Experimental results demonstrate that AutoFly achieves a 3.9% higher success rate compared to state-of-the-art VLA baselines, with consistent performance across simulated and real environments.